缓存与数据库一致性之二:高并发下的key重建(先淘汰cache再写db)的问题
一、为什么数据会不一致
回顾一下上一篇文章《缓存与数据库一致性之一:缓存更新设计》中对缓存、数据库进行读写操作的流程。
写流程:
(1)先淘汰cache
(2)再写db
读流程:
(1)先读cache,如果数据命中hit则返回
(2)如果数据未命中miss则读db
(3)将db中读取出来的数据入缓存
什么情况下可能出现缓存和数据库中数据不一致呢?

在分布式环境下,数据的读写都是并发的,上游有多个应用,通过一个服务的多个部署(为了保证可用性,一定是部署多份的),对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序,也就是说后发出的读请求很可能先完成(读出脏数据):
(a)发生了写请求A,A的第一步淘汰了cache(如上图中的1)
(b)A的第二步写数据库,发出修改请求(如上图中的2)
(c)发生了读请求B,B的第一步读取cache,发现cache中是空的(如上图中的步骤3)
(d)B的第二步读取数据库,发出读取请求,此时A的第二步写数据还没完成,读出了一个脏数据放入cache(如上图中的步骤4)
即在数据库层面,后发出的请求4比先发出的请求2先完成了,读出了脏数据,脏数据又入了缓存,缓存与数据库中的数据不一致出现了
二、不一致优化思路
能否做到先发出的请求一定先执行完成呢?常见的思路是“串行化”,今天将和大家一起探讨“串行化”这个点。
先一起细看一下,在一个服务中,并发的多个读写SQL一般是怎么执行的
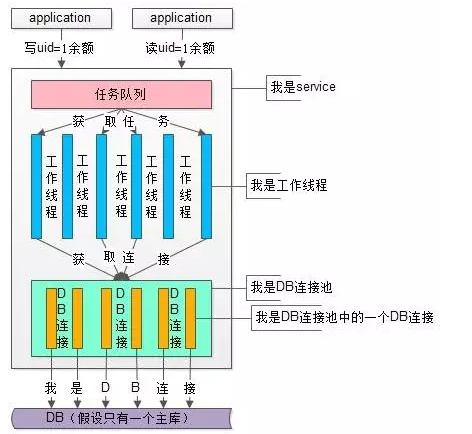
上图是一个service服务的上下游及服务内部详细展开,细节如下:
(1)service的上游是多个业务应用,上游发起请求对同一个数据并发的进行读写操作,上例中并发进行了一个uid=1的余额修改(写)操作与uid=1的余额查询(读)操作
(2)service的下游是数据库DB,假设只读写一个DB
(3)中间是服务层service,它又分为了这么几个部分
(3.1)最上层是任务队列
(3.2)中间是工作线程,每个工作线程完成实际的工作任务,典型的工作任务是通过数据库连接池读写数据库
(3.3)最下层是数据库连接池,所有的SQL语句都是通过数据库连接池发往数据库去执行的
工作线程的典型工作流是这样的:
void work_thread_routine(){
Task t = TaskQueue.pop(); // 获取任务
// 任务逻辑处理,生成sql语句
DBConnection c = CPool.GetDBConnection(); // 从DB连接池获取一个DB连接
c.execSQL(sql); // 通过DB连接执行sql语句
CPool.PutDBConnection(c); // 将DB连接放回DB连接池
}
提问:任务队列其实已经做了任务串行化的工作,能否保证任务不并发执行?
答:不行,因为
(1)1个服务有多个工作线程,串行弹出的任务会被并行执行
(2)1个服务有多个数据库连接,每个工作线程获取不同的数据库连接会在DB层面并发执行
提问:假设服务只部署一份,能否保证任务不并发执行?
答:不行,原因同上
提问:假设1个服务只有1条数据库连接,能否保证任务不并发执行?
答:不行,因为
(1)1个服务只有1条数据库连接,只能保证在一个服务器上的请求在数据库层面是串行执行的
(2)因为服务是分布式部署的,多个服务上的请求在数据库层面仍可能是并发执行的
提问:假设服务只部署一份,且1个服务只有1条连接,能否保证任务不并发执行?
答:可以,全局来看请求是串行执行的,吞吐量很低,并且服务无法保证可用
完了,看似无望了,
1)任务队列不能保证串行化
2)单服务多数据库连接不能保证串行化
3)多服务单数据库连接不能保证串行化
4)单服务单数据库连接可能保证串行化,但吞吐量级低,且不能保证服务的可用性,几乎不可行,那是否还有解?
退一步想,其实不需要让全局的请求串行化,而只需要“让同一个数据的访问能串行化”就行。在一个服务内,如何做到“让同一个数据的访问串行化”,只需要“让同一个数据的访问通过同一条DB连接执行”就行。
如何做到“让同一个数据的访问通过同一条DB连接执行”,只需要“在DB连接池层面稍微修改,按数据取连接即可”
获取DB连接的CPool.GetDBConnection()【返回任何一个可用DB连接】改为CPool.GetDBConnection(longid)【返回id取模相关联的DB连接】
这个修改的好处是:
(1)简单,只需要修改DB连接池实现,以及DB连接获取处
(2)连接池的修改不需要关注业务,传入的id是什么含义连接池不关注,直接按照id取模返回DB连接即可
(3)可以适用多种业务场景,取用户数据业务传入user-id取连接,取订单数据业务传入order-id取连接即可
这样的话,就能够保证同一个数据例如uid在数据库层面的执行一定是串行的
稍等稍等,服务可是部署了很多份的,上述方案只能保证同一个数据在一个服务上的访问,在DB层面的执行是串行化的,实际上服务是分布式部署的,在全局范围内的访问仍是并行的,怎么解决呢?能不能做到同一个数据的访问一定落到同一个服务呢?
三、能否做到同一个数据的访问落在同一个服务上?
上面分析了服务层service的上下游及内部结构,再一起看一下应用层上下游及内部结构

上图是一个业务应用的上下游及服务内部详细展开,细节如下:
(1)业务应用的上游不确定是啥,可能是直接是http请求,可能也是一个服务的上游调用
(2)业务应用的下游是多个服务service
(3)中间是业务应用,它又分为了这么几个部分
(3.1)最上层是任务队列【或许web-server例如tomcat帮你干了这个事情了】
(3.2)中间是工作线程【或许web-server的工作线程或者cgi工作线程帮你干了线程分派这个事情了】,每个工作线程完成实际的业务任务,典型的工作任务是通过服务连接池进行RPC调用
(3.3)最下层是服务连接池,所有的RPC调用都是通过服务连接池往下游服务去发包执行的
工作线程的典型工作流是这样的:
void work_thread_routine(){
Task t = TaskQueue.pop(); // 获取任务
// 任务逻辑处理,组成一个网络包packet,调用下游RPC接口
ServiceConnection c = CPool.GetServiceConnection(); // 从Service连接池获取一个Service连接
c.Send(packet); // 通过Service连接发送报文执行RPC请求
CPool.PutServiceConnection(c); // 将Service连接放回Service连接池
}
似曾相识吧?没错,只要对服务连接池进行少量改动:
获取Service连接的CPool.GetServiceConnection()【返回任何一个可用Service连接】改为CPool.GetServiceConnection(longid)【返回id取模相关联的Service连接】
这样的话,就能够保证同一个数据例如uid的请求落到同一个服务Service上。
四、总结
由于数据库层面的读写并发,引发的数据库与缓存数据不一致的问题(本质是后发生的读请求先返回了),可能通过两个小的改动解决:
(1)修改服务Service连接池,id取模选取服务连接,能够保证同一个数据的读写都落在同一个后端服务上
(2)修改数据库DB连接池,id取模选取DB连接,能够保证同一个数据的读写在数据库层面是串行的
(3关于key重建还有2种方案见《缓存与数据库一致性之三:缓存穿透、缓存雪崩》
五、遗留问题
提问:取模访问服务是否会影响服务的可用性?
答:不会,当有下游服务挂掉的时候,服务连接池能够检测到连接的可用性,取模时要把不可用的服务连接排除掉。
提问:取模访问服务与 取模访问DB,是否会影响各连接上请求的负载均衡?
答:不会,只要数据访问id是均衡的,从全局来看,由id取模获取各连接的概率也是均等的,即负载是均衡的。
提问:要是数据库的架构做了主从同步,读写分离:写请求写主库,读请求读从库也有可能导致缓存中进入脏数据呀,这种情况怎么解决呢(读写请求根本不落在同一个DB上,并且读写DB有同步时延)?
答:下一篇文章和大家分享。
转自:http://mp.weixin.qq.com/s/CY4jntpM7VNkBrz1FKRsOw
缓存与数据库一致性之二:高并发下的key重建(先淘汰cache再写db)的问题的更多相关文章
- Redis缓存和数据库一致性问题
工作中,经常会遇到缓存和数据库数据一致性问题.从理论上设置过期时间,是保证最终一致性的解决方案.这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可 ...
