Linux下zoopkeeper的安装和启动
Linux下zoopkeeper的安装和启动
1.什么是zookeeper
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
- ZooKeeper包含一个简单的原语集,提供Java和C的接口。
- ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3
- 4.8\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
- zookeeper 是Hadoop的master角色的单点故障问题的主要
。
Zookeeper的ZAB协议和Paxos协议
- 二阶段提交和三阶段提交协议和Paxos协议都是分布式应用程序的通用协议,即在大部分的分布式应用程序中都可以使用。ZAB(zookeeper
Atomic
Broadcast)zookeeper原子消息广播协议)协议是zookeeper设计之初专门为雅虎内部那些高吞吐量、低延迟、健壮、简单的分布式场景设计的。所以ZAB不是一种通用型算法,而是一种特别为zookeeper设计的崩溃可恢复的原子消息广播算法。ZAB算法可是看成是paxos协议的一种具体实现,理解Paxos协议较为困难,我们不做掌握。 - Zookeeper中将自己的角色系统设置主要为Leader、Flower、OBServer。Leader和Flower都是zk的server,只不过由Leader(只会存在一个,类似于Hadoop的NameNode)对外提供服务,众多Flower(类似于secondary
namenode,不过Flow会有多个)随时准备等Leader出现问题时选举出一个新leader来继续对外提供以保证zk服务的高可用。
Zookeeper集群中的机器数量设置
Zookeeper为了防止出现二阶段和三阶段提交协议中出现的数据不一致的情况(例如:网络出现问题,可能会将zk集群分成多个小集群),规定了只有zk集群中半数以上的server存活时才能对外提供服务。所以我们一般安装zk集群时,一般设置为奇数台zk的server。
假如,我们的zk集群有6个server,那么我们最多允许有两个server挂掉zk集群还能继续对外提供服务。但是如果我们的zk集群有5个server的话,我们同样最多允许有两个server挂掉也能继续提供服务。所以一般zk集群安装时server的数量是奇数个。
数据节点(Znode)
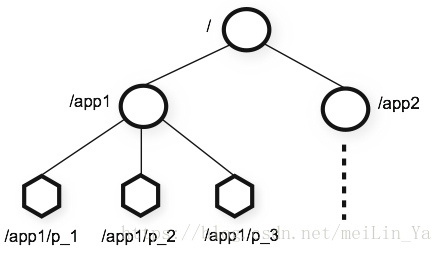
一,下载并解压 ##:
下载地址:https://mirrors.cnnic.cn/apache/zookeeper/
zookeeper要求java运行环境:详情如
https://blog.csdn.net/meiLin_Ya/article/details/80650945解压:
tar zxvf zookeeper-3.4.11.tar.gz -C /usr/local/修改配置文件
1.将配置文件zoo_sample改名为cfg zoo.cfg
cp zoo_sample.cfg zoo.cfg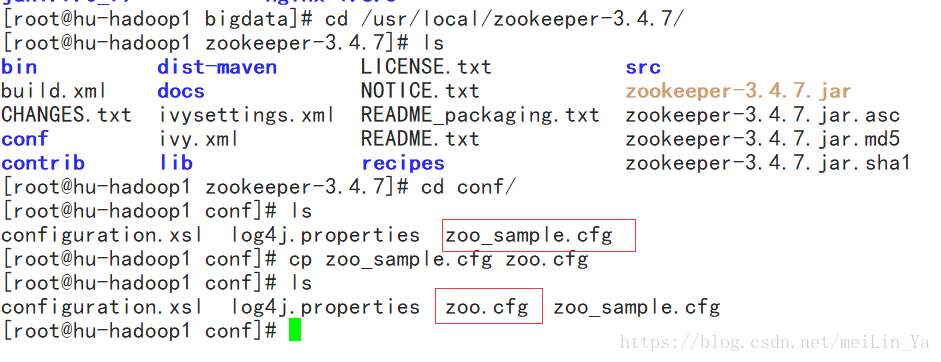
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.4.7/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
dataLogDir=/usr/local/zookeeper-3.4.7/log
#autopurge.purgeInterval=1
server.11=hu-hadoop1:2888:3888
server.12=hu-hadoop2:2888:3888
server.13=hu-hadoop3:2888:3888 tickTime:时长单位为毫秒,为zk使用的基本时间度量单位。例如,1
tickTime是客户端与zk服务端的心跳时间,2
tickTime是客户端会话的超时时间。tickTime的默认值为2000毫秒,更低的tickTime值可以更快地发现超时问题,但也会导致更高的网络流量(心跳消息)和更高的CPU使用率(会话的跟踪处理)。
clientPort:zk服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
dataDir:无默认配置,必须配置,用于配置存储快照文件的目录。如果没有配置dataLogDir,那么事务日志也会存储在此目录。
创建相应得目录,存放日志文件
dataDir=/usr/local/zookeeper-3.4.11/data
dataLogDir=/usr/local/zookeeper-3.4.11/log 记得创建那两个文件夹。。。。完成后将在data下创建一个文本 必须叫myid 里面填写的是你的zookeeper中的主机唯一标识。
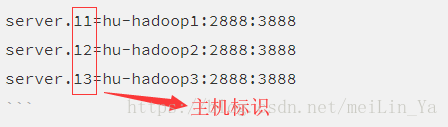
而你的zookeeper在zoo.cfg中配置。
配置环境:
vi /ext/profileexport JAVA_HOME=/home/bigdata/jdk1.7.0_79
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.7
export HADOOP_HOME=/home/bigdata/hadoop-2.6.0
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:
修改日志文件打印的地方
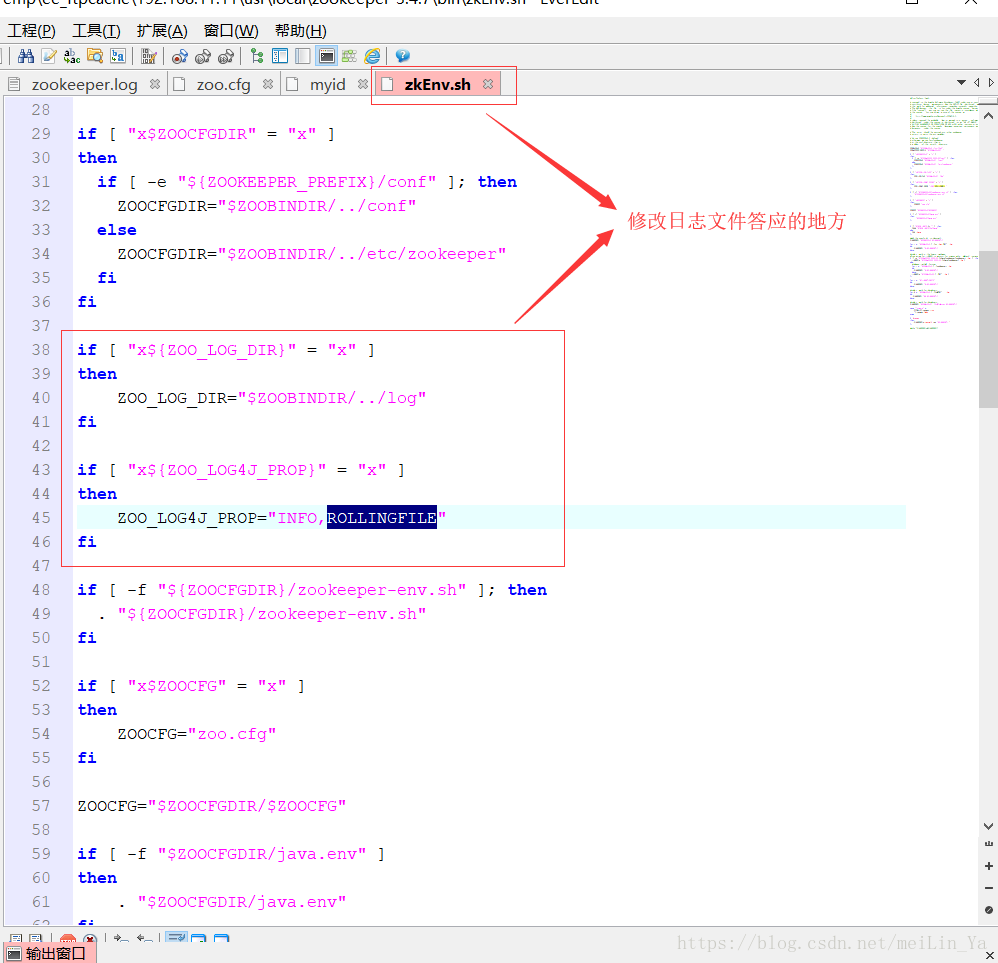
