spring事务管理器设计思想(二)
对于第二个问题,涉及到事务的传播级别,定义如下:
PROPAGATION_REQUIRED-- 如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS-- 如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY-- 如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
在开启事务之前,正常情况下需要做两个事情
一:获取当前事务上下文信息
二:获取将要开启事务的传播属性
根据以上两个信息,来判断程序的处理方式,具体方式如下:
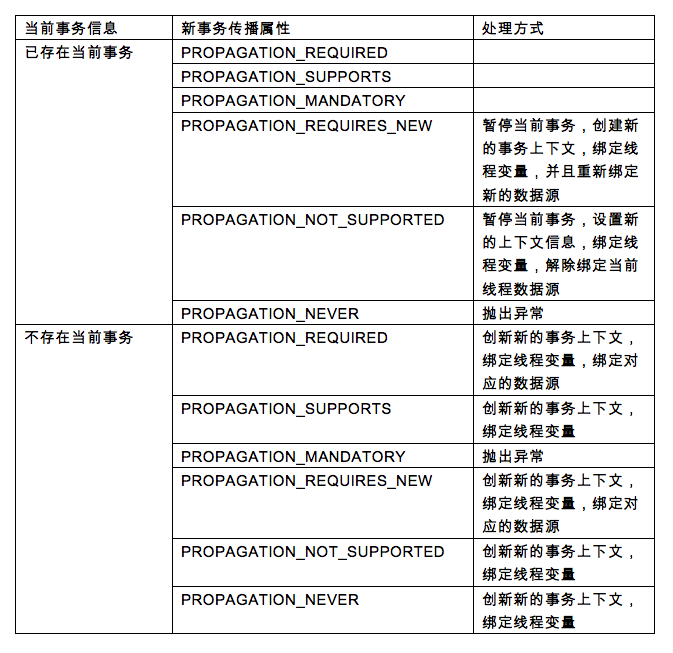
而处理流程则是如下:

其中上图标中英文简称对应的事务传播属性如下:
RE: PROPAGATION_REQUIRED-- 如果当前没有事务,就新建一个事务。这是最常见的选择。
SPT PROPAGATION_SUPPORTS-- 如果当前没有事务,就以非事务方式执行。
MA: PROPAGATION_MANDATORY-- 如果当前没有事务,就抛出异常。
RE_NEW: PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
NOT_SPT: PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
NEVER: PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
通过上面发现,只有新创建资源的时候,才会开启事务,在其他的情况下,只需要返回事务状态信息就可以了。其实这个状态信息,就是事务的上下文信息。
事务上下文
通过上面的分析,每次启动事务的时候,都会判断当前是否存在事务,要么抛出异常,否则都会创新事务上下文,但是对于数据源的处理方式则是不一样的,这个要根据当前事务传播属性和新的事务传播属性共同决定。
事务上下文信息到底是什么,这个完全是可以自定义的,在spring中,主要是表现为TransactionStatus,也就是事务状态信息。里面保存了事务相关的信息,
//事务对象信息,使用普通数据源的话,是DataSourceTransactionObject对象,保存//了事务对应的连接信息 private final Object transaction; //是否是新开启的事务信息,只有调用了开启事务的方法,这个才为true private final boolean newTransaction; //这个是事务同步器,不是事务要关心的,spring在事务提交之前或者之后座的hook private final boolean newSynchronization; //是否是只读事务 private final boolean readOnly; //日志debug信息,完全没有放在这里 private final boolean debug; //挂起的事务信息,如果没有,则为空 private final Object suspendedResources;
通过事务状态信息,就可以完全知道当前事务的所有信息,包括事务的对应的数据源连接信息,是否是新创建的事务,是否是只读事务,以及之前挂起的事务信息。这些对事务管理器起来说,都是必须的信息。但是个人觉得也存在一些问题,首先spring这个事务状态信息有两个使用者,一个是spring本身事务管理器使用,另外一个是应用程序接口。对应用程序接口暴露出来的状态信息以及内部使用的事务上下文信息应该隔离出来,避免应用程序人为的修改了事务上下文的属性信息。当然,可以用过接口的方式进行避免,但是如果知道实现原理的话,完全可以通过强制转化为实现对象,从而破坏事务其他的信息导致程序异常。当然,正常情况下不太可能有人会如此无聊。
从上面的分析来看,spring的事务管理器(这里都特指DataSourceTransactionManager)主要的工作流程就是创建事务信息,绑定数据源,获取数据库连接,提交活回滚事务,释放数据库连接,解绑数据源。其实整个事务管理器做的事情无非就是这些。让应用者更关注业务逻辑,而不是复杂的事务管理。

DataSourceTransactionManager事务管理器本身实现了ResouceManager的功能,就是返回对应的其注册的datasrouce。这是一种一对一的映射关系,也就是说一个事务管理器只能注册一个数据源,不支持多数据源的管理。一旦事务管理器开启事务,就和具体的数据源绑定了,你只能通过其对应的数据源获取数据库连接。所以在事务上下文里面操作多个数据库,是不可能的。同时也只支持单一物理数据源,也就是说一个数据源只能返回同一个数据库连接,不支持在同一个事务里面通过同一个逻辑数据源跨越多个物理库操作。下面的操作想通过ProxyDataSource切换实际的数据源的方式无法实现的。
for(String dbName : dbNames){
DataSourceContextHolder.set(“dbName”);
doSomeThing();
DataSourceContextHolder.clear();
}
想要支持跨库的事务操作,可以通过以下几种方式操作:
1 使用JtaTransactionManager,通过jta服务提供商来实现跨库事务
2 改写ProxyDataSource,通过返回其自己实现的Connection来实现跨库的事务。简单的说,返回一个逻辑的Connection,这个connection本身持有多个物理connection
3 自己实现TransactionManager,可以注册多个资源管理器,自己对多个数据源进行管理。
事务上下文的扩展
正常情通过况下,事务上下文信息都是保存在内存之中,相当于只能够支持单个jvm。可以想象一下,假设事务管理器把事务上下文信息持久化,并且通过远程调用的方式,把事务上下文信息传递给另外一个jvm,通过这样的设计思想,可以支持跨jvm间的事务一致性,也就是我们所说的分布式系统的事务。当然,这只是一中简单的想法,具体的实现会相当复杂,需要考虑点也有很多。
spring事务管理器设计思想(二)的更多相关文章
- spring事务管理器设计思想(2)
spring事务管理器设计思想(二) 上文见<spring事务管理器设计思想(一)> 对于第二个问题,涉及到事务的传播级别,定义如下: PROPAGATION_REQUIRED-- 如果当 ...
