云计算(7)---the scheduler of Hadoop
The scheduler of Hadoop
Programming MapReduce

在有些情况下,reducer也可以先开始于Map.但为了便于理解,在这儿我们都是使reduce不会早于map发生
the traffic that data from map to reduce is called shuffle traffic,这些shuffle traffic可以并行运行(map task还在运行), shuffle phase可以与map phase并行运行.一旦
shuffle phase结束,则reduce phase可以开始了.
Inside MapReduce

map的input数据是存储在distributed file system中的.
map的output放在map task运行的本地机器上(local disk),这些数据不是被用户需要的,它们只是被reduce阶段需要,为了不增加distributed file system的负载(因为它们可能会在Distributed file system中被复制),这样就可以加快reduce task取数据的速度。
Reduce阶段结束后,数据会被存储回distributed file system中
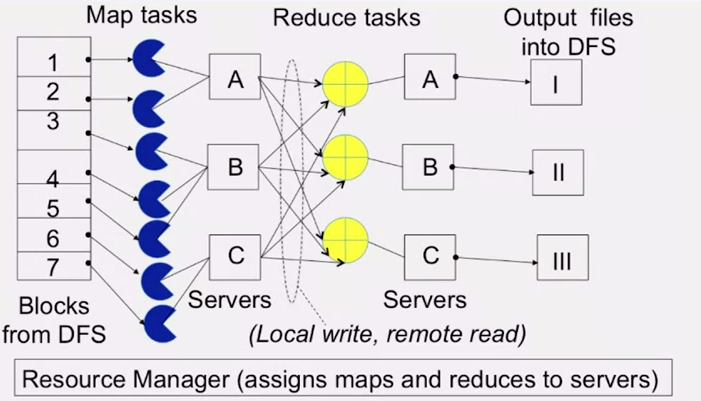
The YARN schedular(Hadoop 2.x +)

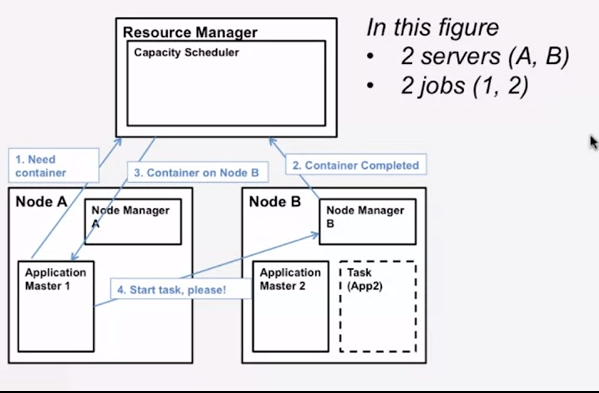
如果一个server有4个cores,4 gigabytes RAM,若每个container有一个core,1 gigabyte of RAM,则这个server有4个containers,可以运行4个tasks
只有一个global resource manager,每个server都有一个node managert,1个job有一个AM(application master)在其中一台server上.
YARN:一个job怎么得到container
云计算(7)---the scheduler of Hadoop的更多相关文章
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的 1. 掌握Linux虚拟机的安装方法. 2. 掌握Hadoop的伪分布式安装方法. 二.实验内容 (一)Linux基本操作命令 Linux常用基本命令包括: ls,cd,mkdir,rm ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- Hadoop,大数据,云计算三者之间的关系
大数据和云计算是何关系?关于大数据和云计算的关系人们通常会有误解.而且也会把它们混起来说,分别做一句话直白解释就是:云计算就是硬件资源的虚拟化;大数据就是海量数据的高效处理.大数据.hadoop及云计 ...
- Hadoop大数据生态系统及常用组件(山东数漫江湖)
经过多年信息化建设,我们已经进入一个神奇的“大数据”时代,无论是在通讯社交过程中使用的微信.QQ.电话.短信,还是吃喝玩乐时的用到的团购.电商.移动支付,都不断产生海量信息数据,数据和我们的工作生活密 ...
- [Hadoop in Action] 第1章 Hadoop简介
编写可扩展.分布式的数据密集型程序和基础知识 理解Hadoop和MapReduce 编写和运行一个基本的MapReduce程序 1.什么是Hadoop Hadoop是一个开源的框架,可编写和运 ...
- 换个角度理解云计算之HDFS
学习云计算,必然得了解Hadoop,而Hadoop中的HDFS(分布式文件系统)是一个基础,接下来就写一下我所理解的HDFS. 有一个很有特别的村庄,村庄里面有一个很牛逼的人,叫做“大哥”,村民们都信 ...
随机推荐
- SELinux安全子系统的学习
SELinux(Security-Enhanced Linux)是美国国家安全局在 Linux 开源社区的帮助下开发的 一个强制访问控制(MAC,Mandatory Access Control)的安 ...
- Ubuntu16.04安装qt
5.11官方下载网站: http://download.qt.io/official_releases/qt/5.11/5.11.1/ 可以直接下载linux系统下的.run安装包: 安装方式:htt ...
- LeetCode 102. 二叉树的层次遍历(Binary Tree Level Order Traversal) 8
102. 二叉树的层次遍历 102. Binary Tree Level Order Traversal 题目描述 给定一个二叉树,返回其按层次遍历的节点值. (即逐层地,从左到右访问所有节点). 每 ...
- Kibana配置安装
学习网站 https://discuss.elastic.co https://github.com/elastic 配置 server.port: 5601 server.host: "l ...
- php异常处理面向对象和面向函数使用
要使用异常,首先得知道那些部分会产生异常,产生什么类型异常(php常见异常见下方符表),对产生的异常该怎么办. 如果知道程序的那些部分会产生异常,那么就对这一部分使用try关键字: 如果知道了产生异常 ...
- str.format() 格式化数字的多种方法
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能. 基本语法是通过 {} 和 : 来代替以前的 % . format 函数可以接受不限个参数 ...
- 机器学习-LDA主题模型笔记
LDA常见的应用方向: 信息提取和搜索(语义分析):文档分类/聚类.文章摘要.社区挖掘:基于内容的图像聚类.目标识别(以及其他计算机视觉应用):生物信息数据的应用; 对于朴素贝叶斯模型来说,可以胜任许 ...
- Vuex入门、同步异步 存取值
目的: 1.了解vuex中的各个js文件的用途 2.利用vuex存值 3.利用vuex取值 4.Vuex的异步同步加载问题 1. vuex中各个组件之间传值 1.父子组件 父组件-->子组件,通 ...
- CentOS7安装firewall防火墙
CentOS7之后 , 系统已经推荐了firewall防火墙 , 而不是iptables 主要 : firewall 和 iptables冲突 , 需要禁用其中一个. #停止iptables服务 sy ...
- 【转载】C#使用as关键字将对象转换为指定类型
在C#的编程开发过程中,很多时候涉及到数据类型的转换,可使用强制转换的方式,不过强制转换数据类型有时候会抛出程序异常错误,可以使用as关键字来进行类型的转换,如果转换成功将返回转换后的对象,如果转换不 ...