Win10 下 hadoop3.0.0 单机部署
前言
因近期要做 hadoop 有关的项目,需配置 hadoop 环境,简单起见就准备进行单机部署,方便开发调试。顺便记录下采坑步骤,方便碰到同样问题的朋友们。
安装步骤
一、下载 hadoop-XXX.tar.gz
下载地址:http://archive.apache.org/dist/hadoop/core/

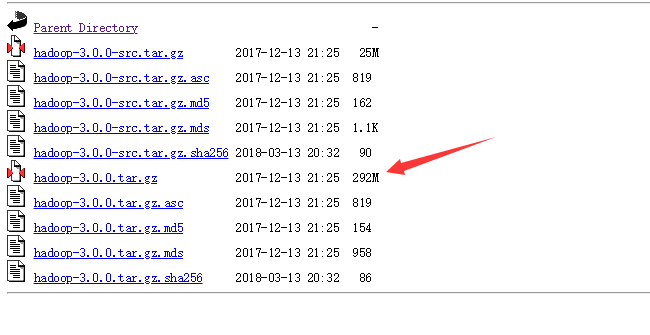
将文件解压至无空格目录下,好像时间有那么点点久。。。。。
注:解压需管理员权限!!!
添加环境变量
添加HADOOP_HOME配置
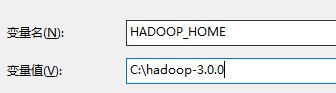
在 path 中添加 bin 目录 C:\hadoop-3.0.0\bin
JAVA_HOME
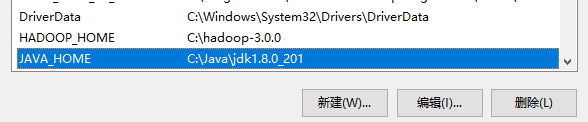
二、hadoop配置
1、修改C:/hadoop-3.0.0/etc/hadoop/core-site.xml配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/C:/hadoop-3.0.0/data/tmp</value>
</property>
</configuration>
2、修改C:/hadoop-3.0.0/etc/hadoop/mapred-site.xml配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
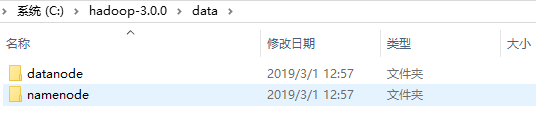
3、在C:/hadoop-3.0.0目录下创建data目录,作为数据存储路径:
- 在D:/hadoop-3.0.0/data目录下创建datanode目录;
- 在D:/hadoop-3.0.0/data目录下创建namenode目录;
4、修改C:/hadoop-3.0.0/etc/hadoop/hdfs-site.xml配置:
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/C:/hadoop-3.0./data/namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/C:/hadoop-3.0./data/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/C:/hadoop-3.0./data/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/C:/hadoop-3.0./data/datanode</value>
</property>
</configuration>
