Pytorch1.0入门实战三:ResNet实现cifar-10分类,利用visdom可视化训练过程
人的理想志向往往和他的能力成正比。 —— 约翰逊
最近一直在使用pytorch深度学习框架,很想用pytorch搞点事情出来,但是框架中一些基本的原理得懂!本次,利用pytorch实现ResNet神经网络对cifar-10数据集进行分类。CIFAR-10包含60000张32*32的彩色图像,彩色图像,即分别有RGB三个通道,一共有10类图片,每一类图片有6000张,其类别有飞机、鸟、猫、狗等。
注意,如果直接使用torch.torchvision的models中的ResNet18或者ResNet34等等,你会遇到最后的特征图大小不够用的情况,因为cifar-10的图像大小只有32*32,因此需要单独设计ResNet的网络结构!但是采用其他的数据集,比如imagenet的数据集,其图的大小为224*224便不会遇到这种情况。
1、运行环境:
- python3.6.8
- win10
- GTX1060
- cuda9.0+cudnn7.4+vs2017
- torch1.0.1
- visdom0.1.8.8
2、实战cifar10步骤如下:
- 使用torchvision加载并预处理CIFAR-10数据集
- 定义网络
- 定义损失函数和优化器
- 训练网络,计算损失,清除梯度,反向传播,更新网络参数
- 测试网络
3、代码
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import dataloader
import torchvision.models as models
from tqdm import tgrange
import torch.optim as optim
import numpy
import visdom
import torch.nn.functional as F vis = visdom.Visdom()
batch_size = 100
lr = 0.001
momentum = 0.9
epochs = 100 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') def conv3x3(in_channels,out_channels,stride = 1):
return nn.Conv2d(in_channels,out_channels,kernel_size=3, stride = stride, padding=1, bias=False)
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride = 1, shotcut = None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels,stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shotcut = shotcut def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.shotcut:
residual = self.shotcut(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layer, num_classes = 10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3,16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True) self.layer1 = self.make_layer(block, 16, layer[0])
self.layer2 = self.make_layer(block, 32, layer[1], 2)
self.layer3 = self.make_layer(block, 64, layer[2], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes) def make_layer(self, block, out_channels, blocks, stride = 1):
shotcut = None
if(stride != 1) or (self.in_channels != out_channels):
shotcut = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels,kernel_size=3,stride = stride,padding=1),
nn.BatchNorm2d(out_channels)) layers = []
layers.append(block(self.in_channels, out_channels, stride, shotcut)) for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
self.in_channels = out_channels
return nn.Sequential(*layers) def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x #标准化数据集
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) train_dataset = datasets.CIFAR10(root = './datacifar/',
train=True,
transform = data_tf,
download=False) test_dataset =datasets.CIFAR10(root = './datacifar/',
train=False,
transform= data_tf,
download=False)
# print(test_dataset[0][0])
# print(test_dataset[0][0][0])
print("训练集的大小:",len(train_dataset),len(train_dataset[0][0]),len(train_dataset[0][0][0]),len(train_dataset[0][0][0][0]))
print("测试集的大小:",len(test_dataset),len(test_dataset[0][0]),len(test_dataset[0][0][0]),len(test_dataset[0][0][0][0]))
#建立一个数据迭代器
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = False)
'''
print(train_loader.dataset)
---->
Dataset CIFAR10
Number of datapoints: 50000
Split: train
Root Location: ./datacifar/
Transforms (if any): Compose(
ToTensor()
Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
)
Target Transforms (if any): None
''' model = ResNet(ResidualBlock, [3,3,3], 10).to(device) criterion = nn.CrossEntropyLoss()#定义损失函数
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
print(model) if __name__ == '__main__':
global_step = 0
for epoch in range(epochs):
for i,train_data in enumerate(train_loader):
# print("i:",i)
# print(len(train_data[0]))
# print(len(train_data[1]))
inputs,label = train_data
inputs = Variable(inputs).cuda()
label = Variable(label).cuda()
# print(model)
output = model(inputs)
# print(len(output)) loss = criterion(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 99:
print('epoch:%d | batch: %d | loss:%.03f' % (epoch + 1, i + 1, loss.item()))
vis.line(X=[global_step],Y=[loss.item()],win='loss',opts=dict(title = 'train loss'),update='append')
global_step = global_step +1
# 验证测试集 model.eval() # 将模型变换为测试模式
correct = 0
total = 0
for data_test in test_loader:
images, labels = data_test
images, labels = Variable(images).cuda(), Variable(labels).cuda()
output_test = model(images)
# print("output_test:",output_test.shape)
_, predicted = torch.max(output_test, 1) # 此处的predicted获取的是最大值的下标
# print("predicted:", predicted)
total += labels.size(0)
correct += (predicted == labels).sum()
print("correct1: ", correct)
print("Test acc: {0}".format(correct.item() / len(test_dataset))) # .cpu().numpy()
4、结果展示
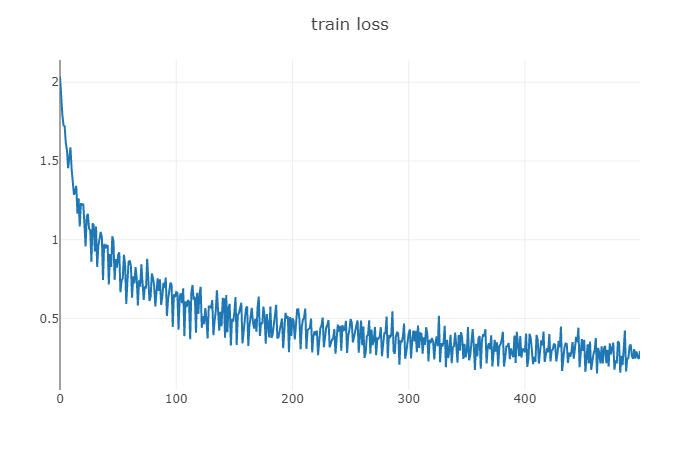
loss值 epoch:100 | batch: 500 | loss:0.294
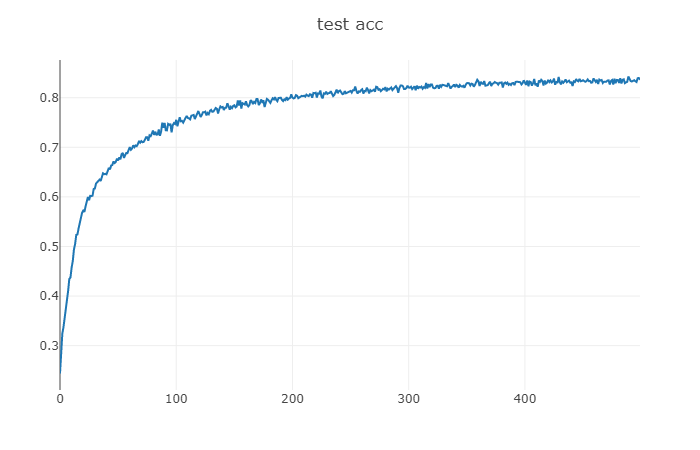
test acc epoch: 100 test acc: 0.8363
5、网络结构
ResNet(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(layer1): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResidualBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResidualBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shotcut): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResidualBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shotcut): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResidualBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AvgPool2d(kernel_size=8, stride=8, padding=0)
(fc): Linear(in_features=64, out_features=10, bias=True)
)
Pytorch1.0入门实战三:ResNet实现cifar-10分类,利用visdom可视化训练过程的更多相关文章
- Pytorch1.0入门实战二:LeNet、AleNet、VGG、GoogLeNet、ResNet模型详解
LeNet 1998年,LeCun提出了第一个真正的卷积神经网络,也是整个神经网络的开山之作,称为LeNet,现在主要指的是LeNet5或LeNet-5,如图1.1所示.它的主要特征是将卷积层和下采样 ...
- 用pytorch1.0搭建简单的神经网络:进行多分类分析
用pytorch1.0搭建简单的神经网络:进行多分类分析 import torch import torch.nn.functional as F # 包含激励函数 import matplotlib ...
- 大规模数据分析统一引擎Spark最新版本3.3.0入门实战
@ 目录 概述 定义 Hadoop与Spark的关系与区别 特点与关键特性 组件 集群概述 集群术语 部署 概述 环境准备 Local模式 Standalone部署 Standalone模式 配置历史 ...
- DL Practice:Cifar 10分类
Step 1:数据加载和处理 一般使用深度学习框架会经过下面几个流程: 模型定义(包括损失函数的选择)——>数据处理和加载——>训练(可能包括训练过程可视化)——>测试 所以自己写代 ...
