《TensorFlow2深度学习》学习笔记(三)Tensorflow进阶
本篇笔记包含张量的合并与分割,范数统计,张量填充,限幅等操作。
1.合并与分割
合并
张量的合并可以使用拼接(Concatenate)和堆叠(Stack)操作实现,拼接并不会产生新的维度,而堆叠会创建新维度。选择使用拼接还是堆叠操作来合并张量,取决于具体的场景是否需要创建新维度。
拼接 在 TensorFlow 中,可以通过 tf.concat(tensors, axis),其中 tensors 保存了所有需要合并的张量 List,axis 指定需要合并的维度。合并操作可以在任意的维度上进行,唯一的约束是非合并维度的长度必须一致。
a = tf.random.normal([4,35,8]) # 模拟成绩册 A
b = tf.random.normal([6,35,8]) # 模拟成绩册 B
tf.concat([a,b],axis=0) # 合并成绩册
Out[1]:
<tf.Tensor: id=13, shape=(10, 35, 8), dtype=float32, numpy=...>
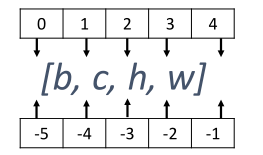
堆叠 如果在合并数据时,希望创建一个新的维度,则需要使用 tf.stack 操作。使用 tf.stack(tensors, axis)可以合并多个张量 tensors,其中 axis 指定插入新维度的位置,axis 的用法与 tf.expand_dims 的一致,当axis ≥ 0时在 axis 之前插入;当axis < 0时,在 axis 之后插入新维度。axis 参数对应的插入位置设置如图:
a = tf.random.normal([35,8])
b = tf.random.normal([35,8])
tf.stack([a,b],axis=0)
Out[4]:
<tf.Tensor: id=55, shape=(2, 35, 8), dtype=float32, numpy=...>
tf.stack 也需要满足张量堆叠合并条件,它需要所有合并的张量 shape 完全一致才可合并。
分割
通过 tf.split(x, axis, num_or_size_splits)可以完成张量的分割操作,其中x代表待分割张量;axis代表分割的维度索引号;num_or_size_splits代表切割方案。当 num_or_size_splits 为单个数值时,如 10,表示切割为 10 份;当 num_or_size_splits 为 List 时,每个元素表示每份的长度,如[2,4,2,2]表示切割为 4 份,每份的长度分别为 2,4,2,2
x = tf.random.normal([10,35,8])
# 等长切割
result = tf.split(x,axis=0,num_or_size_splits=10)
result[0]
Out[9]: <tf.Tensor: id=136, shape=(1, 35, 8), dtype=float32, numpy=...>
切割后的shape 为[1,35,8],保留了维度,这一点需要注意。
特别地,如果希望在某个维度上全部按长度为 1 的方式分割,还可以直接使用 tf.unstack(x,axis)。这种方式是 tf.split 的一种特殊情况,切割长度固定为 1,只需要指定切割维度即可。
x = tf.random.normal([10,35,8])
result = tf.unstack(x,axis=0) # Unstack 为长度为 1
result[0]
Out[12]: <tf.Tensor: id=166, shape=(35, 8), dtype=float32, numpy=...>
可以看到,通过 tf.unstack 切割后,shape 变为[35,8],即班级维度消失了,这也是与 tf.split区别之处。
2.数据统计
在神经网络的计算过程中,经常需要统计数据的各种属性,如最大值,均值,范数等等。由于张量通常 shape 较大,直接观察数据很难获得有用信息,通过观察这些张量统计信息可以较轻松地推测张量数值的分布。
向量范数
向量范数(Vector norm)是表征向量“长度”的一种度量方法,对于矩阵、张量,同样可以利用向量范数的计算公式,等价于将矩阵、张量打平成向量后计算。在神经网络中,常用来表示张量的权值大小,梯度大小等。常用的向量范数有:
- L1 范数,定义为向量
《TensorFlow2深度学习》学习笔记(三)Tensorflow进阶的更多相关文章
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- JS学习笔记 (三) 对象进阶
1.JS对象 1.1 JS对象特征 1.JS对象是基本数据数据类型之一,是一种复合值,可以看成若干属性的集合. 属性是名值对的形式(key:value) 属性名是字符串,因此可以把对象看成是字符串到值 ...
