NLP传统基础(3)---潜在语义分析LSA主题模型---SVD得到降维矩阵
https://www.jianshu.com/p/9fe0a7004560
一、简单介绍
LSA和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系;不同的是,LSA 将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。
二、文本挖掘的两个方面应用
(1)分类:
a.将词汇表中的字词按意思归类(比如将各种体育运动的名称都归成一类)
b.将文本按主题归类(比如将所有介绍足球的新闻归到体育类)
(2)检索:用户提出提问式(通常由若干个反映文本主题的词汇组成),然后系统在数据库中进行提问式和预存的文本关键词的自动匹配工作,两者相符的文本被检出。
三、文本分类中出现的问题
(1)一词多义
比如bank 这个单词如果和mortgage, loans, rates 这些单词同时出现时,bank 很可能表示金融机构的意思。可是如果bank 这个单词和lures, casting, fish一起出现,那么很可能表示河岸的意思。
(2)一义多词
比如用户搜索“automobile”,即汽车,传统向量空间模型仅仅会返回包含“automobile”单词的页面,而实际上包含“car”单词的页面也可能是用户所需要的。
四、LSA原理
通过对大量的文本集进行统计分析,从中提取出词语的上下文使用含义。技术上通过SVD分解等处理,消除了同义词、多义词的影响,提高了后续处理的精度。
流程:
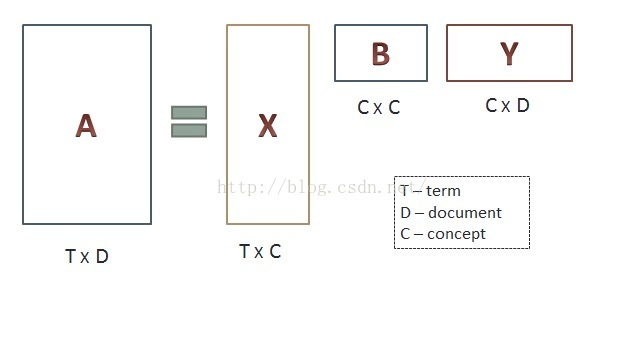
(1)分析文档集合,建立词汇-文本矩阵A。
(2)对词汇-文本矩阵进行奇异值分解。
(3)对SVD分解后的矩阵进行降维
(4)使用降维后的矩阵构建潜在语义空间
五、应用
低维的语义空间可以用于以下几个方面:
在低维语义空间可对文档进行比较,进而可用于文档聚类和文档分类。
在翻译好的文档上进行训练,可以发现不同语言的相似文档,可用于跨语言检索。
发现词与词之间的关系,可用于同义词、歧义词检测。.
通过查询映射到语义空间,可进行信息检索。
从语义的角度发现词语的相关性,可用于“选择题回答模型”(multi choice qustions answering model)。
六、LSA的优点
1)低维空间表示可以刻画同义词,同义词会对应着相同或相似的主题。
2)降维可去除部分噪声,是特征更鲁棒。
3)充分利用冗余数据。
4)无监督/完全自动化。
5)与语言无关。
七、LSA的缺点
1)LSA可以处理向量空间模型无法解决的一义多词(synonymy)问题,但不能解决一词多义(polysemy)问题。因为LSA将每一个词映射为潜在语义空间中的一个点,也就是说一个词的多个意思在空间中对于的是同一个点,并没有被区分。
2)SVD的优化目标基于L-2 norm 或者 Frobenius Norm 的,这相当于隐含了对数据的高斯分布假设。而 term 出现的次数是非负的,这明显不符合 Gaussian 假设,而更接近 Multi-nomial 分布。
3)特征向量的方向没有对应的物理解释。
4)SVD的计算复杂度很高,而且当有新的文档来到时,若要更新模型需重新训练。
5)没有刻画term出现次数的概率模型。
6)对于count vectors 而言,欧式距离表达是不合适的(重建时会产生负数)。
7)维数的选择是ad-hoc的。
8)LSA具有词袋模型的缺点,即在一篇文章,或者一个句子中忽略词语的先后顺序。
9)LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布的。因此LSA算法的一个改进PLSA使用了多项分布,其效果要好于LSA。
NLP传统基础(3)---潜在语义分析LSA主题模型---SVD得到降维矩阵的更多相关文章
- NLP传统基础(2)---LDA主题模型---学习文档主题的概率分布(文本分类/聚类)
一.简介 https://cloud.tencent.com/developer/article/1058777 1.LDA是一种主题模型 作用:可以将每篇文档的主题以概率分布的形式给出[给定一篇文档 ...