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
if [ -f "${ZOOCFGDIR}/zookeeper-env.sh" ]; then
. "${ZOOCFGDIR}/zookeeper-env.sh"
fi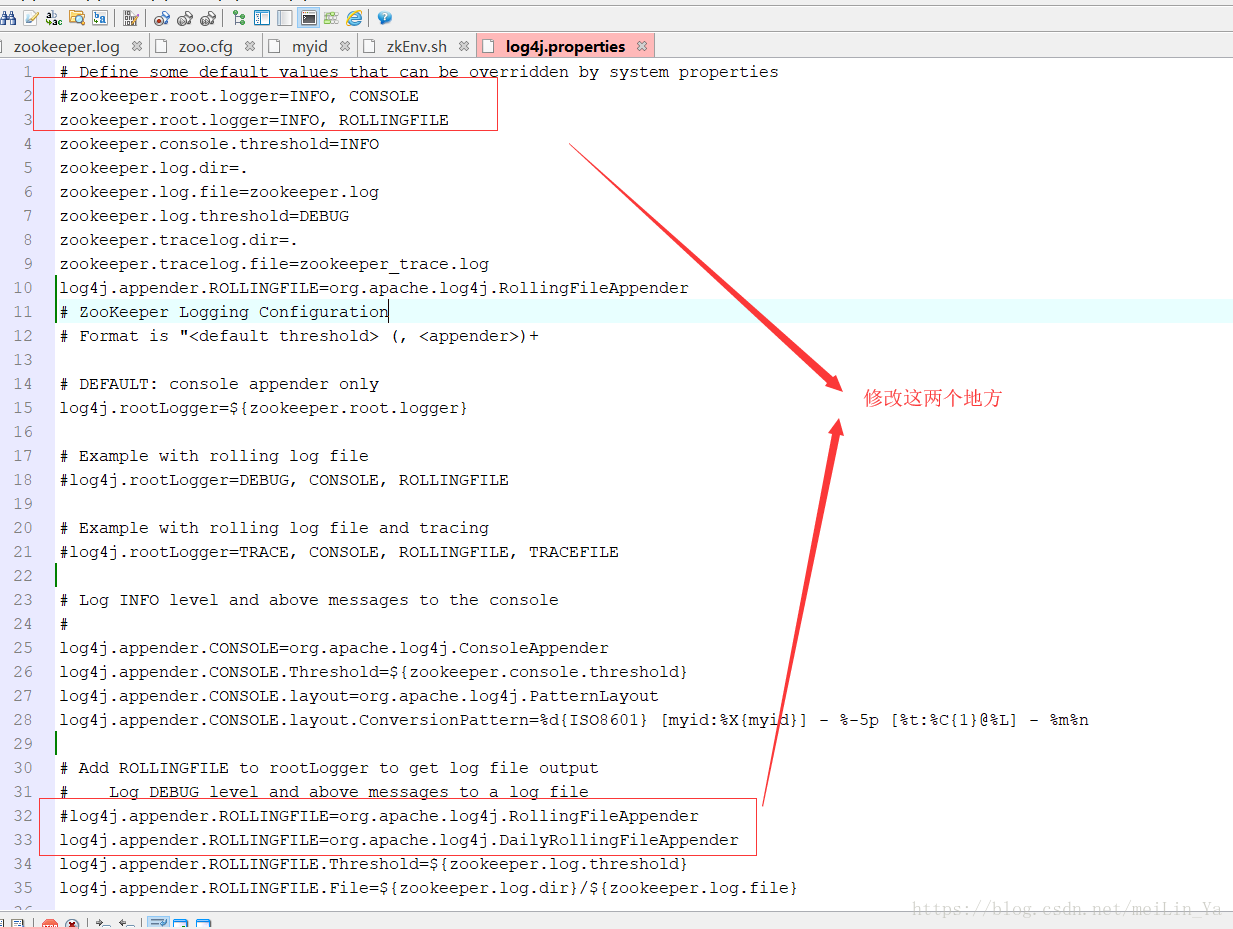
zookeeper.root.logger=INFO, ROLLINGFILE
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender改为—每天一个log日志文件,而不是在同一个log文件中递增日志
日志输出为:
[root@hu-hadoop1 conf]# ls
configuration.xsl log4j.properties zoo.cfg
[root@hu-hadoop1 conf]# ll
total 12
-rw-rw-r--. 1 1000 1000 535 Nov 11 2015 configuration.xsl
-rw-rw-r--. 1 1000 1000 2326 Jun 11 15:08 log4j.properties
-rw-r--r--. 1 root root 1073 Jun 11 13:15 zoo.cfg
[root@hu-hadoop1 conf]#

启动zookeeper:
启动第一台:
zkServer.sh start
[root@hu-hadoop3 conf]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看状态:
zkServer.sh status
[root@hu-hadoop3 conf]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.7/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
这样是正确的。因为zookeeper最少安装2个以上有详细解释。再启动一台
启动后查看状态:
[root@hu-hadoop2 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
然后再返回了看上一个状态:
[root@hu-hadoop3 conf]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: leader
然后再启动另一条:我这里配了3台
[root@hu-hadoop1 conf]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
这里的leader是随机的不是固定的。
肯用到的命令:
停止一个zookeeper:
