037 对于HIVE架构的理解
0.发展
在hive公布源代码之后
公司又公布了presto,这个比较快,是基于内存的。
impala:3s处理1PB数据。
1.Hive 能做什么,与 MapReduce 相比优势在哪里
关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉。
其实,还有一个,就是统一的数据管理,可与impala/spark等共享元数据。
2.为什么说 Hive 是 Hadoop 数据仓库,从【数据存储和分析】方 面理解
对于有固定格式的文件,使用HIVE把他存储到HDFS上,然后使用hive操作这些数据,语句执行依赖hadoop,这就是hive的由来。
所以说,Hive是建立在hadoop之上的。
下面具体说明一下:
1.hive构建在Hadoop之上,所有的数据存储在hadoop中hdfs上。
2.分析数据查询数据都是讲任务转化为底层的MapReduce模板,在hadoop上运行。
3.执行的程序可以在yarn上运行。
正是因为hive是hadoop的数据仓库,所以,也有了hive的其他特点:
1.优势在于处理大数据
2.Hive适合离线情况,所以延迟情况比较大。
3.扩张性较好,可以自定义数据类型
3.hive补充
将结构化的结构映射成表。
本质,将SQL转换成mapreduce,也算是hadoop的客户端,不干事情。
4. Hive 架构,分为三个部分来理解,最好通过画图理解
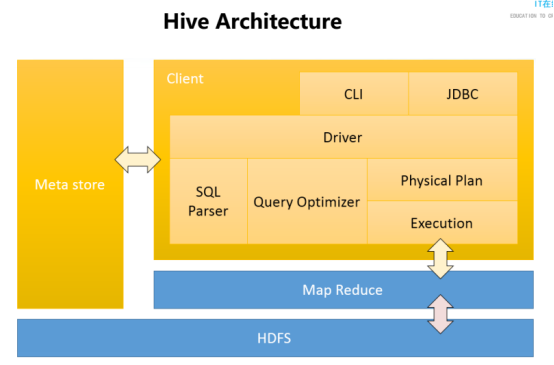
Hive分为Meta store,HDFS,Client三部分。
1.Meta srore 是元数据,默认存储在derby数据库,建议修改配置时修改。
2.HDFS,说明hive的数据存储在很多粉丝上。
3.Client:用户的接口是Cli。通过JDBC链接Driver驱动。
Sql parser是SQL解析器
Query optimizer是优化器。
Physical plan是物理计划。
一步步执行,生成的物理计划,存储在HDFS 上,并随后有mapreduce调用执行。
5.扩展性与灵活性
比较好,因为支持UDF,自定义存储格式。
同时,可以扩展集群规模。
6.总结
构建在hadoop之上的数据仓库
使用HQL作为查询接口,使用HBase存储,使用mapreduce进行计算。
037 对于HIVE架构的理解的更多相关文章
- 对于HIVE架构的理解
1.Hive 能做什么,与 MapReduce 相比优势在哪里 关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉. 2.为什么说 Hive 是 Hadoo ...
- SQL SERVER 2005/2008 中关于架构的理解(二)
本文上接SQL SERVER 2005/2008 中关于架构的理解(一) 架构的作用与示例 用户与架构(schema)分开,让数据库内各对象不再绑在某个用户账号上,可以解决SQL SERVE ...
- SQL SERVER 2005/2008 中关于架构的理解(一)
SQL SERVER 2005/2008 中关于架构的理解(一) 在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询, ...
- 关于ASP.NET或VS2005 搭建三层架构的理解
最近想学习ASP.NET建网站,关于ASP.NET或VS2005 搭建三层架构的理解,网上摘录了一些资料,对于第(2)点的讲解让我理解印象深刻,如下: (1)为何使用N层架构? 因为每一层都可以在仅仅 ...
- 【转】Linux 概念架构的理解
转:http://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=400583492&idx=1&sn=3b18c463dcc451 ...
- Hive之 hive架构
Hive架构图 主要分为以下几个部分: 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hiv ...
- 【转】SQL SERVER 2005/2008 中关于架构的理解
在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询,提示“对象名'CustomEntry' 无效.”.当带上了架构名称 ...
- Hive架构
Hive组织数据包含四种层次:DataBase --> Table --> Partition --> Bucket,对应在HDFS上都是文件夹形式. 数据库和数据仓库的区别: 1) ...
- hive学习(一)hive架构及hive3.1.1三种方式部署安装
1.hive简介 logo 是一个身体像蜜蜂,头是大象的家伙,相当可爱. Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便 ...
随机推荐
- js 碰撞 + 重力 运动
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [C++]Linux之图形界面编程库[curses库]之入门教程
1. 安装 //方法一 sudo apt-get install libncurses5-dev [ ubuntu 16.04:亲测有效] //方法二 sudo apt-get install ncu ...
- mysql 查询优化案例汇总
一 简介:此文章为经历过的sql案例集合和相关思路 二 案例1: 现象: 测试环境出现select语句,join2张表多次join,explain结果如下 出现 using where,using j ...
- vue UI框架
一.pc端 element UI 饿了么UI支持vue2.x80分优点:组件的API方法.属性等封装的较为完善缺点:样式有些生硬,不够炫酷美观 N3 N3支持vue2.x70分优点:组件操作几乎都有动 ...
- 2017-2018-2 20155303『网络对抗技术』Exp1:PC平台逆向破解
2017-2018-2 『网络对抗技术』Exp1:PC平台逆向破解 --------CONTENTS-------- 1. 逆向及Bof基础实践说明 2. 直接修改程序机器指令,改变程序执行流程 3. ...
- java并发编程系列二:原子操作/CAS
什么是原子操作 不可被中断的一个或者一系列操作 实现原子操作的方式 Java可以通过锁和循环CAS的方式实现原子操作 CAS( Compare And Swap ) 为什么要有CAS? Compar ...
- secureCRT连接linux系统
linux和secureCRT利用ssh协议22端口进行远程连接的 连接如果没有成功,请检查远程主机的端口和ssh是否开启 一.检查看SSH服务是否开启 当然有的linux系统使用的命令是/etc/i ...
- android手机访问app网页报错:net::ERR_PROXY_CONNECTION_FAILED
手机访问网页报错:net::ERR_PROXY_CONNECTION_FAILED 手机访问app中嵌入的html网页报错: net::ERR_PROXY_CONNECTION_FAILED 原来是手 ...
- ubuntu系统下Python虚拟环境的安装和使用
ubuntu系统下Python虚拟环境的安装和使用 前言:进行python项目开发的时候,由于不同的项目需要使用不同的资源包和相关的配置,因此创建多个python虚拟环境,在虚拟环境下开 ...
- PYTHON-绑定方法 反射 内置函数
'''绑定方法类中定义函数分为了两大类: 1. 绑定方法 特殊之处: 绑定给谁就应该由谁来调用,谁来调用就会将谁当做第一个参数自动传入 如何用: 绑定给对象的方法: 在类中定义函数没有被任何装饰器修饰 ...