- 潜在语义分析 LSA
简单介绍 LSA和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系:不同的是, ...
- NLP传统基础(1)---BM25算法---计算文档和query相关性
一.简介:TF-IDF 的改进算法 https://blog.csdn.net/weixin_41090915/article/details/79053584 bm25 是一种用来评价搜索词和文档之 ...
- 文本主题模型之潜在语义索引(LSI)
在文本挖掘中,主题模型是比较特殊的一块,它的思想不同于我们常用的机器学习算法,因此这里我们需要专门来总结文本主题模型的算法.本文关注于潜在语义索引算法(LSI)的原理. 1. 文本主题模型的问题特点 ...
- 主题模型之潜在语义分析(Latent Semantic Analysis)
主题模型(Topic Models)是一套试图在大量文档中发现潜在主题结构的机器学习模型,主题模型通过分析文本中的词来发现文档中的主题.主题之间的联系方式和主题的发展.通过主题模型可以使我们组织和总结 ...
- 主题模型之概率潜在语义分析(Probabilistic Latent Semantic Analysis)
上一篇总结了潜在语义分析(Latent Semantic Analysis, LSA),LSA主要使用了线性代数中奇异值分解的方法,但是并没有严格的概率推导,由于文本文档的维度往往很高,如果在主题聚类 ...
- NLP&数据挖掘基础知识
Basis(基础): SSE(Sum of Squared Error, 平方误差和) SAE(Sum of Absolute Error, 绝对误差和) SRE(Sum of Relative Er ...
- Latent Semantic Analysis (LSA) Tutorial 潜语义分析LSA介绍 一
Latent Semantic Analysis (LSA) Tutorial 译:http://www.puffinwarellc.com/index.php/news-and-articles/a ...
- 用Python做SVD文档聚类---奇异值分解----文档相似性----LSI(潜在语义分析)
转载请注明出处:电子科技大学EClab——落叶花开http://www.cnblogs.com/nlp-yekai/p/3848528.html SVD,即奇异值分解,在自然语言处理中,用来做潜在语义 ...
随机推荐
- ubuntu desktop 登录root账户
有一些操作,登录root账户比较方便,但是ubuntu桌面版默认不允许这样,需要更改root账户的默认密码才可以登录,解决方法是按以下顺序输入: sudo passwd <你现在的用户的密码&g ...
- Codis-proxy的配置和启动
生成配置文件,即将现有的配置文件输出到指定目录位置: ./codis-proxy --default-config | tee conf/proxy.toml 修改配置文件信息: vi conf/pr ...
- python变量 - python基础入门(6)
何为python变量,即数据类型.python变量一共六种类型:整数/浮点数/字符串/BOOL/列表/元组/字典,今天先讲解前四种,后三种留到后面的文章在讲解. 首先讲解print() 函数,prin ...
- 事务的ACID
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚. 简单地说,事务提 ...
- Jmeter 跨线程组传递参数 之两种方法(转)
终于搞定了Jmeter跨线程组之间传递参数,这样就不用每次发送请求B之前,都需要同时发送一下登录接口(因为同一个线程组下的请求是同时发送的),只需要发送一次登录请求,请求B直接用登录请求的参数即可,直 ...
- ftp操作命令
原文:https://www.cnblogs.com/tssc/p/9593614.html 1.登陆ftp服务器 ftp [IP] [PORT] # 登陆ftp服务器,本机登陆可以不写IP实例演示: ...
- Linux-BSP-驱动-面试题大全
1. 了解Linux的那个驱动?举例讲讲. a.驱动注册过程:通过platform bus, platform_device_register和platform_driver_register时都会在 ...
- Thinking In Java 4th Chap6 访问权限控制
引入一个包及其所包含的方法:import java.util.ArrayList;(引入java.util包,并引入了包中的ArrayList类) import java.util.*;(引入了jav ...
- Windows 下redis的安装和使用
1.下载 Window 下载地址:https://github.com/MSOpenTech/redis/releases 查找版本对应的一个MSI或者zip文件下载 2.安装 MSI文件需要安装 z ...
- docker 实践二:操作镜像
本篇我们来详细介绍 docker 镜像的操作. 注:环境为 CentOS7,docker 19.03 之前已经说过,容器是 docker 的核心概念之一,所以对应的就需要知道它的使用方法,接下来我们就 ...