zkService.sh stopzkCli.sh:
1)查看当前节点列表
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
2)创建节点
[zk: localhost:2181(CONNECTED) 2] create /test "test"
Created /test
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper, test]
3)查看节点数据
[zk: localhost:2181(CONNECTED) 4] get /test
"test"
cZxid = 0x300000007
ctime = Thu Sep 24 05:54:51 PDT 2015
mZxid = 0x300000007
mtime = Thu Sep 24 05:54:51 PDT 2015
pZxid = 0x300000007
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
4)设置节点数据
[zk: localhost:2181(CONNECTED) 7] set /test "111111"
cZxid = 0x300000007
ctime = Thu Sep 24 05:54:51 PDT 2015
mZxid = 0x300000008
mtime = Thu Sep 24 05:57:40 PDT 2015
pZxid = 0x300000007
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 0
[zk: localhost:2181(CONNECTED) 8] get /test
"111111"
cZxid = 0x300000007
ctime = Thu Sep 24 05:54:51 PDT 2015
mZxid = 0x300000008
mtime = Thu Sep 24 05:57:40 PDT 2015
pZxid = 0x300000007
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 0
5)删除节点
[zk: localhost:2181(CONNECTED) 9] delete /test
[zk: localhost:2181(CONNECTED) 10] ls /
[zookeeper]Linux下zoopkeeper的安装和启动的更多相关文章
- Linux下OpenOffice的安装与启动
公司项目需求中增加了文档预览功能,所以采用了OpenOffice提供的将office文件转换为pdf的工具.那么我们的程序运行在服务器端,服务器系统版本多是Linux,因此有必要记录下Linux下Op ...
