Linux 内核工作队列之work_struct 学习总结
前言
编写Linux驱动的时候对于work_struct的使用还是很普遍的,很早之前就在阅读驱动源码的时候就看到了它的踪影,根据其命名大概知道了它的具体作用,但是仍然不知所以,同时,伴随出现的还有delayed_work以及workqueue_struct,抱着知其然并知其所以然的态度,在这里归纳总结一下work_struct,以及如何在驱动中使用,因为工作队列相对来说比较复杂,篇幅和能力有限,只能介绍相对重要的部分。
workqueue
内核里一直运行类似worker thread,它会对工作队列中的work进行处理,大致的工作流程原理可以参考下图所示;
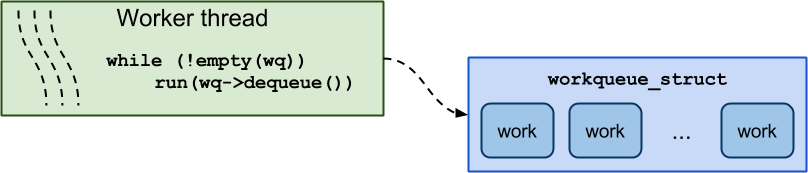
在这里的work则是work_struct变量,并且绑定一个执行函数——typedef void (*work_func_t)(struct work_struct *work);。在worker thread中会对非空的工作队列进行工作队列的出队操作,并运行work绑定的函数。
work_struct
work_struct的数据结构如下,暂时我们还无法关注其原理,只关注如何去开启一个work
#include <linux/include/workqueue.h>
typedef void (*work_func_t)(struct work_struct *work);
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
通过数据结构可以知道,每当我们定义一个work_struct变量的时候,需要绑定一个work_func_t类型的函数指针。
| 函数 | 功能 |
|---|---|
| INIT_WORK(_work, _func) | 初始化一个work |
| INIT_WORK_ONSTACK(_work, _func) | 在栈上初始化一个work |
| flush_work(struct work_struct *work); | 销毁一个work |
| schedule_work(struct work_struct *work) | 调度一个work开始运行 |
例程
下面写了 一个demo,模块初始化之后会每隔5秒调度work开始运行,最终demo_work_func会运行规定的次数,并打印传递的参数和进程信息。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/time.h>
#include <linux/jiffies.h>
#include <linux/workqueue.h>
#include <linux/slab.h> //kmalloc kfree
#include <linux/sched.h>
#include <linux/delay.h>
static char data[] = "test for demo work";
struct work_ctx{
struct work_struct real_work;
char *str;
int arg;
}work_ctx;
struct work_ctx *demo_work;
static void demo_work_func(struct work_struct *work){
struct work_ctx *temp_work = container_of(work,struct work_ctx,real_work);
printk(KERN_INFO "[work]=> PID: %d; NAME: %s\n", current->pid, current->comm);
printk(KERN_INFO "[work]=> sleep 1 seconds\n");
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(1 * HZ); //Wait 1 seconds
printk(KERN_INFO "[work]=> data is: %d %s\n", temp_work->arg,temp_work->str);
}
static int __init demo_thread_init(void){
int count = 10;
demo_work = kmalloc(sizeof(*demo_work),GFP_KERNEL);
INIT_WORK(&demo_work->real_work, demo_work_func);
demo_work->str = data;
while(count--){
msleep(5000);
demo_work->arg = count;
schedule_work(&demo_work->real_work);
}
return 0;
}
module_init(demo_thread_init);
static void __exit demo_thread_exit(void){
flush_work(&demo_work->real_work);
kfree(demo_work);
}
module_exit(demo_thread_exit);
MODULE_LICENSE("GPL");
运行结果
[ 8.500146] [work]=> PID: 37; NAME: kworker/0:1
[ 8.500216] [work]=> sleep 1 seconds
[ 9.499783] [work]=> data is: 9 test for demo work
[ 13.503165] [work]=> PID: 37; NAME: kworker/0:1
[ 13.503213] [work]=> sleep 1 seconds
[ 14.503122] [work]=> data is: 8 test for demo work
[ 18.506493] [work]=> PID: 37; NAME: kworker/0:1
[ 18.506534] [work]=> sleep 1 seconds
[ 19.506460] [work]=> data is: 7 test for demo work
[ 23.509833] [work]=> PID: 37; NAME: kworker/0:1
[ 23.509874] [work]=> sleep 1 seconds
[ 24.510060] [work]=> data is: 6 test for demo work
[ 28.513161] [work]=> PID: 37; NAME: kworker/0:1
[ 28.513206] [work]=> sleep 1 seconds
[ 29.513121] [work]=> data is: 5 test for demo work
[ 33.516502] [work]=> PID: 37; NAME: kworker/0:1
[ 33.516545] [work]=> sleep 1 seconds
[ 34.516452] [work]=> data is: 4 test for demo work
[ 38.519819] [work]=> PID: 37; NAME: kworker/0:1
[ 38.519860] [work]=> sleep 1 seconds
[ 39.519782] [work]=> data is: 3 test for demo work
[ 43.523151] [work]=> PID: 37; NAME: kworker/0:1
[ 43.523191] [work]=> sleep 1 seconds
[ 44.523117] [work]=> data is: 2 test for demo work
[ 48.526495] [work]=> PID: 37; NAME: kworker/0:1
[ 48.526542] [work]=> sleep 1 seconds
[ 49.526444] [work]=> data is: 1 test for demo work
[ 53.539699] [work]=> PID: 37; NAME: kworker/0:1
[ 53.539763] [work]=> sleep 1 seconds
[ 54.542925] [work]=> data is: 0 test for demo work
参考
https://www.oreilly.com/library/view/understanding-the-linux/0596005652/ch04s08.html
https://kukuruku.co/post/multitasking-in-the-linux-kernel-workqueues/
Linux 内核工作队列之work_struct 学习总结的更多相关文章
- LINUX内核分析第一周学习总结——计算机是如何工作的
LINUX内核分析第一周学习总结——计算机是如何工作的 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/course/ ...
