jodd-cache集锦
Jodd cache提供了一组cache的实现,其层次如下:
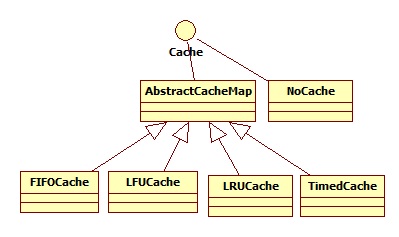
其中,
AbstractCacheMap是一个具有计时和大小的缓存map的默认实现,它的实现类必须:
创建一个新的缓存map。
实现自己的删除(prune)策略。
内部使用ReentranReadWriteLock来同步。因为从一个读锁升级到一个写锁是不可能的,因此在get(Object)方法内要注意。
FIFOCach:先进先出缓存。优点是简单高效。缺点是不灵活,没有在内存中保存常用的缓存对象。
/**
* Creates a new LRU cache.
*/
public FIFOCache(int cacheSize, long timeout) {
this.cacheSize = cacheSize;
this.timeout = timeout;
cacheMap = new LinkedHashMap<K,CacheObject<K,V>>(cacheSize + 1, 1.0f, false);
} // ---------------------------------------------------------------- prune /**
* Prune expired objects and, if cache is still full, the first one.
*/
@Override
protected int pruneCache() {
int count = 0;
CacheObject<K,V> first = null;
Iterator<CacheObject<K,V>> values = cacheMap.values().iterator();
while (values.hasNext()) {
CacheObject<K,V> co = values.next();
if (co.isExpired() == true) {
values.remove();
count++;
}
if (first == null) {
first = co;
}
}
if (isFull()) {
if (first != null) {
cacheMap.remove(first.key);
count++;
}
}
return count;
}
LFUCache:最少访问次数缓存。优点是常用缓存保留在内存中,偶然会使扫描算法失效。缺点是大的获取消耗即这个算法不能快速适应变化的使用模式,特别是集群的临时获取是无效的。
public LFUCache(int maxSize, long timeout) {
this.cacheSize = maxSize;
this.timeout = timeout;
cacheMap = new HashMap<K, CacheObject<K,V>>(maxSize + 1);
}
// ---------------------------------------------------------------- prune
/**
* Prunes expired and, if cache is still full, the LFU element(s) from the cache.
* On LFU removal, access count is normalized to value which had removed object.
* Returns the number of removed objects.
*/
@Override
protected int pruneCache() {
int count = 0;
CacheObject<K,V> comin = null;
// remove expired items and find cached object with minimal access count
Iterator<CacheObject<K,V>> values = cacheMap.values().iterator();
while (values.hasNext()) {
CacheObject<K,V> co = values.next();
if (co.isExpired() == true) {
values.remove();
onRemove(co.key, co.cachedObject);
count++;
continue;
}
if (comin == null) {
comin = co;
} else {
if (co.accessCount < comin.accessCount) {
comin = co;
}
}
}
if (isFull() == false) {
return count;
}
// decrease access count to all cached objects
if (comin != null) {
long minAccessCount = comin.accessCount;
values = cacheMap.values().iterator();
while (values.hasNext()) {
CacheObject<K, V> co = values.next();
co.accessCount -= minAccessCount;
if (co.accessCount <= 0) {
values.remove();
onRemove(co.key, co.cachedObject);
count++;
}
}
}
return count;
}
LRUCache:最近未访问缓存。缓存对象的消耗是一个常量。简单高效,比FIFO更适应一个变化的场景。缺点是可能会被不会重新访问的缓存占满空间,特别是在面对获取类型扫描时则完全不起作用。然后它是目前最常用的缓存算法。
/**
* Creates a new LRU cache.
*/
public LRUCache(int cacheSize, long timeout) {
this.cacheSize = cacheSize;
this.timeout = timeout;
cacheMap = new LinkedHashMap<K, CacheObject<K,V>>(cacheSize + 1, 1.0f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return LRUCache.this.removeEldestEntry(size());
}
};
} /**
* Removes the eldest entry if current cache size exceed cache size.
*/
protected boolean removeEldestEntry(int currentSize) {
if (cacheSize == 0) {
return false;
}
return currentSize > cacheSize;
} // ---------------------------------------------------------------- prune /**
* Prune only expired objects, <code>LinkedHashMap</code> will take care of LRU if needed.
