Win10 下 hadoop3.0.0 单机部署
前言
因近期要做 hadoop 有关的项目,需配置 hadoop 环境,简单起见就准备进行单机部署,方便开发调试。顺便记录下采坑步骤,方便碰到同样问题的朋友们。
安装步骤
一、下载 hadoop-XXX.tar.gz
下载地址:http://archive.apache.org/dist/hadoop/core/

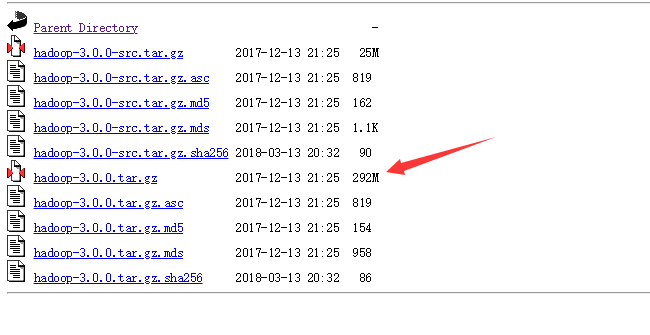
将文件解压至无空格目录下,好像时间有那么点点久。。。。。
注:解压需管理员权限!!!
添加环境变量
添加HADOOP_HOME配置
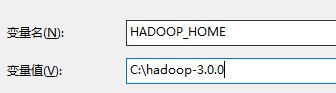
在 path 中添加 bin 目录 C:\hadoop-3.0.0\bin
JAVA_HOME
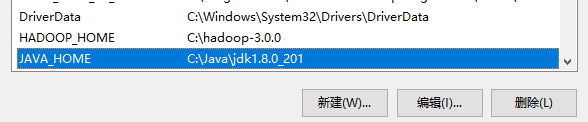
二、hadoop配置
1、修改C:/hadoop-3.0.0/etc/hadoop/core-site.xml配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/C:/hadoop-3.0.0/data/tmp</value>
</property>
</configuration>
2、修改C:/hadoop-3.0.0/etc/hadoop/mapred-site.xml配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
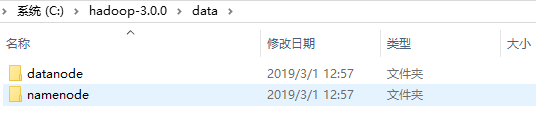
3、在C:/hadoop-3.0.0目录下创建data目录,作为数据存储路径:
- 在D:/hadoop-3.0.0/data目录下创建datanode目录;
- 在D:/hadoop-3.0.0/data目录下创建namenode目录;
4、修改C:/hadoop-3.0.0/etc/hadoop/hdfs-site.xml配置:
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/C:/hadoop-3.0./data/namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/C:/hadoop-3.0./data/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/C:/hadoop-3.0./data/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/C:/hadoop-3.0./data/datanode</value>