- redis缓存与数据库一致性问题
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去. ...
- 缓存与数据库一致性之三:缓存穿透、缓存雪崩、key重建方案
一.缓存穿透预防及优化 缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,但是出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如图 11-3 所示整个过程分为如下 3 步: 缓存层 ...
- Redis怎么保持缓存与数据库一致性?
将不一致分为三种情况: 1. 数据库有数据,缓存没有数据: 2. 数据库有数据,缓存也有数据,数据不相等: 3. 数据库没有数据,缓存有数据. 在讨论这三种情况之前,先说明一下我使用缓存的策略,也是大 ...
- Redis缓存与数据库一致性解决方案
背景 缓存是数据库的副本,应用在查询数据时,先从缓存中查询,如果命中直接返回,如果未命中,去数据库查询最新数据并返回,同时写入缓存. 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载.是应用架 ...
- 高并发下redis
1.================================================================================================== ...
- 【mysql】mysql增加version字段实现乐观锁,实现高并发下的订单库存的并发控制,通过开启多线程同时处理模拟多个请求同时到达的情况 + 同一事务中使用多个乐观锁的情况处理
mysql增加version字段实现乐观锁,实现高并发下的订单库存的并发控制,通过开启多线程同时处理模拟多个请求同时到达的情况 ==================================== ...
- Redis使用总结(二、缓存和数据库双写一致性问题)
首先,缓存由于其高并发和高性能的特性,已经在项目中被广泛使用.在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作. 但是在更新缓存方面,对于更新完数据库,是更新缓存呢,还是删除缓存.又或者 ...
- 数据库历险记(三) | 缓存框架的连环炮 数据库历险记(二) | Redis 和 Mecached 到底哪个好? 数据库历险记(一) | MySQL这么好,为什么还有人用Oracle? 面对海量请求,缓存设计还应该考虑哪些问题?
数据库历险记(三) | 缓存框架的连环炮 文章首发于微信公众号「陈树义」,专注于 Java 技术分享的社区.点击链接扫描二维码,与500位小伙伴一起共同进步.微信公众号二维码 http://p3n ...
随机推荐
- 文件查找工具Everything小工具的使用
Everything 小工具的使用: 首先它是一款基于名称实时定位文件和目录的搜索工具,有以下几个优点: 快速文件索引 快速文件搜索 较低资源占用 轻松分享文件索引 实时跟踪文件更新 通过使用ever ...
- cmake默认变量
1 CMAKE_GENERATOR 用来生成工程构建文件的工具的名字,比如visual studio 12,2013,比如xcode,不同的平台使用不同的生成工具. 2 MATCHES if (var ...
- Grunt学习笔记【7】---- grunt-contrib-less插件详解
本文主要讲如何使用Grunt实现less文件压缩. 一 说明 less是非常常用的样式框架之一,Grunt也提供了可以编译和打包less样式文件的插件:grunt-contrib-less. 实现原理 ...
- NinjaFramework中文教程(简单版)-手把手教程-从零开始
第一步: 官网http://www.ninjaframework.org/documentation/getting_started/create_your_first_application.htm ...
- Java中的迭代迭代器Iterator与枚举器Enumeration
Iterator 和 Enumeration区别 Iterator 和 Eumberation都是Collection集合的遍历接口,我们先看下他们的源码接口 package java.util; p ...
- 使用qt+ros调用摄像头遇到的问题
当使用摄像头遇到如下问题:[usb_cam-1] process has died [pid 12288, exit code 127, cmd /opt/ros/indigo/lib/usb_cam ...
- testng ITestListener使用
ITestListener适用场景 当使用testng执行测试时,我们常会想在某个阶段做一些特别的处理,比如:测试成功结束后,测试失败后,跳过某个脚本后,全部脚本执行完毕后.要想达成这个目标,我们需要 ...
- mini2440 uboot烧写uImage
mini2440下烧写u-boot后,就可以用u-boot烧写linux内核了. 安装mkimage工具: apt-get install u-boot-tools 解压缩官方mini2440 lin ...
- 51Nod 1627 瞬间移动 —— 组合数学
题目链接:http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1627 1627 瞬间移动 基准时间限制:1 秒 空间限制:1 ...
- DubboAdmin平台
DubboAdmin部署 将dubbo-admin.war放入到TomcatWebapps目录下,修改dubbo.properties中的Zookeeper连接地址即可. dubbo-admin放到 ...