Python学习笔记:序列构成的数组
列表推导是一种构建列表(list)的快捷方式
#列表推导
symbols = '!@#$%'
codes = [ord(symbol) for symbol in symbols] #ord()Python内置函数,将字符变成Unicode码位,返回值为对应十进制
print(codes)

列表推导同filter()和map()比较
"""
1.fitter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
语法:
filter(function, iterable)
参数:
function -- 判断函数
iterable -- 可迭代对象 2.map()函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法:
map(function, iterable, ...)
参数:
function -- 函数
iterable -- 一个或多个序列 3.lambda函数是一个简短的匿名函数,可以接收任意数量的参数,但只能包含一个表达式。
语法:
lambda 参数:表达式
"""
symbols = '!@#$%'
codes = [ord(symbol) for symbol in symbols if ord(symbol) > 50]
print(codes) codes = list(filter(lambda c: c > 50, map(ord, symbols)))
print(codes)

笛卡尔积:用列表推导可以生成两个或以上的可迭代类型的笛卡儿积。笛卡儿积是一个列表,列表里的元素是由输入的可迭代类型的元素对构成的元组,因此笛卡儿积列表的长度等于输入变量的长度的乘积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirt = [(color, size) for color in colors for size in sizes]
print(tshirt) tshirt = [ ]
for color in colors:
for size in sizes:
tshirt.append((color, size))
print(tshirt) tshirts = [(color, size) for size in sizes
for color in colors]
print(tshirts)

虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。前面那种方式显然能够节省内存。生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
#用生成器表达式初始化元组和数组
symbols = '!@#$%'
codes = tuple(ord(symbol) for symbol in symbols)
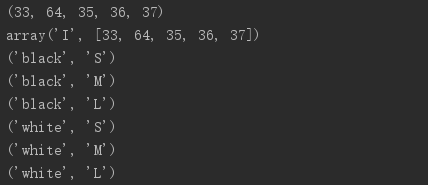
print(codes) import array
arr = array.array('I', (ord(symbol) for symbol in symbols))
print(arr) #使用生成器表达式计算笛卡尔积
colors = ['black', 'white']
sizes = ['S', 'M', 'L'] # '%s'%表示格式化一个对象为字符
for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
print(tshirt)
—————————————————————————————————————————————————————————
元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非我们用 * 来表示忽略多余的元素。
#元组拆包: 平行赋值,也就是说把一个可迭代对象里的元素,一并赋值到由对应的变量组成的元组中
alpha_num = ('a', 97)
alpha, num = alpha_num
print(alpha, num) #不使用中间变量交换两个变量的值
a = 'a'
b = 97
b, a = a, b
print(a, b) #用 * 运算符把一个可迭代对象拆开作为函数的参数
print(divmod(20, 8))#divmod(a, b)函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
t = (20, 8)
print(divmod(*t)) #让一个函数可以用元组的形式返回多个值
import os
_, filename = os.path.split('test.txt')#函数返回路径和文件名
print(filename) #用*来处理剩下的元素
a, b, *rest = range(5)
print(a, b, rest)
#在平行赋值中,* 前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置
a, *body, c, d = range(5)
print(a, body, c, d)

#嵌套元组拆包
alpha_a = [('a', 'A', (97, 65))]
for small, capital, (num_small, num_capital) in alpha_a:
print(num_small, num_capital) #具名元组collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类
#创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。
from collections import namedtuple
Country_Capital = namedtuple('c_c', 'country capital')
comb = Country_Capital('China', 'Beijing')
print(comb) #具名元组还有一些自己专有的属性。中就展示了几个最有用的:_fields 类属性、类方法 _make(iterable) 和实例方法_asdict()。
#_fields 属性是一个包含这个类所有字段名称的元组,
#用 _make() 通过接受一个可迭代对象来生成这个类的一个实例,它的作用跟City(*delhi_data) 是一样的。
#_asdict() 把具名元组以 collections.OrderedDict 的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。
print(Country_Capital._fields)
print(Country_Capital._make(comb))
print(comb._asdict())
for key, value in comb._asdict().items():
print(key + ':', value)

