大数据学习——actor编程
1 概念
Scala中的Actor能够实现并行编程的强大功能,它是基于事件模型的并发机制,Scala是运用消息(message)的发送、接收来实现多线程的。使用Scala能够更容易地实现多线程应用的开发。
2 传统java并发编程与scala actor编程的区别
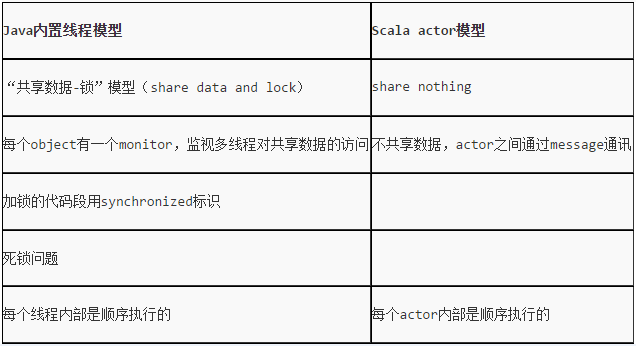
对于Java,我们都知道它的多线程实现需要对共享资源(变量、对象等)使用synchronized 关键字进行代码块同步、对象锁互斥等等。而且,常常一大块的try…catch语句块中加上wait方法、notify方法、notifyAll方法是让人很头疼的。原因就在于Java中多数使用的是可变状态的对象资源,对这些资源进行共享来实现多线程编程的话,控制好资源竞争与防止对象状态被意外修改是非常重要的,而对象状态的不变性也是较难以保证的。 而在Scala中,我们可以通过复制不可变状态的资源(即对象,Scala中一切都是对象,连函数、方法也是)的一个副本,再基于Actor的消息发送、接收机制进行并行编程
3 actor方法执行顺序
1.首先调用start()方法启动Actor
2.调用start()方法后其act()方法会被执行
3.向Actor发送消息
发送消息的方式
|
! |
发送异步消息,没有返回值。 |
|
!? |
发送同步消息,等待返回值。 |
|
!! |
发送异步消息,返回值是 Future[Any]。 |
例子
添加依赖
<!--scala actor-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>2.10.5</version>
</dependency>
1
package main.scala.com import scala.actors.Actor /**
