[Scikit-learn] *2.3 Clustering - DBSCAN: Density-Based Spatial Clustering of Applications with Noise
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN
From: Brian Kent: Density Based Clustering in Python


聚类演示:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
print(__doc__) import numpy as np from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler # #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0) X = StandardScaler().fit_transform(X) # #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_ # Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels)) # #############################################################################
# Plot result
import matplotlib.pyplot as plt # Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1] class_member_mask = (labels == k) xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14) xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6) plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
Result:

补充,一个效果同样好的算法:Level Set Tree
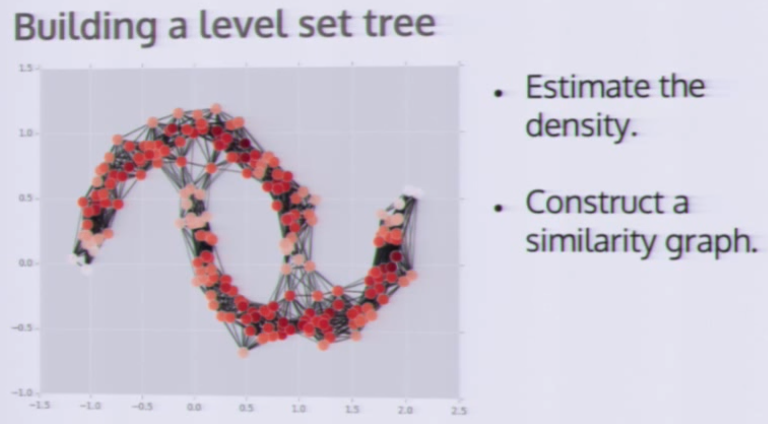
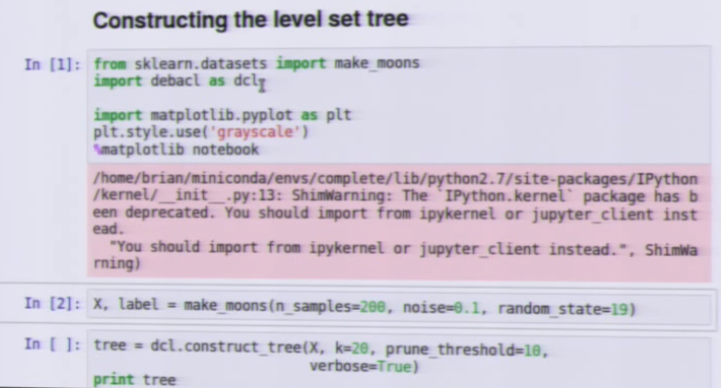
加载方式:
import debacl as dcl
[Scikit-learn] *2.3 Clustering - DBSCAN: Density-Based Spatial Clustering of Applications with Noise的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- DBSCAN(Density-based spatial clustering of applications with noise)
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Direction of Arrival Based Spatial Covariance Model for Blind Sound Source Separation
基于信号协方差模型DOA的盲声源分离[1]. 在此基础上,作者团队于2018年又发布了一篇文章,采用分级和时间差的空间协方差模型及非负矩阵分解的多通道盲声源分离[2]. 摘要 本文通过对短时傅立叶变换 ...
- Clustering by density peaks and distance
这次介绍的是Alex和Alessandro于2014年发表在的Science上的一篇关于聚类的文章[13],该文章的基本思想很简单,但是其聚类效果却兼具了谱聚类(Spectral Clustering ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
随机推荐
- 【转】5种网络IO模型
5种网络IO模型(有图,很清楚) IO多路复用—由Redis的IO多路复用yinch Linux中对文件描述符的操作(FD_ZERO.FD_SET.FD_CLR.FD_ISSET
- 说一下 atomic 的原理?(未完成)
说一下 atomic 的原理?(未完成)
- Python基础之While循环
一.摘要 本片博文将介绍input()函数和while循环的使用 二.input()函数 函数input() 让程序暂停运行,等待用户输入一些文本.获取用户输入后,Python将其存储在一个变量中,以 ...
- Task.Run 和 Task.Factory.StartNew 区别
Task.Run 是在 dotnet framework 4.5 之后才可以使用, Task.Factory.StartNew 可以使用比 Task.Run 更多的参数,可以做到更多的定制. 可以认为 ...
- request.querystring和request.form的区别
1,request.querystring和request.form的区别 request.querystring是用来接收地址里面问号“?”后面的参数的内容, 用get方法读取的 不安全 requ ...
- confluent_kafka消费时内存泄漏
confluent_kafka测试的内存泄漏的条件 多线程消费 centos6 预测和centos6底层库存在关系. 换用centos7(我是换了7.3)就行了. (起初以为是代码问题,定位问题位置后 ...
- Ubuntu Linux虚拟机与windows快速创建共享文件夹
有时候我们需要在windows下与远程Linux服务器传输文件,之前使用pscp传输文件很方便,但不方便传输多文件,同时也不便于查看.看了网上的教程总结创建共享文件夹的流程: 1.首先在本地windo ...
- Luogu SP839 OPTM - Optimal Marks(按位最小割)
这道题和 BZOJ 2400 是一道题,不多讲了 CODE #include <cstdio> #include <cstring> #include <vector&g ...
- 【vue】vue-cli中 对于public文件夹的处理
pubcli和assets文件夹都是用来存储静态资源的,: [assets文件夹] 通过相对路径被引入,这类引用会被webpack处理: 比如: 会被编译成: 再比如: 会被编译成: [public文 ...
- VS2012 Update 2: 0x80040154 corrupt install when starting the debugger
使用VS2012開發console program ,发现生成32位的exe文件在別的机上不能正确运行,有文章說update1可以解決這個問題,如下 Setup.exe is not a valid ...