- spring事务管理器设计思想(一)
在最近做的一个项目里面,涉及到多数据源的操作,比较特殊的是,这多个数据库的表结构完全相同,由于我们使用的ibatis框架作为持久化层,为了防止每一个数据源都配置一套规则,所以重新实现了数据源,根据线程 ...
- 【面试】足够“忽悠”面试官的『Spring事务管理器』源码阅读梳理(建议珍藏)
PS:文章内容涉及源码,请耐心阅读. 理论实践,相辅相成 伟大领袖毛主席告诉我们实践出真知.这是无比正确的.但是也会很辛苦. 就像淘金一样,从大量沙子中淘出金子一定是一个无比艰辛的过程.但如果真能淘出 ...
- Spring事务管理器的应对
Spring抽象的DAO体系兼容多种数据访问技术,它们各有特色,各有千秋.像Hibernate是非常优秀的ORM实现方案,但对底层SQL的控制不太方便:而iBatis则通过模板化技术让你方便地控制SQ ...
- Spring事务管理器分类
Spring并不直接管理事务,事实上,它是提供事务的多方选择.你能委托事务的职责给一个特定的平台实现,比如用JTA或者是别的持久机制.Spring的事务管理器可以用下表表示: 事务管理器的实例 目标 ...
- spring事务管理器的源码和理解
原文出处: xieyu_zy 以前说了大多的原理,今天来说下spring的事务管理器的实现过程,顺带源码干货带上. 其实这个文章唯一的就是带着看看代码,但是前提你要懂得动态代理以及字节码增强方面的知识 ...
- Spring事务管理器
1.创建实体和接口 public class Bank { private Integer id; private String name; private String manay; public ...
- 跟我学Spring3(9.2):Spring的事务之事务管理器
原文出处: 张开涛9.2.1 概述 Spring框架支持事务管理的核心是事务管理器抽象,对于不同的数据访问框架(如Hibernate)通过实现策略接口PlatformTransactionManage ...
- 阿里面试挂了,就因为面试官说我Spring 事务管理(器)不熟练?
前言 事务管理,一个被说烂的也被看烂的话题,还是八股文中的基础股之一.但除了八股文中需要熟读并背诵的那些个传播行为之外,背后的"为什么"和核心原理更为重要. 写这篇文章之前,我 ...
随机推荐
- 域名解析与多域名绑定多个Tomcat项目
第一步.域名解析 1.登录阿里云的服务器地址:https://www.aliyun.com/ 新手礼包地址:https://s.click.taobao.com/as9o9Ox 2.点击控制台 3 ...
- NPM 使用淘宝镜像
--registry https://registry.npm.taobao.org
- 【vuejs小项目——vuejs2.0版本】组件化的开发方式
对于多张页面需要里存在相同模块,可以进行组建化的开发模式. 例如:此处需要一个评分标准组件,创建一个components/star/star.vue. 在需要引入该组建的页面上 import进去< ...
- G1 垃圾收集器
概念先知 什么是垃圾回收 简单的说垃圾回收就是回收内存中不再使用的对象. 垃圾回收的基本步骤: 查找内存中不再使用的对象 释放这些对象占用的内存 查找内存中不再使用的对象 如何判断哪些对象不再被使用呢 ...
- URAL 2089 Experienced coach Twosat
Description Misha trains several ACM teams at the university. He is an experienced coach, and he doe ...
- 在php中使用strace、gdb、tcpdump调试工具
[转] http://www.syyong.com/php/Using-strace-GDB-and-tcpdump-debugging-tools-in-PHP.html 在php中我们最常使用调试 ...
- Thinkphp3.2.3路径书写注意
尽量不要这样写: ./public/img/a.jpg 应该这样写:__PUBLIC__/img/a.jpg 不然会引起不兼容 如首页地址 http://192.168.1.100/rjshop/时
- 最简单的android自定义进度条样式
一.自定义圆形进度条样式 1.在安卓项目drawable目录下新建一个xml文件如下:<?xml version="1.0" encoding="utf-8&quo ...
- mac 终端 常用命令
基本命令1.列出文件ls 参数 目录名 例: 看看驱动目录下有什么:ls /System/Library/Extensions参数 -w 显示中文,-l 详细信息, -a 包括隐藏文件2 ...
- bfs codeforces 754B Ilya and tic-tac-toe game
这题简直把我坑死了 所有的坑都被我中了 题意: 思路:bfs or 模拟 模拟似乎没有什么坑 但是bfs真的是坑 AC代码: #include "iostream" #includ ...