* Created by Administrator on 2019/6/4.
*/
object MyActor1 extends Actor { //重写act方法 def act(): Unit = {
for (i <- 1 to 10) {
println("actor-1" + i)
Thread.sleep(2000)
}
}
} object MyActor2 extends Actor {
//重写act方法
def act() {
for (i <- 1 to 10) {
println("actor-2 " + i)
Thread.sleep(2000)
}
}
}
object ActorTest extends App{
//启动Actor
MyActor1.start()
MyActor2.start()
}
运行结果
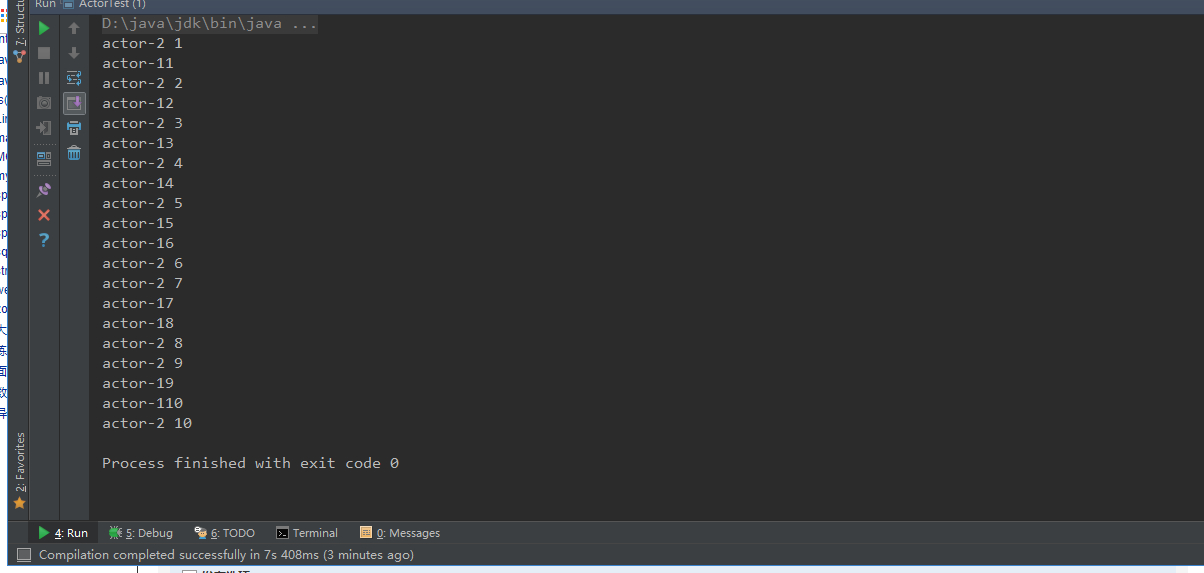
说明:上面分别调用了两个单例对象的start()方法,他们的act()方法会被执行,相同与在java中开启了两个线程,线程的run()方法会被执行
注意:这两个Actor是并行执行的,act()方法中的for循环执行完成后actor程序就退出了
可能遇见的问题
1 Exception in thread "main" java.lang.NoSuchMethodError: scala.actors.AbstractActor.$init$(Lscala/actors/AbstractActor;)V
解决办法
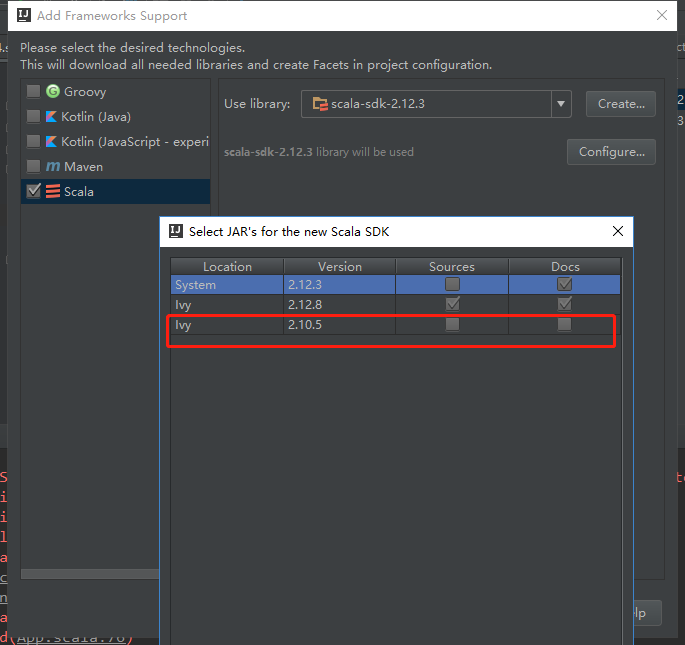
使用scala2.12.x的版本运行Actor,会报这种错误。
报错原因:scala版本不匹配,
解决方法:创建新工程,选择scala2.10.x的版本
2

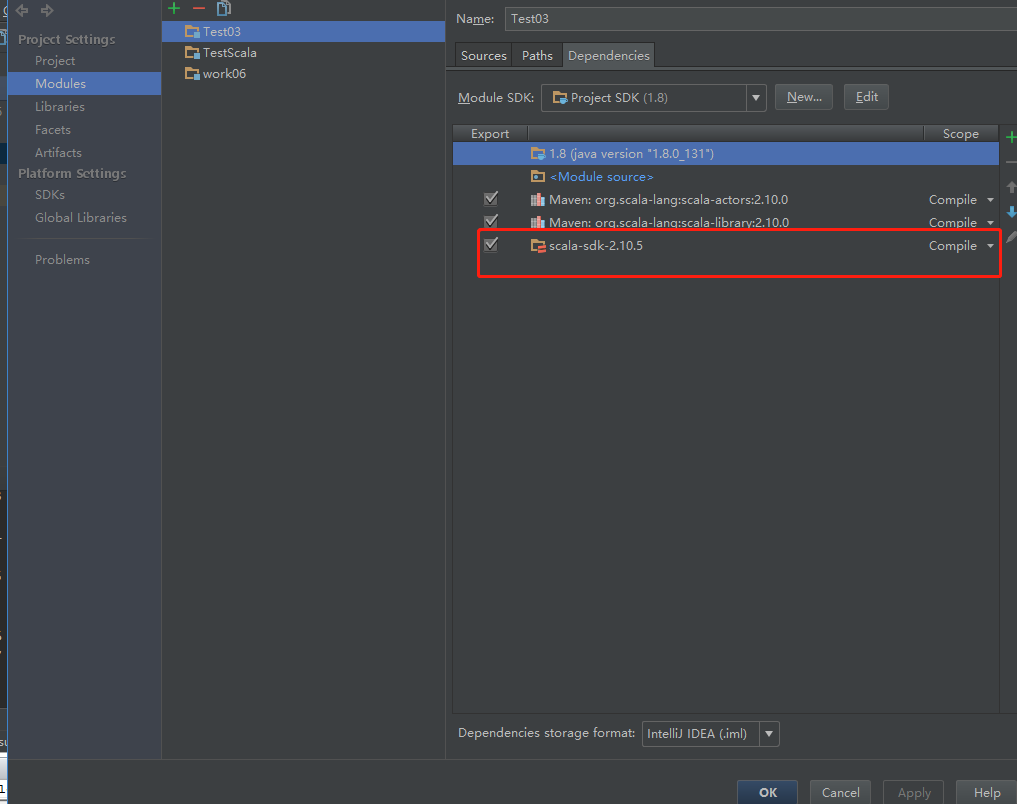
解决方案:项目->open module setting->Modules->Dependencies 加上scala sdk的library
2
package main.scala.com import scala.actors.Actor /**
* Created by Administrator on 2019/6/4.
*/
class MyActor extends Actor { override def act(): Unit = {
while (true) {
receive {
case "start" => {
println("starting ...")
Thread.sleep(5000)
println("started")
}
case "stop" => {
println("stopping ...")
Thread.sleep(5000)
println("stopped ...")
}
}
}
}
} object MyActor {
def main(args: Array[String]) {
val actor = new MyActor
actor.start()
actor ! "start"
actor ! "stop"
println("消息发送完成!")
}
}
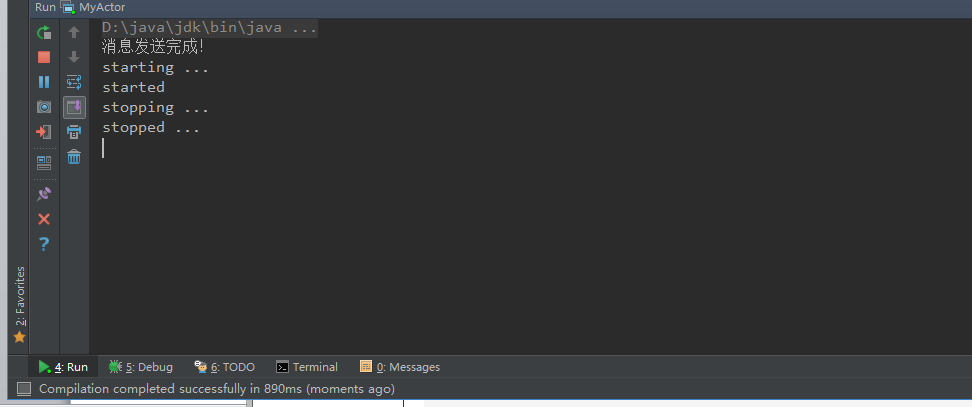
说明:在act()方法中加入了while (true) 循环,就可以不停的接收消息
注意:发送start消息和stop的消息是异步的,但是Actor接收到消息执行的过程是同步的按顺序执行
3
(react方式会复用线程,比receive更高效)
package main.scala.com import scala.actors.Actor /**
* Created by Administrator on 2019/6/4.
