List<Object> 查询解析优化
2018年3月16日
大型仪器设备分类查出后,需要展示个分类下总共有多少台设备。因为分类总共分三层,加起来数据700+。以后该系统上线设备可能达到2000+,这样统计每个分类下的设备可能会拖垮服务器。
下面给出项目图片
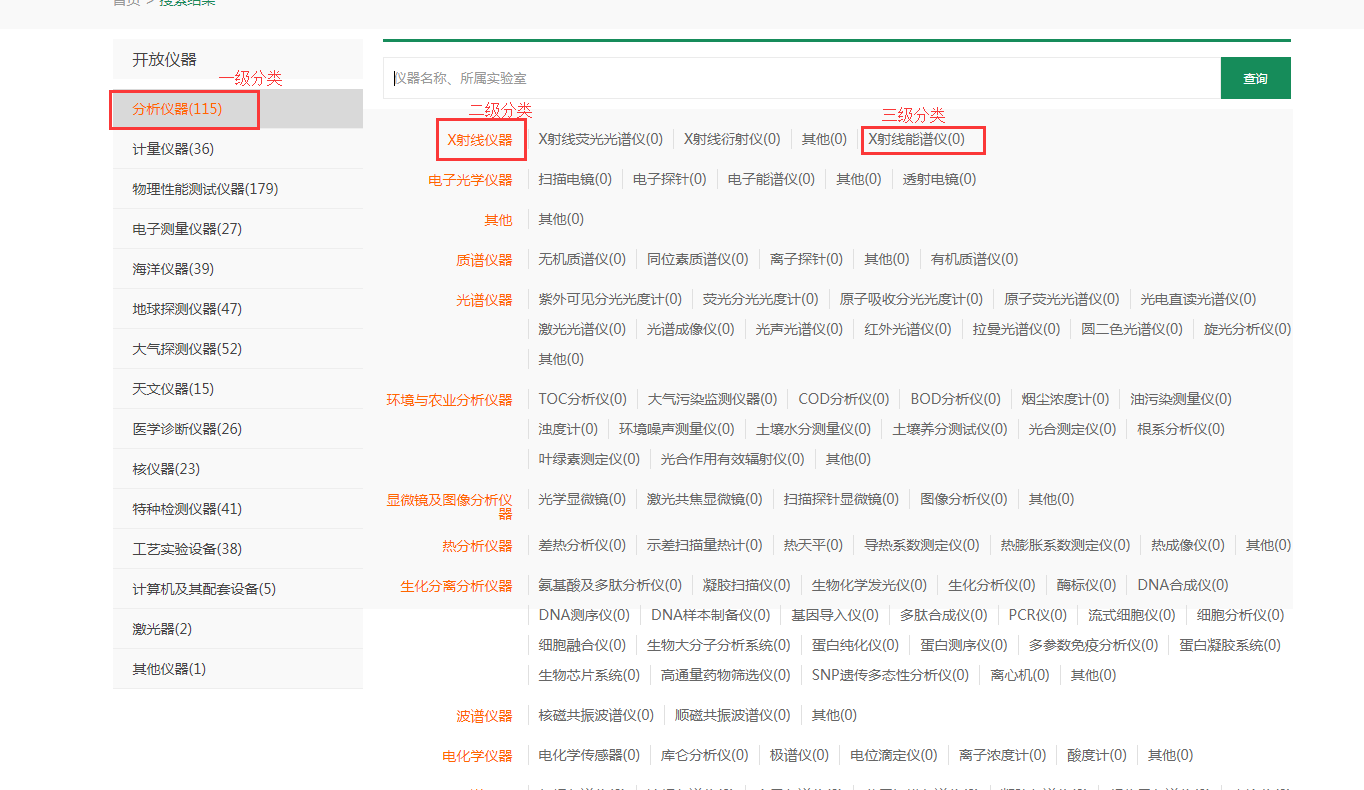
今天先把问题抛出来。 现在有两种方法解决:
1.根据每个分类查询所在分类下的所有设备仪器,这种方法不可行,分类就大概700+,每个都要查库非得崩了。
2.应该把所有设备都查询出来,然后把设备归到某些分类下。但,怎么把所有设备分到700+分类下呢?
