【转载】 BN(batch normalization)
原文地址:
https://blog.csdn.net/qq_35608277/article/details/79212700
-------------------------------------------------------------------------------------------------------
算法本质解决梯度弥散,加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯
优势:
(1) 可以使用更高的学习率
如果每层的scale不一致,实际上每层需要的学习率是不一样 的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使 用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。
(2) 移除或使用较低的dropout。
dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
(3) 降低L2权重衰减系数。
还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
(4) 取消Local Response Normalization层。
由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上也没那么work。
(5) 减少图像扭曲的使用。
由于现在训练epoch数降低,所以要对输入数据少做一些扭曲,让神经网络多看看真实的数据。
1.Motivation
网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,作者将分布发生变化称之为internal covariate shift。因此我们不得不降低学习率、小心地初始化。
为了加快训练,在训练网络的时会将输入减去均值,还有些人甚至会对输入做白化等操作。相当于在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。
常用PCA白化:即对数据进行PCA操作之后,再进行方差归一化。
基本满足0均值、单位方差、弱相关性。
但是,对每一层数据都使用白化操作,分析认为这是不可取的。因为白化需要计算协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,白化操作不一定可导。
因此,提出了新的预处理层BN
2.Normalization via Mini-Batch Statistics
就像激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。
数据归一化方法很简单,近似白化预处理:
就是要让batch数据具有0均值和单位方差
(每一维度减去自身均值,再除以自身标准差)。
但结果都在0-1之间,相当于只使用了激活函数中近似线性的部分,线性模型会降低模型表达能力。(会影响到本层网络A所学习到的特征的。
比如网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于这一层网络所学习到的特征分布被你搞坏了)
算法关键在于作者又为BN增加了2个参数,得到前向传导过程公式,
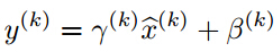
u为一个batch的输入二维矩阵
m = K.mean(u, axis=-, keepdims=True)#计算均值
std = K.std(u, axis=-, keepdims=True)#计算标准差
X_normed = (u - m) / (std + self.epsilon)#归一化
BNout = self.gamma * u_normed + self.beta#重构变换
z=g(BN(Wu_norm+b))
其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。
最后为:
z=g(BN(Wu_norm))
用来保持模型的表达能力(至少可以恢复原数据)。
测试时,均值方差换成整个数据集的,不再是一个batch的。
因此,在训练过程中我们要记录每一个Batch的均值和方差,以便训练完成之后按照下式计算整体的均值和方差:
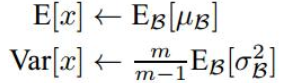
均值计算所有batch u值的平均值;
标准偏差采用每个batch σB的无偏估计
BN before or after Activation?
作者在文章中说应该把BN放在激活函数之前,这是因为Wx+b具有更加一致和非稀疏的分布。但是也有人做实验表明放在激活函数后面效果更好。
这是实验链接,里面有很多有意思的对比实验:https://github.com/ducha-aiki/caffenet-benchmark
3-BN on CNN
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?
假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。
因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理,计算该特征图对应数据的均值和方差进行归一化。
网络某一层输入数据可以表示为
四维矩阵(m,f,p,q),
m为min-batch sizes,
f为特征图个数,
p、q分别为特征图的宽高
mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。
像卷积层这样具有权值共享的层,x=Wu+b的均值和方差是对整张map求得的,在batch_size * channel * height * width这么大的一层中,对总共batch_size*height*width个像素点统计得到一个均值和一个标准差,共得到channel组参数。
reference
http://blog.csdn.net/app_12062011/article/details/57083447
http://blog.csdn.net/hjimce/article/details/50866313
http://blog.csdn.net/happynear/article/details/44238541
https://www.zhihu.com/question/38102762
【转载】 BN(batch normalization)的更多相关文章
- 转载-通俗理解BN(Batch Normalization)
转自:参数优化方法 1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Prep ...
- BN(Batch Normalization)
Batch Nornalization Question? 1.是什么? 2.有什么用? 3.怎么用? paper:<Batch Normalization: Accelerating Deep ...
- 转载--对batch normalization的理解
转载的大神的: https://www.cnblogs.com/guoyaohua/p/8724433.html 上边这个应该是抄的下边这个原文,但是上边的有重点标记 https://blog.csd ...
- 【转载】 详解BN(Batch Normalization)算法
原文地址: http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ------------------------------- ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- 神经网络之 Batch Normalization
知乎 csdn Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ...
- Batch Normalization 详解
一.背景意义 本篇博文主要讲解2015年深度学习领域,非常值得学习的一篇文献:<Batch Normalization: Accelerating Deep Network Training b ...
随机推荐
- Lucene.Net 学习(搜索部分)(低要求,写给自己看)
1. 搜索 排序:lucene 提供了Sort类对结果进行排序 提供了Filter类对查询条件进行限制 你或许会不自觉地拿它跟SQL语句进行比较:“lucene能执行and.or.order by.w ...
- 【LeetCode】最大子序列和
要求时间复杂度 O(n). e.g. 给定数组 [-2,1,-3,4,-1,2,1,-5,4],其中有连续子序列 [4,-1,2,1] 和最大为 6. 我完全没有想法,看了答案. C++实现: int ...
- [洛谷 P3788] 幽幽子吃西瓜
妖梦费了好大的劲为幽幽子准备了一个大西瓜,甚至和兔子铃仙打了一架.现在妖梦闲来无事,就蹲在一旁看幽幽子吃西瓜.西瓜可以看作一个标准的球体,瓜皮是绿色的,瓜瓤是红色的,瓜皮的厚度可视为0.妖梦恰好以正视 ...
- django学习之——我的 Hello World
pycharm 打开django 创建的项目:添加views.py文件 修改 urls.py from django.conf.urls import patterns, include, url f ...
- Python3+pdfminer+jieba+wordcloud+matplotlib生成词云(以深圳十三五规划纲要为例)
一.各库功能说明 pdfminer----用于读取pdf文件的内容,python3安装pdfminer3k jieba----用于中文分词 wordcloud----用于生成词云 matplotlib ...
- 如何将两个字段合成一个字段显示(oracle和sqlserver的区别)
oracle中,如何将两个字段数据合并成一个字段显示,接下来看一下在sql server和pl/sql的区别 sql server中如何合并(用Cast()函数) --1.创建模拟的数据表--- cr ...
- Win10系列:JavaScript 的 WinJS库
WinJS 库是由 CSS 和 JavaScript 文件组成的.使用Visual Studio 2012新建一个JavaScript 的Windows应用商店的空白应用程序项目,在项目的引用管理器中 ...
- 网口扫盲二:Mac与Phy组成原理的简单分析
1. general 下图是网口结构简图.网口由CPU.MAC和PHY三部分组成.DMA控制器通常属于CPU的一部分,用虚线放在这里是为了表示DMA控制器可能会参与到网口数据传输中. MAC(Medi ...
- 分布式锁与实现(一)基于Redis实现
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题.分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency).可用性( ...
- Saiku二次开发获取源代码在本地编译(五)
关于Saiku的二次开发,在本地编译然后启动自己编译好的Saiku服务 Saiku是开源的,从github上能下载源代码,本例中的saiku源码也是从github上找的,然后自己改了一些pom.xml ...