- Scala学习教程笔记三之函数式编程、集合操作、模式匹配、类型参数、隐式转换、Actor、
1:Scala和Java的对比: 1.1:Scala中的函数是Java中完全没有的概念.因为Java是完全面向对象的编程语言,没有任何面向过程编程语言的特性,因此Java中的一等公民是类和对象,而且只 ...
- U3D学习使用笔记(三)
1.对动画进行播放和暂停(从初始位置) (1).老版动画系统Animation 暂停 an["Take 001"].time = 0f; an["Take 001&quo ...
- 深度学习课程笔记(三)Backpropagation 反向传播算法
深度学习课程笔记(三)Backpropagation 反向传播算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- 深度学习word2vec笔记之算法篇
深度学习word2vec笔记之算法篇 声明: 本文转自推酷中的一篇博文http://www.tuicool.com/articles/fmuyamf,若有错误望海涵 前言 在看word2vec的资料 ...
- 深度学习word2vec笔记之基础篇
作者为falao_beiliu. 作者:杨超链接:http://www.zhihu.com/question/21661274/answer/19331979来源:知乎著作权归作者所有.商业转载请联系 ...
随机推荐
- java导出pdf功能记录
这几天已在做处理导出pdf文件的功能,摸索了几天总算可以了.记录下这几天遇到的问题. 1.网上基本都是基于Itext5和Itext7来处理的.我最终是在Itext5上成功了,itext7应该是模板出问 ...
- html中测试div、ul和li、table排列多个块
前面有三篇博文测试了这三种方式,一.相关博文:LODOP问答部分链接.该文用的是div定位,用的是所有小div相对于大div进行定位,大的div设置relative定位,小的设置absolute相对于 ...
- 【python库模块】Python subprocess模块功能与常见用法实例详解
前言 这篇文章主要介绍了Python subprocess模块功能与常见用法,结合实例形式详细分析了subprocess模块功能.常用函数相关使用技巧. 参考 1. Python subprocess ...
- 【视频开发】Gstreamer中一些gst-launch常用命令
GStreamer是著名的开源多媒体框架,功能强大,其命令行程序 gst-launch 可以实现很多常规测试.播放等,作为系统调试等是非常方便的. 1.摄像头测试 gst-launch v4l2src ...
- 使用HOSTNAMECTL配置主机名
hostnamectl工具是用来管理给定主机中. 查看所有主机名 请运行下面的命令查看所有当前主机名: 〜] $ hostnamectl status 如果未指定任何选项,默认则使用status选项对 ...
- 全网最详细的Windows里Git client客户端管理工具SourceTree的下载与安装(图文详解)
不多说,直接上干货! 很多人用Git命令行不熟练,那么可以尝试使用SourceTree进行操作. 安装之前的必备 (1)Git的安装 Git学习系列之Windows上安装Git详细步骤(图文详解 ...
- day25——私有成员、类方法、静态方法、属性、isinstance和issubclass的区别
day25 类的私有成员 当你遇到重要的数据,功能(只允许本类使用的一些方法,数据)设置成私有成员 python所有的私有成员都是纸老虎,形同虚设 类从加载时,只要遇到类中的私有成员,都会在私有成员前 ...
- C++ Primer中文第四版
C++ Primer中文第四版 在简书上发现有挂羊头卖狗肉的,发的plus,而且压缩包还得付钱获取密码,我直接去github搜到了第四版,在此分享一下. 格式:pdf 书签目录:有 下载地址: ...
- epoll原理
系统调用说明 epoll_create:在内核中创建epoll结构 epoll_ctl:add 1. 调用监听的文件的poll方法,设置callback 2. 设备就绪时唤醒等待队列上的进程,此时会调 ...
- Java自学-类和对象 引用
什么是Java中的引用? 引用的概念,如果一个变量的类型是 类类型,而非基本类型,那么该变量又叫做引用. 步骤 1 : 引用和指向 new Hero(); 代表创建了一个Hero对象 但是也仅仅是创建 ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening