【数据结构】12.java源码关于ConcurrentHashMap
目录
1.ConcurrentMap的内部结构
2.ConcurrentMap构造函数
3.元素新增策略
4.元素删除
5.元素修改和查找
6.特殊操作
7.扩容
8.总结
1.ConcurrentMap内部结构
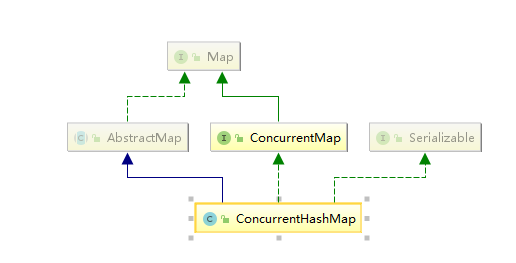
继承自abstractMap,实现concurrentMap接口,父类和hashmap相似
在开始之前大家应该都了解过concurrentHashmap是通过分段锁的方式实现多线程安全的
(这里了解到1.8之后似乎也抛弃了分段锁的概念,我们看看吧)
concurrentHashMap内部存在一个node数据结构用来存放元素
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;
final K key;
volatile V val;
volatile Node<K, V> next;
Node(int hash, K key, V val, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
@Override
public final K getKey() {
return key;
}
@Override
public final V getValue() {
return val;
}
//做疑惑操作获取结果
@Override
public final int hashCode() {
return key.hashCode() ^ val.hashCode();
}
@Override
public final String toString() {
return key + "=" + val;
}
@Override
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
@Override
public final boolean equals(Object o) {
Object k, v, u;
Map.Entry<?, ?> e;
//是Map.Entry的子类,并且key相同,value相同,且都不为空
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?, ?>) o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
* 这个是用来寻找某个节点,当做链表的方式寻找
*/
Node<K, V> find(int h, Object k) {
Node<K, V> e = this;
if (k != null) {
do {
K ek;
boolean ok = e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek)));
if (ok) {
return e;
}
} while ((e = e.next) != null);
}
return null;
}
}
用来保存树节点的数据结构
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
@Override
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
* 寻找树节点,二叉查找树
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h) {
//如果当前的hash散列值大于h,那么目标就在这个节点左边
p = pl;
}
else if (ph < h) {
//小于就在右边
p = pr;
}
else if ((pk = p.key) == k || (pk != null && k.equals(pk))) {
//恰好相等直接返回
return p;
}
else if (pl == null) {
//如果为空,那么就走另外一边
p = pr;
}
else if (pr == null) {
p = pl;
}
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0) {
p = (dir < 0) ? pl : pr;
}
else if ((q = pr.findTreeNode(h, k, kc)) != null) {
return q;
}
else {
p = pl;
}
} while (p != null);
}
return null;
}
}
2.ConcurrentMap构造函数
如果是默认的构造函数就是啥都没有就是个空的
public TestConcurrentMap() {
}
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
public TestConcurrentMap(int initialCapacity) {
if (initialCapacity < 0) {
throw new IllegalArgumentException();
}
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
这里的操作就是子啊初始化容量的时候把容量大小控制为比设置的值要大的最小二次幂!!!
为什么呢?因为>>>是无符号右移动,
1.也就是在右移的时候会吧最高位的1移动到下一位,也就是会形成 0。。。010。。。 的数据和0。。。100。。。那么一个|操作之后那就是0。。。110。。。
2.然后又移动2位,那就是吧之前合并的2个1再往后合并成1
。。。最终的结果就是0000111111111。。。
因为int是4个字节,也就是32位,那么最后一次只需要又移16位,就可以吧剩下的一半全部搞定!!!