- Linux下mongodb的安装及启动
安装 1>设置mongoDB目录 cd /home/apps 附:centOS下创建目录命令 mkdir /home/apps 2>下载mongodb curl -O http://fa ...
- Linux下MySQL的安装和启动(转载)
原文链接:http://www.linuxidc.com/Linux/2016-07/133234.htm 一.MySQL各类安装方法的比较 在Linux系统下,MySQL有3种主要的安装方式,分别是 ...
- linux下redis的安装、启动、关闭和卸载
edis 在Linux 和 在Windows 下的安装是有很大的不同的,和通常的软件安装是一样的. 一 下载 Redis 安装包 去redis 官网下载reids 安装包, redis 官网默认只提 ...
- Linux下的ngnix安装与启动
Linux安装Nginx 1.安装gcc gcc-c++(如新环境,未安装请先安装)$ yum install -y gcc gcc-c++2.安装wget$ yum -y install wget ...
- linux下openoffice的安装和启动
下载openoffice的安装包(注意选择合适的安装包): http://www.openoffice.org/download/archive.html 一.安装openOffice1.使用tar ...
- Linux下memcache的安装和启动测试
memcache是一套分布式的高速缓存系统,MemCache的工作流程如下:先检查客户端的请求数据是否在memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作:如果请求的数据不在me ...
- Linux下编译、安装并启动apache
安装步骤如下: 1. 首先去http://httpd.apache.org/download.cgi上下载需要的apache源码,然后存放至/usr/local/src下[此源码存放路径可任意指定] ...
- Linux下编译、安装并启动memcached
首先使用yum安装gcc make.autoconf.libtool系列工具,这几个工具是编译所需要的,命令如下: yum install gcc make autoconf libtool 然后到l ...
随机推荐
- 【Java】【存储&作用域】
[存储] 1. 寄存器.这是最快的保存群裕,因为它位于和其他所有保存方式不同的地方:处理器内部.然而,寄存器的数量有限,所以寄存器是根据需要由编译器分配.我们对此没有直接的控制权,也不可能在自己的程序 ...
- hdu 5724 Chess 博弈sg+状态压缩
Chess Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Problem De ...
- Linux下的压缩解压缩命令详解及实例
实例:压缩服务器上当前目录的内容为xxx.zip文件 zip -r xxx.zip ./* 解压zip文件到当前目录 unzip filename.zip ====================== ...
- Arrays常用方法
传送:https://blog.csdn.net/u013256816/article/details/50924762
- [转][osg]关于PagedLOD 加载卸载机制
你的PagedLOD 为什么没有卸载 转自:http://bbs.osgchina.org/forum.php?mod=viewthread&tid=7612&highlight=Pa ...
- leecode第八题(字符串转换整数 (atoi))
;//判断返回0是因为错误还是真的是0 class Solution { public: int myAtoi(string str) {//写的很丑 if (str=="") ; ...
- ubuntu vscode chrome 显示color emoji
win10 下vscode默认就可以显示color emoji, 真是亲儿子啊. 但linux下默认是显示黑白的. 绕了一些弯路之后,发现最简单的办法是: 1 下载google noto字体全集 ...
- Qt的Radio Button(单选按钮)
1 在UI界面中加入控件 2 对QRadioButton控件进行分组 QRadioButton的分组有多重方法,如采用组合框.QWidge等,下面介绍采用QButtonGroup方法来实现分组,好处是 ...
- go build 和 go install
环境:Win10 + GO1.9.2 1.区别 ①go build:编译go源码生成一个可执行文件:使用-o参数可以指定生成的可执行文件名称,如go build -o test.exe ②go ins ...
- 录音 voice record
参考 : http://air.ghost.io/recording-to-an-audio-file-using-html5-and-js/ (html5 基础) https://github.co ...