HashMap之Hash碰撞源码解析
转自:https://blog.csdn.net/luo_da/article/details/77507315
https://www.cnblogs.com/tongxuping/p/8276198.html
HashMap是最常用的集合类框架之一,它实现了Map接口,所以存储的元素也是键值对映射的结构,并允许使用null值和null键,其内元素是无序的,如果要保证有序,可以使用LinkedHashMap。HashMap是线程不安全的,下篇文章会讨论。HashMap的类关系如下:
java.util
Class HashMap<K,V>
java.lang.Object
|--java.util.AbstractMap<K,V>
|--java.util.HashMap<K,V>
所有已实现的接口:
Serializable,Cloneable,Map<K,V>
直接已知子类:
LinkedHashMap,PrinterStateReasons
HashMap中用的最多的方法就属put() 和 get() 方法;HashMap的Key值是唯一的,那如何保证唯一性呢?我们首先想到的是用equals比较,没错,这样可以实现,但随着内部元素的增多,put和get的效率将越来越低,这里的时间复杂度是O(n),假如有1000个元素,put时最差情况需要比较1000次。实际上,HashMap很少会用到equals方法,因为其内通过一个哈希表管理所有元素,哈希是通过hash单词音译过来的,也可以称为散列表,哈希算法可以快速的存取元素,当我们调用put存值时,HashMap首先会调用Key的hash方法,计算出哈希码,通过哈希码快速找到某个存放位置(桶),这个位置可以被称之为bucketIndex,但可能会存在多个元素找到了相同的bucketIndex,有个专业名词叫碰撞,当碰撞发生时,这时会取到bucketIndex位置已存储的元素,最终通过equals来比较,equals方法就是碰撞时才会执行的方法,所以前面说HashMap很少会用到equals。HashMap通过hashCode和equals最终判断出Key是否已存在,如果已存在,则使用新Value值替换旧Value值,并返回旧Value值,如果不存在 ,则存放新的键值对<K, V>到bucketIndex位置。通过下面的流程图来梳理一下整个put过程。
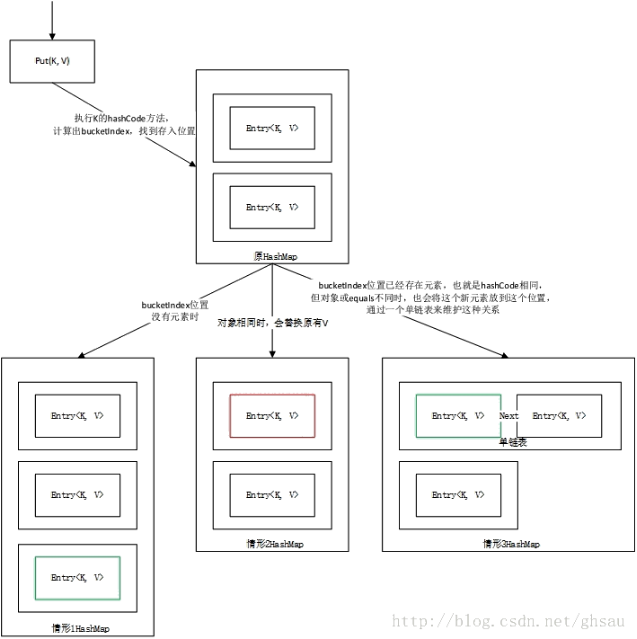
最终HashMap的存储结构会有这三种情况,我们当然期望情形3是最少发生的(效率最低)。
HashMap 碰撞问题处理:
碰撞:所谓“碰撞”就上面所述是多个元素计算得出相同的hashCode,在put时出现冲突。
处理方法:
Java中HashMap是利用“拉链法”处理HashCode的碰撞问题。在调用HashMap的put方法或get方法时,都会首先调用hashcode方法,去查找相关的key,当有冲突时,再调用equals方法。hashMap基于hasing原理,我们通过put和get方法存取对象。当我们将键值对传递给put方法时,他调用键对象的hashCode()方法来计算hashCode,然后找到bucket(哈希桶)位置来存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap在每个链表节点存储键值对对象。当两个不同的键却有相同的hashCode时,他们会存储在同一个bucket位置的链表中。键对象的equals()来找到键值对。
HashMap基本结构概念图:
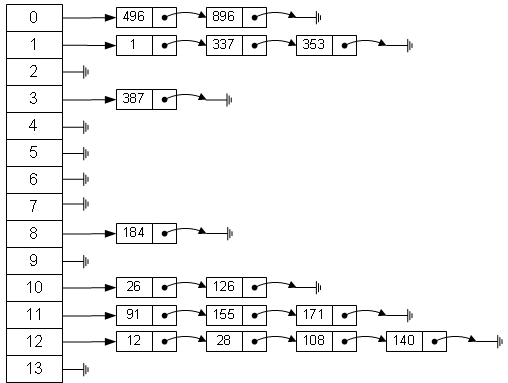
到目前为止,我们了解了两件事:
1、HashMap通过键的hashCode来快速的存取元素。
2、当不同的对象发生碰撞时,HashMap通过单链表来解决,将新元素加入链表表头,通过next指向原有的元素。单链表在Java中的实现就是对象的引用(复合)。
HashMap.put()和get()源码:
/**
* Returns the value to which the specified key is mapped,
* or if this map contains no mapping for the key.
*
* 获取key对应的value
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
//获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} /**
* Offloaded version of get() to look up null keys. Null keys map
* to index 0.
