037 对于HIVE架构的理解
0.发展
在hive公布源代码之后
公司又公布了presto,这个比较快,是基于内存的。
impala:3s处理1PB数据。
1.Hive 能做什么,与 MapReduce 相比优势在哪里
关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉。
其实,还有一个,就是统一的数据管理,可与impala/spark等共享元数据。
2.为什么说 Hive 是 Hadoop 数据仓库,从【数据存储和分析】方 面理解
对于有固定格式的文件,使用HIVE把他存储到HDFS上,然后使用hive操作这些数据,语句执行依赖hadoop,这就是hive的由来。
所以说,Hive是建立在hadoop之上的。
下面具体说明一下:
1.hive构建在Hadoop之上,所有的数据存储在hadoop中hdfs上。
2.分析数据查询数据都是讲任务转化为底层的MapReduce模板,在hadoop上运行。
3.执行的程序可以在yarn上运行。
正是因为hive是hadoop的数据仓库,所以,也有了hive的其他特点:
1.优势在于处理大数据
2.Hive适合离线情况,所以延迟情况比较大。
3.扩张性较好,可以自定义数据类型
3.hive补充
将结构化的结构映射成表。
本质,将SQL转换成mapreduce,也算是hadoop的客户端,不干事情。
4. Hive 架构,分为三个部分来理解,最好通过画图理解
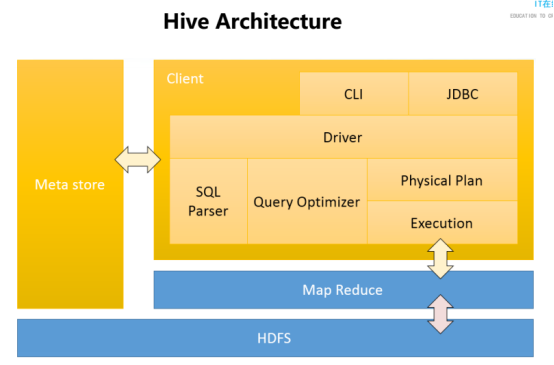
Hive分为Meta store,HDFS,Client三部分。
1.Meta srore 是元数据,默认存储在derby数据库,建议修改配置时修改。
2.HDFS,说明hive的数据存储在很多粉丝上。
3.Client:用户的接口是Cli。通过JDBC链接Driver驱动。
Sql parser是SQL解析器
Query optimizer是优化器。
Physical plan是物理计划。
一步步执行,生成的物理计划,存储在HDFS 上,并随后有mapreduce调用执行。
5.扩展性与灵活性
比较好,因为支持UDF,自定义存储格式。
同时,可以扩展集群规模。
6.总结
构建在hadoop之上的数据仓库
使用HQL作为查询接口,使用HBase存储,使用mapreduce进行计算。
037 对于HIVE架构的理解的更多相关文章
- 对于HIVE架构的理解
1.Hive 能做什么,与 MapReduce 相比优势在哪里 关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉. 2.为什么说 Hive 是 Hadoo ...
- SQL SERVER 2005/2008 中关于架构的理解(二)
本文上接SQL SERVER 2005/2008 中关于架构的理解(一) 架构的作用与示例 用户与架构(schema)分开,让数据库内各对象不再绑在某个用户账号上,可以解决SQL SERVE ...
- SQL SERVER 2005/2008 中关于架构的理解(一)
SQL SERVER 2005/2008 中关于架构的理解(一) 在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询, ...
- 关于ASP.NET或VS2005 搭建三层架构的理解
最近想学习ASP.NET建网站,关于ASP.NET或VS2005 搭建三层架构的理解,网上摘录了一些资料,对于第(2)点的讲解让我理解印象深刻,如下: (1)为何使用N层架构? 因为每一层都可以在仅仅 ...
- 【转】Linux 概念架构的理解
转:http://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=400583492&idx=1&sn=3b18c463dcc451 ...
- Hive之 hive架构
Hive架构图 主要分为以下几个部分: 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hiv ...
- 【转】SQL SERVER 2005/2008 中关于架构的理解
在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询,提示“对象名'CustomEntry' 无效.”.当带上了架构名称 ...
- Hive架构
Hive组织数据包含四种层次:DataBase --> Table --> Partition --> Bucket,对应在HDFS上都是文件夹形式. 数据库和数据仓库的区别: 1) ...
- hive学习(一)hive架构及hive3.1.1三种方式部署安装
1.hive简介 logo 是一个身体像蜜蜂,头是大象的家伙,相当可爱. Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便 ...
随机推荐
- luogu 1631 序列合并
priority_queue的使用,注意 a[1]+b[1],a[1]+b[2],a[1]+b[3],a[1]+b[4].......a[1]+b[n] a[2]+b[1]......... .. a ...
- div背景半透明
例子: html: <div class="erp-mask-a" > <div class="erp-mask-cell-a"> he ...
- mysql 案例 ~ pt-io工具的使用
一 简介:如何使用pt-iopfile调查io具体信息二 目的:利用pt-iopfile分析mysql内部IO操作密集的文件,用以发现问题三 使用: pt-iopfile -p mysql_pid ...
- keepalived高可用系列~通用基础
简介:今天咱们来聊聊keepalived一 keepalived 架构 1 标准架构: keepalived+lvs/haproxy+后端 real server(mysql从库,nginx.myc ...
- session和cookies
Cookie 与session的产生过程 我们都知道HTTP协议本身是无状态的,客户只需要简单的向服务器来发送请求下载某些文件,客户端向 ...
- 转载:(Mac)在bash和zsh配置环境变量path的几种方法
参考文献 老习惯,列出本文参考或引用或转载的文档和博客,致以崇高的敬意,感兴趣的可以去看看 1.http://postgresapp.com/ 2.http://postgresapp.com/doc ...
- java中集合的组成及特点
1:集合 Collection(单列集合) List(有序,可重复) ArrayList 底层数据结构是数组,查询快,增删慢 线程不安全,效率高 Vector 底层数据结构是数组,查询快,增删慢 线程 ...
- 查看tomcat运行状态
实时查看tomcat并发连接数: netstat -na | grep ESTAB | grep 8080 | wc -l 实时查看apache并发连接数: netstat -na | grep ES ...
- sqlserver2008r2数据库使用触发器对sa及其他数据库账号访问进行IP限制
一.只允许指定IP访问数据库 创建测试账号 CREATE LOGIN testuser WITH PASSWORD = '123' GO CREATE TRIGGER [tr_connection_l ...
- 通达OA系统myisam转innodb引擎
OA系统切换到linux环境后,性能提升了2-3倍左右,随着公司的发展壮大,办公人员也会越来越多,当人数达到一定数量级别时如1500在线人数已无法支撑公司业务,就需要对系统进行性能提升优化. 当前OA ...