*/
class YourActor extends Actor { override def act(): Unit = {
loop {
react {
case "start" => {
println("starting ...")
Thread.sleep(5000)
println("started")
}
case "stop" => {
println("stopping ...")
Thread.sleep(8000)
println("stopped ...")
}
}
}
}
} object YourActor {
def main(args: Array[String]) {
val actor = new YourActor
actor.start()
actor ! "start"
actor ! "stop"
println("消息发送完成!")
}
}
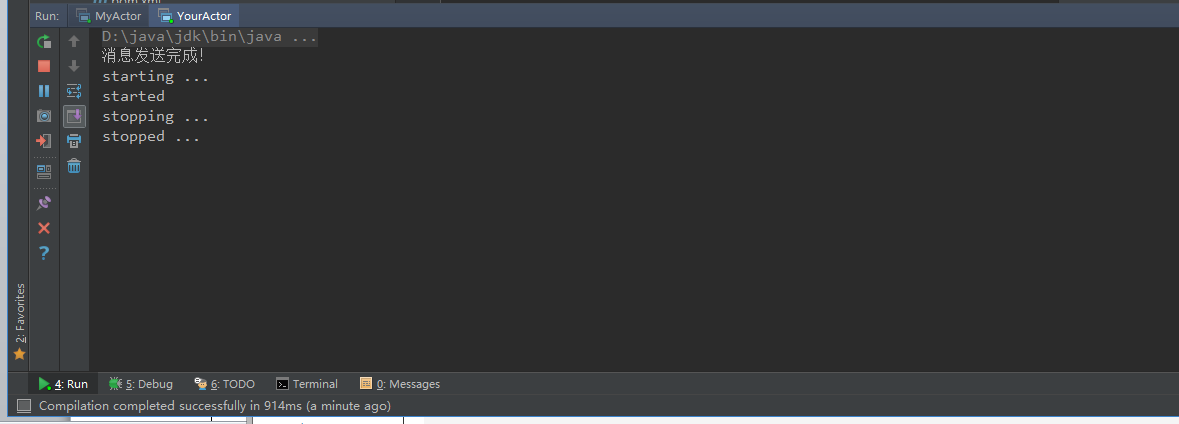
说明: react 如果要反复执行消息处理,react外层要用loop,不能用while
4
package main.scala.com import scala.actors.Actor /**
* Created by Administrator on 2019/6/4.
*/
class AppleActor extends Actor { def act(): Unit = {
while (true) {
receive {
case "start" => println("starting ...")
case SyncMsg(id, msg) => {
println(id + ",sync " + msg)
Thread.sleep(5000)
sender ! ReplyMsg(3, "finished")
}
case AsyncMsg(id, msg) => {
println(id + ",async " + msg)
Thread.sleep(5000)
}
}
}
}
} object AppleActor {
def main(args: Array[String]) {
val a = new AppleActor
a.start()
//异步消息
a ! AsyncMsg(1, "hello actor")
println("异步消息发送完成")
//同步消息
//val content = a.!?(1000, SyncMsg(2, "hello actor"))
//println(content)
val reply = a !! SyncMsg(2, "hello actor")
println(reply.isSet)
//println("123")
val c = reply.apply()
println(reply.isSet)
println(c)
}
} case class SyncMsg(id: Int, msg: String) case class AsyncMsg(id: Int, msg: String) case class ReplyMsg(id: Int, msg: String)

5 用actor并发编程写一个单机版的WorldCount,将多个文件作为输入,计算完成后将多个任务汇总,得到最终的结果
package main.scala.com
import java.io.File
import scala.actors.{Actor, Future}
import scala.collection.mutable
import scala.io.Source
/**
* Created by Administrator on 2019/6/4.