2018年3月19日,早晨来了大概按着第二种方法写了代码,首先查出所有设备,每个设备一定是对应到第三级节点上面的,把所有设备加到第三级节点中,然后再通过第三级节点加到第二级节点,最后加到根节点。
第一步骤 首先查出所有的一级、二级、三级节点,分别放入到对应的map中,为了后期查询方便。
//取出根节点
categoryRootList = cmsInstrumentDaoImpl.getInstrumentClassRootData();
categoryRootSeedList = cmsInstrumentDaoImpl.getInstrumentClassRootSeedData();
categoryRootSeedSeedList = cmsInstrumentDaoImpl.getInstrumentClassRootSeedSeedData();
HashMap<String, CategoryBean> RootMap = new HashMap<String, CategoryBean>();
HashMap<String, CategoryBean> RootSeedMap = new HashMap<String, CategoryBean>();
HashMap<String, CategoryBean> RootSeedSeedMap = new HashMap<String, CategoryBean>();
//把所有根节点都放入map中
for(CategoryBean categoryBeanRoot : categoryRootList){
categoryBeanRoot.setList_i(new ArrayList<CategoryBean>());
RootMap.put(categoryBeanRoot.getParents(), categoryBeanRoot);
}
//把所有二级节点都放入map中
for(CategoryBean categoryBean_i : categoryRootSeedList){
categoryBean_i.setList_ii(new ArrayList<CategoryBean>());
RootSeedMap.put(categoryBean_i.getParents(), categoryBean_i);
}
//查出所有的仪器设备,分别查出每个仪器的分类的parents,然后加到每个分类下。
for(CategoryBean categoryBean_ii : categoryRootSeedSeedList){
categoryBean_ii.setList_ii(new ArrayList<CategoryBean>());
RootSeedSeedMap.put(categoryBean_ii.getParents(), categoryBean_ii);
}
第二步骤 把查询到的所有设备放入第三级节点
List<EquipmentInfoBean> eqList = new ArrayList<EquipmentInfoBean>();
eqList = cmsInstrumentDaoImpl.getInstrumentSuosfl();
String suosfl_parents = "";
CategoryBean newcategoryBean = new CategoryBean();
for(EquipmentInfoBean eq : eqList){
suosfl_parents = eq.getSuosfl_parents();
//根据suosfl_parents 查询到的数据不为空则认为该设备属于此分类
if(RootSeedSeedMap.get(suosfl_parents) != null){
newcategoryBean = RootSeedSeedMap.get(suosfl_parents);
newcategoryBean.setRecver(newcategoryBean.getRecver()+1);
RootSeedSeedMap.put(suosfl_parents, newcategoryBean);
}
}
第三步骤 把三级节点获取的数据放到二级节点,把二级节点的数据放到一级节点
String parentsRootSeed = "";
CategoryBean categoryBean_i = new CategoryBean();
for(Entry<String, CategoryBean> entry : RootSeedSeedMap.entrySet()){
parentsRootSeed = entry.getValue().getParents().substring(0, categoryBean_ii_length-34);
//在map中找到对应的一级节点,将二级节点放入一级节点中
categoryBean_i = RootSeedMap.get(parentsRootSeed);
categoryBean_i.setRecver(categoryBean_i.getRecver() + entry.getValue().getRecver()); // 计算数字
categoryBean_i.getList_ii().add(entry.getValue());
}
// 拿出所有根节点进行遍历查出 查出每个根节点对应的二级节点
//TODO 二级节点的parents = 一级节点的parents + 00 + 二级节点的objectid或者resid
String parentsRoot = "";
CategoryBean categoryBean = new CategoryBean();
for(Entry<String, CategoryBean> entry : RootSeedMap.entrySet()){
parentsRoot = entry.getValue().getParents().substring(0, categoryBean_i_length-34);
//在map中找到对应的一级节点,将二级节点放入一级节点中
categoryBean = RootMap.get(parentsRoot);
categoryBean.setRecver(categoryBean.getRecver()+entry.getValue().getRecver()); //同上
categoryBean.getList_i().add(entry.getValue());
}
虽然是能查询出来,大概费事300ms 但是因为设备数量只有两个,我想数据量大时仍有待优化,后期如果有好想法再写出来
List<Object> 查询解析优化的更多相关文章
- Solr查询配置及优化【eDisMax查询解析器】
一.简介 Lucene查询解析器语法支持创建任意复杂的布尔查询,但还有一些缺点,它不是用户查询处理的理想解决方案.这里面最大的问题是Lucene查询解析器的语法要求严格,一旦破坏就会抛出异常.指望用户 ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- mysql笔记03 查询性能优化
查询性能优化 1. 为什么查询速度会慢? 1). 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减 ...
- SQL大量数据查询的优化 及 非用like不可时的处理方案
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- sql大数据量查询的优化技巧
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- MySql学习(七) —— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- Mysql常用30种SQL查询语句优化方法
出处:http://www.antscode.com/article/12deee70111da0c4.html 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使 ...
随机推荐
- PTA的Python练习题(三)
继续在PTA上编写Python的编程题. 从 第2章-11 求平方与倒数序列的部分和 开始 1. a,b=map(int,input().split()) s=0 while(a<=b): s= ...
- Java基础知识笔记第五章:子类与继承
子类与父类 子类 class 子类名 extends 父类名{ ....... } 类的树形结构 子类的继承性 子类和父类在同一包中的继承性 子类继承了父类不是private的成员属性和成员方法 ...
- Java基础知识笔记第二章:基本数据类型与数组
标识符和关键字 标识符: 1:字母,数字,下划线,美元符号 2.不能以数字开头 3.标识符不能是:true false null(尽管true false null不是java的关键字 ...
- 记录5-如何在UltraEdit中编译和运行Java
1点击“高级”,再点击“工具配置” 2点击“插入”,在“菜单项”名称上输入“编译java程序”,在“命令行”里输入“javac %n%e”,在工作目录上填“%p”. 3切换到“输出”项,选择“输出到列 ...
- HDU 5570:balls 期望。。。。。。。。。。。。。。。
balls Accepts: 19 Submissions: 55 Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/655 ...
- 实用类-<Math类常用>
Math.random() //取0~1之间的随机数(不包括1) Math.max(数字1,数字2) //取两个数中最大的一个 Math.min(数字1,数字2) //取两个数中最小的一个 Math. ...
- 使用 CocoaPods 遇到的问题记录
1. 在 Terminal 输入 Cocoapods 命令时,有时会一直等待,出现“Performing a deep fetch of the `master` specs repo to impr ...
- ie9下浏览器 cosole.log()会阻止j下面的s加载
ie9下浏览器 cosole.log()会阻止j下面的s加载,删掉多余的console.log().
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- vscode调试开发C/C++程序
https://www.cnblogs.com/TAMING/p/8560253.html