[PyTorch入门之60分钟入门闪击战]之神经网络
神经网络
来源于这里。
神经网络可以使用torch.nn包构建。
现在你对autograd已经有了初步的了解,nn依赖于autograd定义模型并区分它们。一个nn.Module包含了层(layers),和一个用来返回output的方法forward(input)。
以下面这个区分数字图像的网络为例:
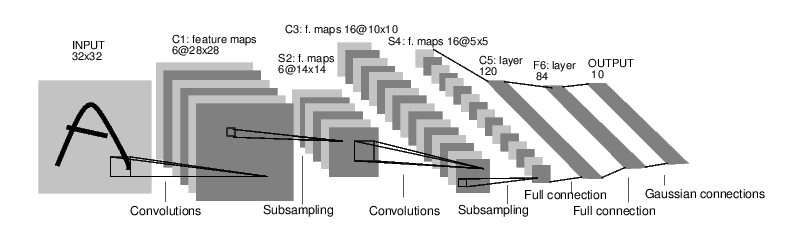
上图是一个简单的前馈网络。它接受输入,一个层接一层地通过几层网络,最后给出输出。
典型的神经网络训练程序如下:
- 定义具有一些可学习参数(或权重)的神经网络
- 迭代输入的数据集
- 通过网络处理输入
- 计算损失(离正确有多远)
- 将梯度回传给网络参数
- 更新网络权重,最典型的更新规则:
weight = weight - learning_rate * gradient
定义网络
首先,我们需要定义网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 1个图形输入通道,6个输出通道,3x3 卷积核
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# 操作: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 图像感受野
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
# 最大池化窗口(2, 2)
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
# 如果尺寸是正方形,则只需设置一个数字
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(-1,self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self,x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
输出:
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=576, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
你只需要定义forward函数即可,backward函数(计算梯度)在你使用autograd时自动定义。你可以在forward函数中使用任意的Tensor操作。
模型的可学习参数通过net.parameters()返回:
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1层的权重
输出:
10
torch.Size([6, 1, 3, 3])
现在试一下32x32的随机输入。注意:此网络期望的输入尺寸为32x32。要在MNIST数据集上使用此网络,需要现将图形尺寸设为32x32。
input = torch.randn(1,1,32,32)
out = net(input)
print(out)
输出:
tensor([[ 0.0246, 0.0667, -0.0183, -0.0321, -0.0198, -0.0242, -0.0004, 0.0360,
0.0852, -0.0699]], grad_fn=<AddmmBackward>)
零化所有参数的梯度缓存并反向传播随机梯度:
net.zero_grad()
out.backward(torch.randn(1,10))
注意
torch.nn只支持迷你批次。整个torch.nn包只支持小批量的样本输入,不支持单个样本。
例如,nn.Conv2d采用4维张量输入:nSamples x nChannels x Height x Width。
如果你只有一个样本,那么就需要使用input.unsqueeze(0)来添加一个假的批次维度。
在进行接下来的工作之前,我们梳理下目前接触到所有的类。
梳理
torch.Tensor- 支持自动梯度操作(例如backward())的多维数组。也存储张量的梯度。nn.Module- 神经网络模块。便捷的参数封装方式,为模型移动到GPU、导出、导入等提供帮助。nn.Parameter- 一种张量,当被指定为模型属性时,自动注册为参数。autograd.Function- 一种自动梯度操作正向和反向定义的实现。每个张量操作至少创建一个Function节点,包含创建张量的函数和编码它的历史记录的函数。
此时,我们做了:
- 定义了一个神经网络
- 处理了输入值,并调用了反向传播
还剩下:
- 计算损失
- 更新网络的权重
损失函数(Loss Function)
损失函数将(输出(output),目标(target))作为输入,计算出预估输出与目标之间的距离。
nn包中包含了几种不同的损失函数。nn.MSELoss函数,一种简单的损失函数,计算输入与目标之间的均方差。
例如:
output = net(input)
target = torch.randn(10)
target = target.view(1,-1)
criterion = nn.MSELoss()
loss = criterion(output,target)
print(loss)
输出:
tensor(0.8390, grad_fn=<MseLossBackward>)
此时,你如果按照loss反向使用它的.grad_fn属性,你会看到如下的计算图:
input -> conv2d -> relu -> maxpool2d -> conv2d ->relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
所以,当我们调用loss.backward(),整个图中与损失相关的张量开始被微分,图中所有有requires_grad=True的张量都将随着梯度累积它们的.grad张。
为了验证这一点,我们回退几步:
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
输出:
<MseLossBackward object at 0x11f40fdd8>
<AddmmBackward object at 0x11f40fe80>
<AccumulateGrad object at 0x11f40fe80>
反向传递(Backprop)
为了反向传播误差,我们必须要做的就是调用loss.backward()。不过你需要先清除现有的梯度,否则梯度将累积到已有的梯度上。
现在我们调用loss.backward(),查看先conv1层偏置反向传播前后的梯度。
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
输出:
conv1.bias.grad before backward
None
conv1.bias.grad after backward
tensor([ 0.0055, -0.0027, -0.0131, 0.0017, -0.0009, 0.0013])
现在,我们知道了如何使用损失函数。
进阶阅读
神经网络包包含各种模块和损失函数,构成了深度神经网络的构建模块。这里有完整的列表和文档。
现在未学习的就只剩下:
- 更新网络的权重
更新权重(Update the weights)
在实践中使用的最简单的更新规则就是随机梯度下降(Stochastic Gradient Descent, SGD):
weight = weight - learning_rate * gradient
我们可以用简单的Python代码实现上述规则:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
然而,在使用神经网络是,你可能会用到各种各样不同的更新规则,例如 SGD、Nesterov-SGD、Adam、RMSProp等等。为了满足上述要求,PyTorch构建了torch.optim包,其中实现了上述方法。使用时非常简单:
import torch.optim as optim
# 选择你想用的更新规则
optimizer = optim.SGD(net.parameters(),lr=0.01)
# 以下代码写在训练环节中
optimizer.zero_grad()
output = net(input)
loss = criterion(output,target)
loss.backward()
optimizer.step()
注意:
训练时需要手动调用optimizer.zero_grad()来将梯度缓冲区置0。因为梯度是按照Backprop部分说明的方式累积的。
[PyTorch入门之60分钟入门闪击战]之神经网络的更多相关文章
- [PyTorch入门之60分钟入门闪击战]之入门
深度学习60分钟入门 来源于这里. 本文目标: 在高层次上理解PyTorch的Tensor库和神经网络 训练一个小型的图形分类神经网络 本文示例运行在ipython中. 什么是PyTorch PyTo ...
- [PyTorch入门之60分钟入门闪击战]之训练分类器
训练分类器 目前为止,你已经知道如何定义神经网络.计算损失和更新网络的权重.现在你可能在想,那数据呢? What about data? 通常,当你需要处理图像.文本.音频或者视频数据时,你可以使用标 ...
- [PyTorch入门之60分钟入门闪击战]之自动推倒
AUTOGRAD: AUTOMATIC DIFFERENTIATION(自动分化) 来源于这里. autograd包是PyTorch中所有神经网络的核心.首先我们先简单地了解下它,然后我们将训练我们的 ...
- PyTorch 60 分钟入门教程
PyTorch 60 分钟入门教程:PyTorch 深度学习官方入门中文教程 http://pytorchchina.com/2018/06/25/what-is-pytorch/ PyTorch 6 ...
- 【PyTorch深度学习60分钟快速入门 】Part0:系列介绍
说明:本系列教程翻译自PyTorch官方教程<Deep Learning with PyTorch: A 60 Minute Blitz>,基于PyTorch 0.3.0.post4 ...
- 【PyTorch深度学习60分钟快速入门 】Part4:训练一个分类器
太棒啦!到目前为止,你已经了解了如何定义神经网络.计算损失,以及更新网络权重.不过,现在你可能会思考以下几个方面: 0x01 数据集 通常,当你需要处理图像.文本.音频或视频数据时,你可以使用标准 ...
- 【PyTorch深度学习60分钟快速入门 】Part5:数据并行化
在本节中,我们将学习如何利用DataParallel使用多个GPU. 在PyTorch中使用多个GPU非常容易,你可以使用下面代码将模型放在GPU上: model.gpu() 然后,你可以将所有张 ...
- 【PyTorch深度学习60分钟快速入门 】Part2:Autograd自动化微分
在PyTorch中,集中于所有神经网络的是autograd包.首先,我们简要地看一下此工具包,然后我们将训练第一个神经网络. autograd包为张量的所有操作提供了自动微分.它是一个运行式定义的 ...
- 【PyTorch深度学习60分钟快速入门 】Part1:PyTorch是什么?
0x00 PyTorch是什么? PyTorch是一个基于Python的科学计算工具包,它主要面向两种场景: 用于替代NumPy,可以使用GPU的计算力 一种深度学习研究平台,可以提供最大的灵活性 ...
随机推荐
- 人工智能必备之Python3.8.1-安装
1_下载Python 2_下载Python 3_下载Python 4_下载Python-选这里下载:Windows x86-64 executable installer 5_安装Python 6.自 ...
- 六、Shell脚本高级编程实战第六部
一.写一个start_nginx脚本,当启动.停止.重启时利用系统函数模拟实现系统脚本启动的特殊颜色效果 (用if实现) #!/bin/sh. /etc/init.d/functions if [ $ ...
- 绿洲作业第二周 - 周二music work 音乐
Please kindly find the music work from Ms. Sophie. 1.请跟随附件中老师录制的视频进行学习和练习.(附件有带拼音的乐谱供KS1和外国学生使用) htt ...
- Centos7.5 firewalld防火墙配置
CentOS 7.0默认使用的是firewall作为防火墙 1.查看firewall服务状态 systemctl status firewalld 2.查看firewall的状态 firewall-c ...
- Git log 中文乱码
以下三条命令搞定(系统是centos 7.4) git config --global i18n.commitencoding utf-8 git config --global i18n.logo ...
- BaseAdapter教程(1) 最简单地使用BaseAdapter
Adapter就是适配器,而设计模式里也有Adapter Pattern. 而BaseAdapter就是设计模式里的思维,把一些不相关的东西放进去,经过适配器,最终都会出产同一样的东西. 就像Base ...
- [NOIP 2002普及组]产生数(floyd+高精度)
https://www.luogu.org/problem/P1037 题目描述 给出一个整数 n(n<1030) 和 k 个变换规则(k<=15). 规则: 一位数可变换成另一个一位数: ...
- 二十七、rsync同步工具
1.什么是rsync? Rsync是一款开源的.快速的,多功能的,可实现全量及增量的本地或者远程数据同步备份的优秀工具.windows和linux都可以. 官网:http:www.samba.org/ ...
- D. Fish eating fruit
题:https://nanti.jisuanke.com/t/41403 题意:求任意俩点之间距离之和模3后的三个结果的总数(原距离之和) 第一种做法: 树形dp #include<bits/s ...
- 吴裕雄--天生自然python学习笔记:打开文件并显示文件内容
Win32com 组件打开文件通过 Documents 的 Open 方法,语法为 : 例如,打开上一节创建的 testl . docx 文件 , 文件变量名为 doc: 获得文件内容的方法有两种,第 ...