——————————————————————————————————————————————————————
Python学习笔记:序列构成的数组的更多相关文章
- Python学习笔记3-Python元组、数组、字典集合的操作
在Python中数组中的每一项可以是不同的数据类型 元组:只能读不能写的数组 aTuple=(1,'abc','tmc',79.0,False) print aTuple[1:3] print typ ...
- Python学习笔记(1)——数组差集
面试的时候被问到这样一个问题:有A.B两个数组,找出B中有A中没有的所有元素(换言之即是求差集B-A).当时比较紧张,用了最原始的双重嵌套循环逐个比较,很显然这种时间复杂度高达O(n2)的算法相当lo ...
- python学习笔记:数据类型——列表/数组(list)
Python内置的一种数据类型是列表:list.list是一种有序的集合,可以随时添加和删除其中的元素.通过下标访问列表中的元素(又称索引.角标),下标从0开始计数.list定义,使用中括号[]. l ...
- Python学习笔记_二维数组的查找判断
在进行数据处理的工作中,有时只是通过一维的list和有一个Key,一个value组成的字典,仍无法满足使用,比如,有三列.或四列,个数由不太多. 举一个现实应用场景:学号.姓名.手机号,可以再加元素 ...
- Python学习笔记----序列共性
序列操作符 作用seq[ind] 获得下标为ind 的元素seq[ind1:ind2] 获得下标从ind1 到ind2 间的元素集合seq * expr 序列重复expr 次seq1 + seq2 连 ...
- Python 学习笔记之 Numpy 库——数组基础
1. 初识数组 import numpy as np a = np.arange(15) a = a.reshape(3, 5) print(a.ndim, a.shape, a.dtype, a.s ...
- python学习笔记(一)元组,序列,字典
python学习笔记(一)元组,序列,字典
- python学习笔记(一)、列表和元祖
该一系列python学习笔记都是根据<Python基础教程(第3版)>内容所记录整理的 1.通用的序列操作 有几种操作适用于所有序列,包括索引.切片.相加.相乘和成员资格检查.另外,Pyt ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化 循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息. ...
随机推荐
- C语言Ⅰ博客作业11
这个作业属于那个课程 C语言程序设计II 这个作业要求在哪里 https://edu.cnblogs.com/campus/zswxy/CST2019-3/homework/10130 我在这个课程的 ...
- Spring Boot + Vue 跨域请求问题
使用Spring Boot + Vue 做前后端分离项目搭建,实现登录时,出现跨域请求 Access to XMLHttpRequest at 'http://localhost/open/login ...
- 啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建
一.新增一个普通用户bigdata
- C++中枚举类型的作用
(1)C++中会使用const或者#define定义整型常量,当整型常量有多个且之间的值的全部或部分有递加的时候,定义起来稍显繁琐,此时用枚举类型显得很简洁: 例如: //使用const: const ...
- Promethus+Grafana监控解决方案
[MySQL]企业级监控解决方案Promethus+Grafana Promethus用作监控数据采集与处理,而Grafana只是用作数据展示 一.Promethus简介 Prometheus(普罗米 ...
- 欧拉函数小结 hdu2588+
从费马小定理到欧拉定理 欧拉公式 再到欧拉函数.,. 小结一下欧拉函数吧 对正整数n,欧拉函数是小于n的正整数中与n互质的数的数目(φ(1)=1)----定义 欧拉函数的基本公式其中pi为x的素因子 ...
- React学习——子组件给父组件传值
//子组件 var Child = React.createClass({ render: function(){ return ( <div> 请输入邮箱:<input onCha ...
- day06 Python class基础篇
一.目录 1.类与对象的概述 2.封装 3.继承 4.多态 5.类的成员 6.类与类之间的关系 7.私有 二. 内容讲解 一.类与对象的概述 类是对一系列具有相同属性的事物的抽象,相同于设计图纸,而对 ...
- vscode快捷操作
Ctrl + ` 打开或关闭终端 Ctrl + Shift + n 打开或关闭新窗口 Ctrl + Shift + f 打开视图,显示编辑器左侧 ...
- maven 父子工程打包 并且上传linux服务器
先对父工程进行 mvn clean 再对子工程执行 install wagon:upload-single wagon:sshexec 使用wagon前提: 本地maven 的settings.xml ...