</property>
</configuration>
5、修改C:/hadoop-3.0.0/etc/hadoop/yarn-site.xml配置:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6、修改C:/hadoop-3.0.0/etc/hadoop/hadoop-env.cmd配置,添加
set JAVA_HOME=%JAVA_HOME% set HADOOP_PREFIX=%HADOOP_HOME% set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
7、bin目录替换
至https://github.com/steveloughran/winutils下载解压,然后找到对应的版本后完整替换bin目录即可
至此,我们的配置就完成了
三、启动服务
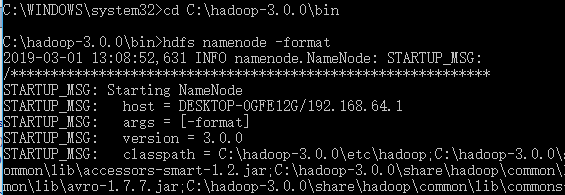
1、打开cmd
cd C:\hadoop-3.0.\bin hdfs namenode -format
2、通过start-all.cmd启动服务:
C:\hadoop-3.0.\sbin\start-all.cmd
然后可以看到同时打开了4个cmd窗口
- Hadoop Namenode
- Hadoop datanode
- YARN Resourc Manager
- YARN Node Manager

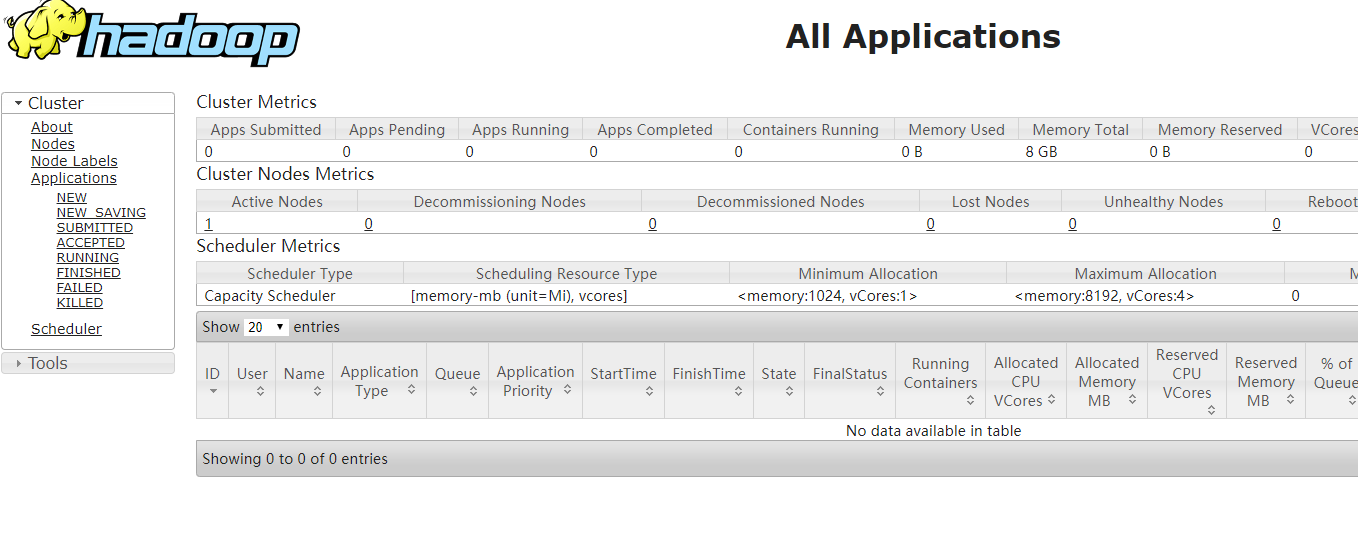
通过http://127.0.0.1:8088/即可查看集群所有节点状态:
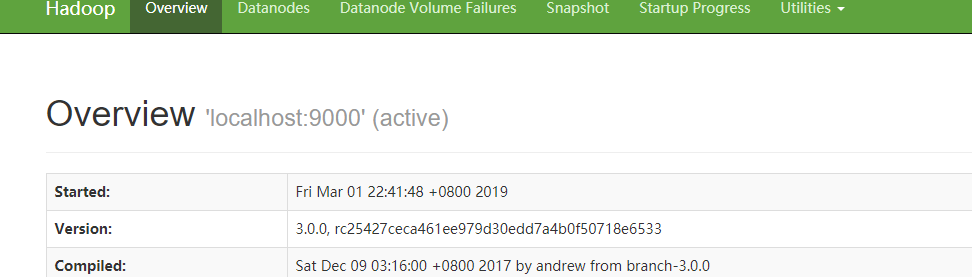
 访问http://localhost:9870/即可查看文件管理页面:
访问http://localhost:9870/即可查看文件管理页面:
总结
一次还算比较顺利的采坑,后面准备开始肝项目了 orz。。。
Win10 下 hadoop3.0.0 单机部署的更多相关文章
- win10 下的 CUDA10.0 +CUDNN + tensorflow + opencv 环境部署
1 CUDA 10.0 安装 win10 下的cuda 安装是非常简单的,和其他程序安装没什么区别,现在 tensorflow 1.13 版本以上 支持 CUDA 10.0 ,这里选取了CUDA 1 ...
- win10下MYSQL 8.0.16的下载、安装以及配置
win10系统MySQL 8.0的下载安装超详细教程 https://blog.csdn.net/qq_34444097/article/details/82315587 下载安装配置链接:https ...