5、修改C:/hadoop-3.0.0/etc/hadoop/yarn-site.xml配置:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6、修改C:/hadoop-3.0.0/etc/hadoop/hadoop-env.cmd配置,添加
set JAVA_HOME=%JAVA_HOME% set HADOOP_PREFIX=%HADOOP_HOME% set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
7、bin目录替换
至https://github.com/steveloughran/winutils下载解压,然后找到对应的版本后完整替换bin目录即可
至此,我们的配置就完成了
三、启动服务
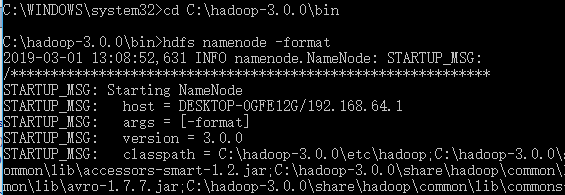
1、打开cmd
cd C:\hadoop-3.0.\bin hdfs namenode -format
2、通过start-all.cmd启动服务:
C:\hadoop-3.0.\sbin\start-all.cmd
然后可以看到同时打开了4个cmd窗口
- Hadoop Namenode
- Hadoop datanode
- YARN Resourc Manager
- YARN Node Manager

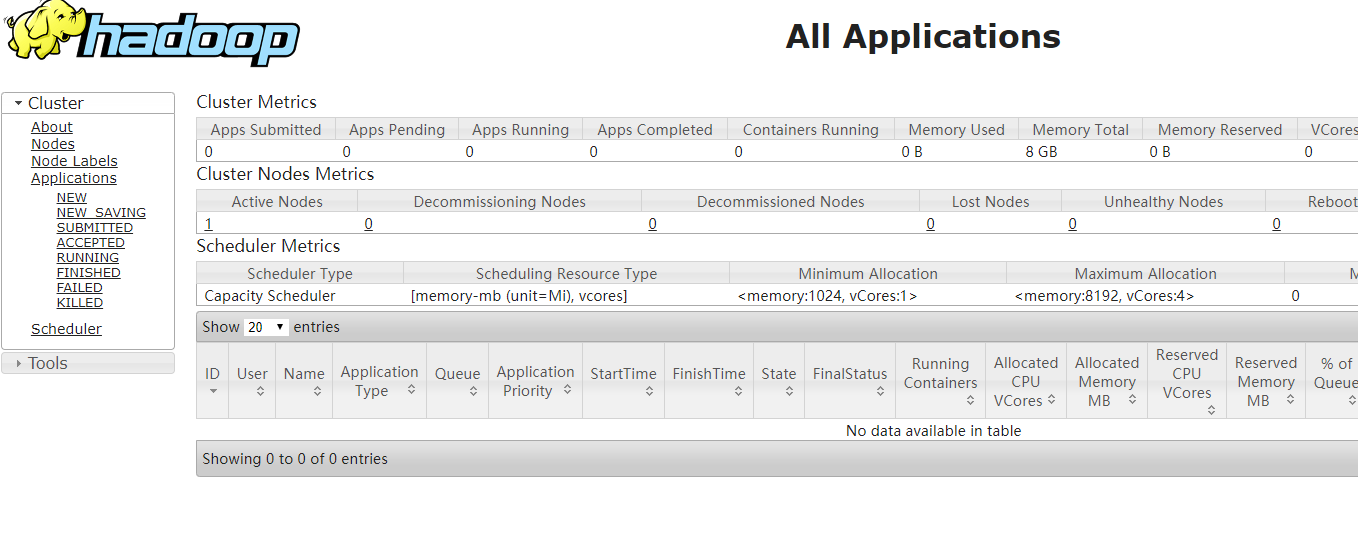
通过http://127.0.0.1:8088/即可查看集群所有节点状态:
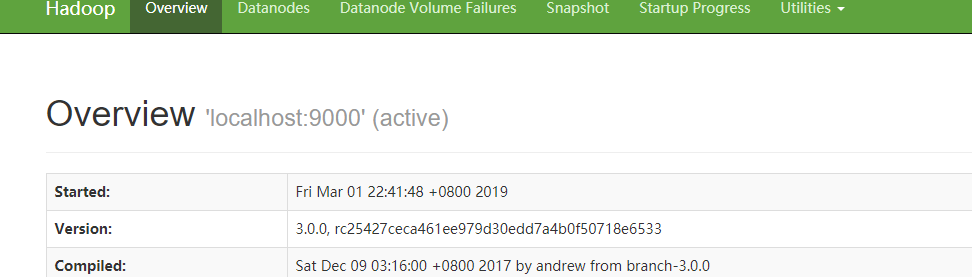
 访问http://localhost:9870/即可查看文件管理页面:
访问http://localhost:9870/即可查看文件管理页面:
总结
一次还算比较顺利的采坑,后面准备开始肝项目了 orz。。。
Win10 下 hadoop3.0.0 单机部署的更多相关文章
- win10 下的 CUDA10.0 +CUDNN + tensorflow + opencv 环境部署
1 CUDA 10.0 安装 win10 下的cuda 安装是非常简单的,和其他程序安装没什么区别,现在 tensorflow 1.13 版本以上 支持 CUDA 10.0 ,这里选取了CUDA 1 ...
- win10下MYSQL 8.0.16的下载、安装以及配置
win10系统MySQL 8.0的下载安装超详细教程 https://blog.csdn.net/qq_34444097/article/details/82315587 下载安装配置链接:https ...
- win10 下springcloud打包docker镜像部署。
1:建一个最简单的springcloud应用. 2:在根目录下新建dockerfile,文件如下: FROM openjdk:8-jdk-alpine VOLUME /tmp ARG JAR_FILE ...