- Pytorch1.0入门实战一:LeNet神经网络实现 MNIST手写数字识别
记得第一次接触手写数字识别数据集还在学习TensorFlow,各种sess.run(),头都绕晕了.自从接触pytorch以来,一直想写点什么.曾经在2017年5月,Andrej Karpathy发表 ...
- vue3.0入门(三)
前言 最近在b站上学习了飞哥的vue教程 学习案例已上传,下载地址 class绑定 对象绑定 :class='{active:isActive}' // 相当于class="active&q ...
- Spring3.0 入门进阶(三):基于XML方式的AOP使用
AOP是一个比较通用的概念,主要关注的内容用一句话来说就是"如何使用一个对象代理另外一个对象",不同的框架会有不同的实现,Aspectj 是在编译期就绑定了代理对象与被代理对象的关 ...
- springboot2.0入门(三)----定义编程风格+jackjson使用+postMan测试
一.RESTFul风格API 1.优点: )看Url就知道要什么资源 )看http method就知道针对资源干什么 )看http status code就知道结果如何 HTTP方法体现对资源的操作: ...
- word2vec 入门(三)模型介绍
两种模型,两种方法 模型:CBOW和Skip-Gram 方法:Hierarchical Softmax和Negative Sampling CBOW模型Hierarchical Softmax方法 C ...
随机推荐
- 自动生成SSM框架
使用idea 新创建项目 然后 新创建 java .resources 文件夹...... 图上是项目结构 java文件夹下的 文件夹 命名规范 com.nf147(组织名)+ oukele(作者) ...
- linux命令集锦 基于centos7---优化linux的命令
sed -i ‘s###g’ /etc/selinux/config 3个# 用于更改selinux配置文件:sed -i 's#SELINUX=enforcing#SELINUX=disabled ...
- 基于LVM 测试磁盘写性能.md
准备工作 /dev/sdb 创建一个卷组,基于卷组创建5个逻辑卷,各100G 在10.10.88.214 新建5台虚拟机,每台虚拟机用到lvm建的逻辑卷 dd 压测 在每台虚拟机上执行dd 命令: d ...
- 题解 【NOI2015】软件包管理器
题面 解析 事实上,这应该是道树剖裸题了, 将已安装表示为\(1\), 那么只需要在线段树中记录一下区间中\(1\)的个数就行了. 在询问的时候, 如果是安装,就查询\(x\)到根节点, 卸载的话,就 ...
- B/S文件夹上传下载组件
在Web应用系统开发中,文件上传和下载功能是非常常用的功能,今天来讲一下JavaWeb中的文件上传和下载功能的实现. 先说下要求: PC端全平台支持,要求支持Windows,Mac,Linux 支持所 ...
- luogu p4141 消失之物(背包dp+容斥原理)
题目传送门 昨天晚上学长讲了这题,说是什么线段树分治,然后觉得不可做,但那还不是正解,然后感觉好像好难的样子. 由于什么鬼畜的分治不会好打,然后想了一下$O(nm)$的做法,想了好长时间觉得这题好像很 ...
- CUDA-F-2-1-CUDA编程模型概述2
Abstract: 本文继续上文介绍CUDA编程模型关于核函数以及错误处理部分 Keywords: CUDA核函数,CUDA错误处理 开篇废话 今天的废话就是人的性格一旦形成,那么就会成为最大的指向标 ...
- sh_18_字符串文本对齐
sh_18_字符串文本对齐 # 假设:以下内容是从网络上抓取的 # 要求:顺序并且居中对齐输出以下内容 poem = ["\t\n登鹳雀楼", "王之涣", & ...
- js的5种继承方式——前端面试
js主要有以下几种继承方式:对象冒充,call()方法,apply()方法,原型链继承以及混合方式.下面就每种方法就代码讲解具体的继承是怎么实现的. 1.继承第一种方式:对象冒充 function P ...
- 尚学堂requireJs课程---1、作用域回顾
尚学堂requireJs课程---1.作用域回顾 一.总结 一句话总结: 尚学堂的课程的资料他的官网上面是有的 1.js作用域? ~ js中是函数作用域:局部变量的话要写var关键词 ~ 闭包可以解决 ...