* 获取key为null的键值对,HashMap将此键值对存储到table[0]的位置
*/
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
} /**
* Returns <tt>true</tt> if this map contains a mapping for the
* specified key.
*
* HashMap是否包含key
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
} /**
* Returns the entry associated with the specified key in the
* HashMap.
* 返回键为key的键值对
*/
final Entry<K,V> getEntry(Object key) {
//先获取哈希值。如果key为null,hash = 0;这是因为key为null的键值对存储在table[0]的位置。
int hash = (key == null) ? 0 : hash(key.hashCode());
//在该哈希值对应的链表上查找键值与key相等的元素。
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} /**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* 将“key-value”添加到HashMap中,如果hashMap中包含了key,那么原来的值将会被新值取代
*/
public V put(K key, V value) {
//如果key是null,那么调用putForNullKey(),将该键值对添加到table[0]中
if (key == null)
return putForNullKey(value);
//如果key不为null,则计算key的哈希值,然后将其添加到哈希值对应的链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果这个key对应的键值对已经存在,就用新的value代替老的value。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} modCount++;
addEntry(hash, key, value, i);
return null;
}
从HashMap的put()和get方法实现中可以与拉链法解决hashCode冲突解决方法相互印证。并且从put方法中可以看出HashMap是使用Entry<K,V>来存储数据。
Java8碰撞优化提升
为什么会有这么大的性能提升,尽管这里用的是大O符号(大O描述的是渐近上界)?其实这个优化在JEP-180中已经提到了。如果某个桶中的记录过大的话(当前是TREEIFY_THRESHOLD = 8),HashMap会动态的使用一个专门的treemap实现来替换掉它。这样做的结果会更好,是O(logn),而不是糟糕的O(n)。它是如何工作的?前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。但是超过这个阈值后HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。这个性能提升有什么用处?比方说恶意的程序,如果它知道我们用的是哈希算法,它可能会发送大量的请求,导致产生严重的哈希碰撞。然后不停的访问这些key就能显著的影响服务器的性能,这样就形成了一次拒绝服务攻击(DoS)。JDK 8中从O(n)到O(logn)的飞跃,可以有效地防止类似的攻击,同时也让HashMap性能的可预测性稍微增强了一些。
HashMap之Hash碰撞源码解析的更多相关文章
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(7) ---Distributed Hash之前向传播
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(7) ---Distributed Hash之前向传播 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务 ...
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- Local hash表
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- Local hash表 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(9)--- ...