- win10下vc++6.0的安装问题
由于最近需要在win10系统下用到vc++来编程(其实刚开始我是拒绝的,因为vc++各种坑),下面我就把安装vc++时遇到的问题记录下来,方便以后同样遇到这些问题的同学. 安装vc++6.0所需要东西 ...
- win10 下cuda 9.0 卸载
1.首先 对于cuda8.0.cuda7.5的卸载都可以兼容 安装cuda9.0之后,电脑原来的NVIDIA图形驱动会被更新,NVIDIA Physx系统软件也会被更新(安装低版cuda可能不会被更新 ...
- 解决win10下MySQL 8.0登录Access denied for user 'root'@'localhost' (using password: YES)的问题
近些时间在开始学MySQL,安装挺顺利的,按照网上现成的教程就能安装成功. 但是,在输入 mysql -uroot -p 再输入密码时,遇到了这个情况 Access denie ...
- Windows下安装CUDA8.0
在Win10下安装CUDA8.0,并使用VS2013测试: 机器配置: Windows 10 VS 2013 CUDA8.0 CUDA 8.0:下载地址 CUDA其他版本:下载地址 1. 安装CUDA ...
- Hadoop系列之(一):Hadoop单机部署
1. Hadoop介绍 Hadoop是一个能够对海量数据进行分布式处理的系统架构. Hadoop框架的核心是:HDFS和MapReduce. HDFS分布式文件系统为海量的数据提供了存储, MapRe ...
- Win10下Tensorflow+GPU的环境配置
不得不说,想要为深度学习提前打好框架确实需要花费一番功夫.本文主要记录了Win10下,Cuda9.0.Cudnn7.3.1.Tensorflow-gpu1.13.1.python3.6.8.Keras ...
随机推荐
- A - Longest k-Good Segment (尺取法)
题目链接: https://cn.vjudge.net/contest/249801#problem/A 解题思路:尺取法,每次让尺子中包含k种不同的数,然后求最大. 代码: #include< ...
- SpringBoot2.X自定义拦截器实战及新旧配置对比(核心知识)
简介: 讲解拦截器使用,Spingboot2.x新版本配置拦截拦截器和旧版本SpringBoot配置拦截器区别讲解 1.@Configuration 继承WebMvcConfigurationAdap ...
- java 多线程和并行程序设计
多线程使得程序中的多个任务可以同时执行 在一个程序中允许同时运行多个任务.在许多程序设计语言中,多线程都是通过调用依赖系统的过程或函数来实现的 为什么需要多线程?多个线程如何在单处理器系统中同时运行? ...
- Java泛型方法与泛型类的使用------------(五)
泛型的本质就是将数据类型也参数化, 普通方法的输入参数的值是可以变的,但是类型(比如: String)是不能变的,它使得了在面对不同类型的输入参数的时候我们要重载方法才行. 泛型就是将这个数据类型也搞 ...
- Linq基于两个属性的分组
1.需求 我们看下面的定义 #region 学生类 /// <summary> /// 学生类 /// </summary> class Student { /// <s ...
- python2和3使用pip时的问题
win10,电脑之前装有Anaconda,python2.因为需要用到python3,所以直接下载安装了python3.python3默认路径在c盘.我将其移到D盘并修改了两个环境变量.这时电脑的默认 ...
- DDR3基本知识及测试【转】
转自:http://blog.csdn.net/myarrow/article/details/7847385 一.DDR3简介 DDR3(double-data-rate three synchro ...
- 【转】OpenCV—imread读取数据为空
之前遇到一个很郁闷的问题,因为从用OpenCV2.3.1改成OpenCV2.4.4,开始改用Mat和imread来代替Iplimage和cvLoadImage,出了点小问题:imread读入数据总是为 ...
- ubuntu 下抓包
笔记本安装了ubuntu 14.04, 利用笔记本的网卡进行抓包时,需要将网卡配置为monitor模式. (1)关闭无线网卡 sudo ifconfig wlan0 down (2)将无线网卡配置为m ...
- spring事物回滚遇到的问题
在service层使用声明式事务添加@Transactional(rollbackFor = Exception.class)注解 多个方法进行数据库操作,执行失败则隐式的回滚事务,但是已经成功的发方 ...