- win10 下springcloud打包docker镜像部署。
1:建一个最简单的springcloud应用. 2:在根目录下新建dockerfile,文件如下: FROM openjdk:8-jdk-alpine VOLUME /tmp ARG JAR_FILE ...
- win10下vc++6.0的安装问题
由于最近需要在win10系统下用到vc++来编程(其实刚开始我是拒绝的,因为vc++各种坑),下面我就把安装vc++时遇到的问题记录下来,方便以后同样遇到这些问题的同学. 安装vc++6.0所需要东西 ...
- win10 下cuda 9.0 卸载
1.首先 对于cuda8.0.cuda7.5的卸载都可以兼容 安装cuda9.0之后,电脑原来的NVIDIA图形驱动会被更新,NVIDIA Physx系统软件也会被更新(安装低版cuda可能不会被更新 ...
- 解决win10下MySQL 8.0登录Access denied for user 'root'@'localhost' (using password: YES)的问题
近些时间在开始学MySQL,安装挺顺利的,按照网上现成的教程就能安装成功. 但是,在输入 mysql -uroot -p 再输入密码时,遇到了这个情况 Access denie ...
- Windows下安装CUDA8.0
在Win10下安装CUDA8.0,并使用VS2013测试: 机器配置: Windows 10 VS 2013 CUDA8.0 CUDA 8.0:下载地址 CUDA其他版本:下载地址 1. 安装CUDA ...
- Hadoop系列之(一):Hadoop单机部署
1. Hadoop介绍 Hadoop是一个能够对海量数据进行分布式处理的系统架构. Hadoop框架的核心是:HDFS和MapReduce. HDFS分布式文件系统为海量的数据提供了存储, MapRe ...
- Win10下Tensorflow+GPU的环境配置
不得不说,想要为深度学习提前打好框架确实需要花费一番功夫.本文主要记录了Win10下,Cuda9.0.Cudnn7.3.1.Tensorflow-gpu1.13.1.python3.6.8.Keras ...
随机推荐
- mysql 语句 GROUP_CONCAT
select * from blog_log;+----+---------------------+-------+--------+| id | time | level | info |+--- ...
- 从前端和后端两个角度分析jsonp跨域访问(完整实例)
一.什么是跨域访问 举个栗子:在A网站中,我们希望使用Ajax来获得B网站中的特定内容.如果A网站与B网站不在同一个域中,那么就出现了跨域访问问题.你可以理解为两个域名之间不能跨过域名来发送请求或者请 ...
- 【CTF WEB】ISCC 2016 web 2题记录
偶然看到的比赛,我等渣渣跟风做两题,剩下的题目工作太忙没有时间继续做. 第1题 sql注入: 题目知识 考察sql注入知识,题目地址:http://101.200.145.44/web1//ind ...
- C语言练手游戏-控制台输出一个会移动的坦克
把C语言的知识融合起来做一个练手的小游戏项目,将自己掌握到的数据结构.数组.函数.宏定义等知识综合利用,增加对语法的熟练程度. 操作系统: windows 10 x64 编译IDE : VS2015 ...
- /etc/my.cnf
[client] default-character-set=utf8 [mysqld] tmp_table_size = 2048M max_heap_table_size = 2048M max_ ...
- Linux内核中_IO,_IOR,_IOW,_IOWR宏的用法与解析【转】
转自:http://blog.csdn.net/hzn407487204/article/details/7995041 在驱动程序里, ioctl() 函数上传送的变量 cmd 是应用程序用于区别设 ...
- nodejs 在线学习课堂
http://ww***/class/5359f6f6ec7452081a7873d8
- igmpproxy启动时错误:There must be at least 2 Vif's where one is upstream.
openwrt 下启动igmpproxy时报错 # /etc/init.d/igmpproxy start Not starting instance igmpproxy::instance1, an ...
- Vue+ajax的使用小结
js var vue = new Vue({ el:"#vueid", data:{ selectById : "", }, methods:{ yourMet ...
- javascript 搞不清原型链和constructor
prototype.constructor仅仅可以用于识别对象是由哪个构造函数初始化的,仅此而已. var one=new Person(‘js’); 要解释这个结果就要仔细研究一下new这个操作符了 ...