*/
class Task extends Actor {
override def act(): Unit = {
loop {
react {
case SubmitTask(fileName) => {
val contents = Source.fromFile(new File(fileName)).mkString
val arr = contents.split("\r\n")
val result = arr.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.length)
//val result = arr.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.foldLeft(0)(_ + _._2))
sender ! ResultTask(result)
}
case StopTask => {
exit()
}
}
}
}
}
object WorkCount {
def main(args: Array[String]) {
val files = Array("c://words.txt", "c://words.log")
val replaySet = new mutable.HashSet[Future[Any]]
val resultList = new mutable.ListBuffer[ResultTask]
for (f <- files) {
val t = new Task
val replay = t.start() !! SubmitTask(f)
replaySet += replay
}
while (replaySet.size > 0) {
val toCumpute = replaySet.filter(_.isSet)
for (r <- toCumpute) {
val result = r.apply()
resultList += result.asInstanceOf[ResultTask]
replaySet.remove(r)
}
Thread.sleep(100)
}
val finalResult = resultList.map(_.result).flatten.groupBy(_._1).mapValues(x => x.foldLeft(0)(_ + _._2))
println(finalResult)
}
}
case class SubmitTask(fileName: String)
case object StopTask
case class ResultTask(result: Map[String, Int])
大数据学习——actor编程的更多相关文章
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
- 大数据学习——shell编程
03/ shell编程综合练习 自动化软件部署脚本 3.1 需求 1.需求描述 公司内有一个N个节点的集群,需要统一安装一些软件(jdk) 需要开发一个脚本,实现对集群中的N台节点批量自动下载.安装j ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习之BigData常用算法和数据结构
大数据学习之BigData常用算法和数据结构 1.Bloom Filter 由一个很长的二进制向量和一系列hash函数组成 优点:可以减少IO操作,省空间 缺点:不支持删除,有 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- ABAP接口用法
1.定义接口INTERFACE intf [PUBLIC]. [components] ENDINTERFACE. 2.注意点: 2.1.接口中所定义的所有东西默认都是公共的,所以不用也不能写PU ...
- /usr/local/sbin/fping -s www.baidu.com www.google.com
/usr/local/sbin/fping -s www.baidu.com www.google.com
- HDU 4352 XHXJ's LIS (数位DP,状压)
题意: 前面3/4的英文都是废话.将一个正整数看成字符串,给定一个k,问区间[L,R]中严格的LIS=k的数有多少个? 思路: 实在没有想到字符0~9最多才10种,况且也符合O(nlogn)求LIS的 ...
- 洛谷 P2002 消息扩散
题目背景 本场比赛第一题,给个简单的吧,这 100 分先拿着. 题目描述 有n个城市,中间有单向道路连接,消息会沿着道路扩散,现在给出n个城市及其之间的道路,问至少需要在几个城市发布消息才能让这所有n ...
- 三、npm start报错:./node_modules/history/esm/history.js解决办法
package.json中的roadhog换为:'^2.5.0-beta.4',删除node_modules文件夹,在执行npm install,npm start.
- 使用HelpProvide组件调用帮助文件
实现效果: 知识运用: HelpProvider组件的HelpNameSpace属性 //于对象关联的帮助文件名 public virtual string HelpNameSpace {get; s ...
- CPP-基础:虚函数表
虚函数表 对C++ 了解的人都应该知道虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的.简称为V-Table.在这个表中,主是要一个类的虚函数的地址表 ...
- echarts实现仪表盘(自己动起来,没有后端,顺便重温math.random
let a = parseInt(Math.random() * (2 + 1), 10); let arr = []; arr.push(res[a]); let option = { toolti ...
- Java字符串池(String Pool)深度解析(转)
出自 http://www.cnblogs.com/fangfuhai/p/5500065.html 在工作中,String类是我们使用频率非常高的一种对象类型.JVM为了提升性能和减少内存开销,避 ...
- 【数学 技巧】divisor
没考虑重复lcm处理被卡TLE没A真是可惜 题目大意 $n$为$k-可表达的$当且仅当数$n$能被表示成$n$的$k$个因子之和,其中$k$个因子允许相等. 求$[A,B]$之间$k-可表达$的数的个 ...