- LINUX内核分析第二周学习总结——操作系统是如何工作的
LINUX内核分析第二周学习总结——操作系统是如何工作的 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/course ...
- LINUX内核分析第四周学习总结——扒开系统调用的“三层皮”
LINUX内核分析第四周学习总结--扒开系统调用的"三层皮" 标签(空格分隔): 20135321余佳源 余佳源 原创作品转载请注明出处 <Linux内核分析>MOOC ...
- linux内核分析第四周学习笔记
linux内核分析第四周学习笔记 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.co ...
- Linux内核分析第二周学习笔记
linux内核分析第二周学习笔记 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.co ...
- linux内核分析第一周学习笔记
linux内核分析第一周学习笔记 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.co ...
- Linux内核的ioctl函数学习
Linux内核的ioctl函数学习 来源:Linux公社 作者:Linux 我这里说的ioctl函数是在驱动程序里的,因为我不知道还有没有别的场合用到了ioctl, 所以就规定了我们讨论的范围.为什 ...
- Linux内核分析第一周学习博客 --- 通过反汇编方式学习计算机工作过程
Linux内核分析第一周学习博客 通过反汇编方式学习计算机工作过程 总结: 通过这次对一个简单C程序的反汇编学习,我了解到计算机在实际工作工程中要涉及大量的跳转指针操作.计算机通常是顺序执行一条一条的 ...
- Linux内核分析第二周学习博客——完成一个简单的时间片轮转多道程序内核代码
Linux内核分析第二周学习博客 本周,通过实现一个简单的操作系统内核,我大致了解了操作系统运行的过程. 实验主要步骤如下: 代码分析: void my_process(void) { int i = ...
随机推荐
- yzmsb_test.py
识别诺诺金服页面的验证码,并自动登录到后台. #导包 from selenium import webdriver from PIL import Image, ImageDraw from time ...
- BUUOJ [WUSTCTF2020]朴实无华
[WUSTCTF2020]朴实无华 复现了武科大的一道题/// 进入界面 一个hack me 好吧,直接看看有没有robot.txt 哦豁,还真有 好吧 fAke_f1agggg.php 看了里面,然 ...
- CentOS7.7下二进制部署MySQL多版本多实例实战
第一章 需求说明 部署MySQL5.7的三个多实例环境(端口分别为3307,3308,3309) 部署MySQL5.6和8.0版本数据库实例((端口分别为3316和3326) 第二章 环境准备 1.虚 ...
- 《HelloGitHub》第 49 期
兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的开源项目. 这是一个面向编程新手.热爱编程.对开源社区感兴趣 人群的月刊,月刊的内容包括:各种编 ...
- 关于“xxx”object is not callable的异常
参考博文:https://blog.csdn.net/yitiaodashu/article/details/79016671 所谓callable对象是指一个后边可以加()的对象,比如函数, 所以这 ...
- Spring Cloud微服务技术概览
Spring Cloud 是一系列框架的有序集合.它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载均衡.断路器.数据监控等,都 ...
- 如何打开 Visual Studio 的 Dump,适用于调试 appcrash,exception
https://keithbabinec.com/2018/06/12/how-to-capture-and-debug-net-application-crash-dumps-in-windows/ ...
- Spring5参考指南: BeanWrapper和PropertyEditor
文章目录 BeanWrapper PropertyEditor BeanWrapper 通常来说一个Bean包含一个默认的无参构造函数,和属性的get,set方法. org.springframewo ...
- 基于jenkins自动打包并部署Tomcat环境
传统网站部署的流程 在运维过程中,网站部署是运维的工作之一.传统的网站部署的流程大致分为:需求分析->原型设计->开发代码->提交代码->内网部署->内网测试->确 ...
- Linux系统管理第五次作业 LVM逻辑卷 磁盘配额
1.为主机增加80G SCSI 接口硬盘 2.划分三个各20G的主分区 [root@localhost ~]# fdisk /dev/sdf 欢迎使用 fdisk (util-linux 2.23.2 ...