*/
@Override
protected int pruneCache() {
if (isPruneExpiredActive() == false) {
return 0;
}
int count = 0;
Iterator<CacheObject<K,V>> values = cacheMap.values().iterator();
while (values.hasNext()) {
CacheObject<K,V> co = values.next();
if (co.isExpired() == true) {
values.remove();
count++;
}
}
return count;
}
TimedCache 不限制大小,只有当对象过期时才会删除。标准的chache方法不会显式的调用删除(prune),而是根据定义好的延迟进行定时删除。
public TimedCache(long timeout) {
this.cacheSize = 0;
this.timeout = timeout;
cacheMap = new HashMap<K, CacheObject<K,V>>();
}
// ---------------------------------------------------------------- prune
/**
* Prunes expired elements from the cache. Returns the number of removed objects.
*/
@Override
protected int pruneCache() {
int count = 0;
Iterator<CacheObject<K,V>> values = cacheMap.values().iterator();
while (values.hasNext()) {
CacheObject co = values.next();
if (co.isExpired() == true) {
values.remove();
count++;
}
}
return count;
}
// ---------------------------------------------------------------- auto prune
protected Timer pruneTimer;
/**
* Schedules prune.
*/
public void schedulePrune(long delay) {
if (pruneTimer != null) {
pruneTimer.cancel();
}
pruneTimer = new Timer();
pruneTimer.schedule(
new TimerTask() {
@Override
public void run() {
prune();
}
}, delay, delay
);
}
/**
* Cancels prune schedules.
*/
public void cancelPruneSchedule() {
if (pruneTimer != null) {
pruneTimer.cancel();
pruneTimer = null;
}
}
注意,还提供了一个FileLFUCache,没有继承AbstractCacheMap.用LFU将文件缓存到内存,极大加快访问常用文件的性能。
protected final LFUCache<File, byte[]> cache;
protected final int maxSize;
protected final int maxFileSize; protected int usedSize; /**
* Creates file LFU cache with specified size. Sets
* {@link #maxFileSize max available file size} to half of this value.
*/
public FileLFUCache(int maxSize) {
this(maxSize, maxSize / 2, 0);
} public FileLFUCache(int maxSize, int maxFileSize) {
this(maxSize, maxFileSize, 0);
} /**
* Creates new File LFU cache.
* @param maxSize total cache size in bytes
* @param maxFileSize max available file size in bytes, may be 0
* @param timeout timeout, may be 0
*/
public FileLFUCache(int maxSize, int maxFileSize, long timeout) {
this.cache = new LFUCache<File, byte[]>(0, timeout) {
@Override
public boolean isFull() {
return usedSize > FileLFUCache.this.maxSize;
} @Override
protected void onRemove(File key, byte[] cachedObject) {
usedSize -= cachedObject.length;
} };
this.maxSize = maxSize;
this.maxFileSize = maxFileSize;
} // ---------------------------------------------------------------- get /**
* Returns max cache size in bytes.
*/
public int getMaxSize() {
return maxSize;
} /**
* Returns actually used size in bytes.
*/
public int getUsedSize() {
return usedSize;
} /**
* Returns maximum allowed file size that can be added to the cache.
* Files larger than this value will be not added, even if there is
* enough room.
*/
public int getMaxFileSize() {
return maxFileSize;
} /**
* Returns number of cached files.
*/
public int getCachedFilesCount() {
return cache.size();
} /**
* Returns timeout.
*/
public long getCacheTimeout() {
return cache.getCacheTimeout();
} /**
* Clears the cache.
*/
public void clear() {
cache.clear();
usedSize = 0;
} // ---------------------------------------------------------------- get public byte[] getFileBytes(String fileName) throws IOException {
return getFileBytes(new File(fileName));
} /**
* Returns cached file bytes.