- [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(8) ---Distributed Hash之后向传播
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器---(8) ---Distributed Hash之后向传播 目录 [源码解析] NVIDIA HugeCTR,GPU 版本参数服务 ...
- Java集合类源码解析:HashMap (基于JDK1.8)
目录 前言 HashMap的数据结构 深入源码 两个参数 成员变量 四个构造方法 插入数据的方法:put() 哈希函数:hash() 动态扩容:resize() 节点树化.红黑树的拆分 节点树化 红黑 ...
- Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap
声明:以下源代码使用的都是基于JDK1.8_112版本 1. ArrayList源码解析 <1. 集合中存放的依然是对象的引用而不是对象本身,且无法放置原生数据类型,我们需要使用原生数据类型的包 ...
- java容器三:HashMap源码解析
前言:Map接口 map是一个存储键值对的集合,实现了Map接口的主要类有以下几种 TreeMap:用红黑树实现 HashMap:数组和链表实现 HashTable:与HashMap类似,但是线程安全 ...
- 一、基础篇--1.2Java集合-HashMap源码解析
https://www.cnblogs.com/chengxiao/p/6059914.html 散列表 哈希表是根据关键码值而直接进行访问的数据结构.也就是说,它能通过把关键码值映射到表中的一个位 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- HashMap源码解析和设计解读
HashMap源码解析 想要理解HashMap底层数据的存储形式,底层原理,最好的形式就是读它的源码,但是说实话,源码的注释说明全是英文,英文不是非常好的朋友读起来真的非常吃力,我基本上看了差不多 ...
随机推荐
- php 随机生成汉字
function getChar($num) // $num为生成汉字的数量 { $b = ''; for ($i=0; $i<$num; $i++) { // 使用chr()函数拼接双字节汉字 ...
- 【快学springboot】SpringBoot整合Mybatis Plus
原创声明 本文首发于头条号[Happyjava].Happy的掘金地址:https://juejin.im/user/5cc2895df265da03a630ddca,Happy的个人博客:http: ...
- Atcoder Beginner Contest 140E(多重集,思维)
#define HAVE_STRUCT_TIMESPEC#include<bits/stdc++.h>using namespace std;multiset<long long&g ...
- PullToRefreshScrollView刷新图标和字体的设定
首先添加pullrefresh的libaraly 设置下拉刷新上拉加载时的文本和图片,直接在java代码中添加 mPullToRefreshScrollView.getLoadingLayoutPro ...
- Linux三剑客之awk精讲(基础与进阶)
第1章 awk基础入门 要弄懂awk程序,必须熟悉了解这个工具的规则.本实战笔记的目的是通过实际案例或面试题带同学们熟练掌握awk在企业中的用法,而不是awk程序的帮助手册. 1.1 awk简介 一种 ...
- Linux centosVMware LNMP架构介绍、MySQL安装、PHP安装、Nginx介绍
一. LNMP架构介绍 和LAMP不同的是,提供web服务的是Nginx 并且php是作为一个独立服务存在的,这个服务叫做php-fpm Nginx直接处理静态请求,动态请求会转发给php-fpm ...
- CentOS7中Tomcat的安装和配置
Tomcat运行需要设置JRE目录,全局变量配置,请参见: Linux下JDK的安装和配置 当然也可以直接修改Tomcat的配置文件,请自行度娘 1.下载并解压 请先去官网找到需要下载的tom ...
- npm和npx
npx 指令会先在项目的node_modules里面找资源包 npm info 包名称 [查看资源包的信息]
- iis下发布MVC网站
1.首先检查有没有安装iis,没有的话先安装iis 2. 3.选择应用程序池的时候看有没有asp.net 4.0 如果没有先安装. 首先以管理员身份打开“运行”输入cd C:\Windows\Micr ...
- mysql将一个表拆分成多个表(一)(转载)
转载 直接根据数据量进行拆分 有一个5000条数据的表,要把它变成没1000条数据一个表的5等份. 假设:表名:xuesi 主键:kidxuesi共有5000条数据,kid从1到5000自动增长题目: ...