*/
public byte[] getFileBytes(File file) throws IOException {
byte[] bytes = cache.get(file);
if (bytes != null) {
return bytes;
} // add file
bytes = FileUtil.readBytes(file); if ((maxFileSize != 0) && (file.length() > maxFileSize)) {
// don't cache files that size exceed max allowed file size
return bytes;
} usedSize += bytes.length; // put file into cache
// if used size > total, purge() will be invoked
cache.put(file, bytes); return bytes;
}
jodd-cache集锦的更多相关文章
- jodd cache实现缓存超时
public class JoddCache { private static final int CACHE_SIZE = 2; private final static Cache<Obje ...
- 『奇葩问题集锦』Malformed lock file found: /var/cache/dnf/metadata_lock.pid.
Malformed lock file found: /var/cache/dnf/metadata_lock.pid.Ensure no other dnf process is running a ...
- java jodd轻量级开发框架
http://git.oschina.net/huangyong/jodd_demo/blob/master/jodd-example/src/main/java/jodd/example/servi ...
- 大型互联网架构概述 关于架构的架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE
大型互联网架构概述 目录 架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE 本文旨在简单介绍大型互联网的架构和核心组件实现原理. 理论上讲,从安装配置 ...
- springboot项目部署到独立tomcat的爬坑集锦
目录 集锦一:普通的springboot项目直接部署jar包 集锦二:springboot项目不能直接打war包部署 集锦三:因为tomcat版本问题导致的lombok插件报错:Invalid byt ...
- bug集锦------持续但不定期 更新
对于个人而言:这个错误集锦是很有必要的. 为了避免误导他人,其中个人想法:用 紫色加粗 标注. 1.springboot端口冲突: Protocol handler start failed2.spr ...
- 13 Zabbix4.4.1系统告警“More than 75% used in the configuration cache”
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 13 Zabbix4.4.1系统告警“More than 75% used in the conf ...
- Jodd - Java界的瑞士军刀轻量级工具包!
Jodd介绍 Jodd是对于Java开发更便捷的开源迷你框架,包含工具类.实用功能的集合,总包体积不到1.7M. Jodd构建于通用场景使开发变得简单,但Jodd并不简单!它能让你把事情做得更好,实现 ...
- Redis面试题集锦(精选)
1.什么是 Redis?简述它的优缺点? Redis的全称是:Remote Dictionary.Server,本质上是一个Key-Value 类型的内存数据库,很像memcached,整个数据库统统 ...
随机推荐
- jsp静态引入(<%@ include file=""%>) 乱码问题
在web.xml中的web-app中加入这段话: <jsp-config> <jsp-property-group> <display-name>JSPConfig ...
- STL 之 hash_map源代码剖析
// Filename: stl_hash_map.h // hash_map和hash_multimap是对hashtable的简单包装, 非常easy理解 /* * Copyright (c) 1 ...
- Microsoft office2016(专业增强版) 安装错误,报CRT(KB2999226)
对着这个错误的出现,网上有解释,这里不多说(实际是我没有找到比较靠谱的说法..),跟Window Update这个服务有关. 首先打开”Windows人为管理器”->"服务" ...
- ES6学习笔记(六)数组的扩展
1.扩展运算符 1.1含义 扩展运算符(spread)是三个点(...).它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) // ...
- UVC和V4L2的关系(转载)
UVC是一种usb视频设备驱动.用来支持usb视频设备,凡是usb接口的摄像头都能够支持 V4L2是Linux下的视频采集框架.用来统一接口,向应用层提供API UVC: USB video clas ...
- CentOS-6.4-minimal版中安装JDK_Maven_Subversion以及改动rpm包安装路径
完整版见https://jadyer.github.io/2013/09/07/centos-config-develop/ /** * @see -------------------------- ...
- OCP将结束容器产业这个颠覆性产业的标准格式之争
编者注:本文英文版来自VentureBeat,中文版由天地会珠海分舵编译.当以Docker为首的容器正在席卷全球.蔚然成风的颠覆着原来的应用开发和公布方式的时候,容器标准之争却从来没有消停过.而标准之 ...
- 在vim中配置python补全,fedora 19
近期发现python是个不错的语言,值得一学,先配置下环境,让vim具有keyword补全功能,步骤例如以下,我这个是fedora,其它发行版类似 $ su ******** # yum instal ...
- jquery08
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- js---14公有私有成员方法
var ns1 = {}; //命名空间 ns1.ns11 = {};//子命名空间 ns1.module1 = {name:"a",m:function(){}}; consol ...