这里这样图解应该就OK了吧
3.元素新增策略
我们并没有在容器初始化的时候就构建table的实例化,而是在put操作添加数据的时候才会进行init初始化实例数据
/**
* 初始化table大小
*
* @return
*/
private final Node<K, V>[] initTable() {
Node<K, V>[] tab;
int sc;
//开始循环初始化,当表还是为空的时候不断循环
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0) {
// 线程跳转,如果sc的大小小于0,那么就切换线程,当小于0的时候表示在别的线程在初始化表或扩展表
Thread.yield();
}
//SIZECTL:表示当前对象的内存偏移量,sc表示期望值,-1表示要替换的值,设定为-1表示要初始化表了
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//进来之后再判断一次是否为空
if ((tab = table) == null || tab.length == 0) {
//获取初始化大小
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
//创建指定长度容量的数组
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
table = tab = nt;
//设置sc大小为去掉1/4,这个就是类似加载因子0.75,实际可用大小
sc = n - (n >>> 2);
}
} finally {
//初始化完毕设置成想要的值 初始化后,sizeCtl长度为数组长度的3/4
sizeCtl = sc;
}
break;
}
}
return tab;
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) {
throw new NullPointerException();
}
//二次hash,为了减少碰撞
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0) {
tab = initTable();
} else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null))) {
// no lock when adding to empty bin
break;
}
} else if ((fh = f.hash) == MOVED) {
//如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制
tab = helpTransfer(tab, f);
} else {
//如果hash值一样的位置有值了,那么就需要对指定的槽位f(指定槽位的引用)上锁
V oldVal = null;
synchronized (f) {
//再比较一次
if (tabAt(tab, i) == f) {
//fh 这个位置的hash值如果大于0,说明不是在扩容阶段
if (fh >= 0) {
binCount = 1;
for (Node<K, V> e = f; ; ++binCount) {
K ek;
//判断hash是否相等,判断是否在一个槽位,判断key是否相等,判断是否一个元素,
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) {
//如果hash和key都相等,那么直接替换值即可
e.val = value;
}
break;
}
Node<K, V> pred = e;
//指向下一个节点,如果key不等
if ((e = e.next) == null) {
//创建新的节点加入
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
} else if (f instanceof TreeBin) {
Node<K, V> p;
binCount = 2;
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) {
p.val = value;
}
}
}
}
}
//记录长度
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) {
treeifyBin(tab, i);
}
if (oldVal != null) {
return oldVal;
}
break;
}
}
}
addCount(1L, binCount);
return null;
}
对于插入操作,其实和hashmap是一样的,然后就是多了个扩容不一样
其他至于红黑树的平衡,这个可以参考我之前的博客treeMap应该有详解-》https://www.cnblogs.com/cutter-point/p/11587453.html
并且因为在插入的时候有对当前位置上锁,所以考虑到了多线程的问题,并且在树进行平衡的时候,也会在加一道锁
lockRoot();
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
这样就保证了在进行平衡操作的时候支持多线程
至于上锁技术,我们后面多线程单独开栏目详细探讨
4.元素删除
元素删除,参考添加,还有之前treemap,这个也不多bb了好吧,其实是被这个玩意整的有点疲劳。。。
哎,最近写这个博客耗费太多时间了,也就不再重复的事情上多做功夫,无非还是树的再平衡,和之前treemap差不多的
5.元素修改和查找
查找略,参考之前map操作,因为这个不涉及多线程,所以和之前没差别
6.特殊操作
//获取node的类对象
Class<?> ak = Node[].class;
//可以获取对象第一个元素的偏移地址
ABASE = U.arrayBaseOffset(ak);
//可以获取数组的转换因子,也就是数组中元素的增量地址。
//将arrayBaseOffset与arrayIndexScale配合使用,可以定位数组中每个元素在内存中的位置。
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0) { throw new Error("data type scale not a power of two");
}
// 给定一个int类型数据,返回这个数据的二进制串中从最左边算起连续的“0”的总数量。因为int类型的数据长度为32所以高位不足的地方会以“0”填充。
//这个就是计算地址有多少位的长度,也就是一个NODE对象的偏移
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
//读取tab这个对象中的数据,第二个参数是偏移量,比如第i个,那么就偏移i个对象的大小ashift
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
//通过cas操作设置值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
//和C比较,设置为V
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
//设置指定位置的数据为V
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
这个地方是通过unsafe计算出NODE这个类起始位置的偏移量大小,然后通过unsafe计算每个指定的元素的偏移位置,然后把数据值设置进去,unsafe提供硬件级别的操作
7.扩容
再put元素的时候,我们添加完元素之后,我们会判断链表长度是否超出8个,如果是转换为红黑树,然后判断数组hash桶的长度是否超过64,如果小于64那么就扩大为原来的2倍
1.也就是说,扩容发生在链表转换红黑树的时候
2.还有一个情况就是添加完毕元素之后,会有个addCount这个方法也会触发扩容
在转换为红黑树的时候,我们会调用treeifyBin 方法,这个时候判断如果长度小于64的时候,会调用tryPresize 这个方法进行扩容
/**
* 在同一个节点的个数超过8个的时候,会调用treeifyBin方法来看看是扩容还是转化为一棵树
* @param tab
* @param index
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//先判断是否这个tab列表的长度小于64
if ((n = tab.length) < MIN_TREEIFY_CAPACITY) {
//tryPresize方法把数组长度扩大到原来的两倍
tryPresize(n << 1);
} else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) { //使用synchronized同步器,将该节点出的链表转为树
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null; //hd:树的头(head)
//循环遍历链表
for (Node<K,V> e = b; e != null; e = e.next) {
//依次转换为treeNode
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null);
//把Node组成的链表,转化为TreeNode的链表,头结点任然放在相同的位置
//这里吧p的前置节点设置为上一个节点,也就是尾插法
if ((p.prev = tl) == null) {
hd = p;
} else {
tl.next = p;
}
tl = p;
}
//吧这个TreeNode组成的链表设置进入指定的位置
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
然后进入tryPreSize判断是直接开始扩容,还是多线程辅助帮助一起扩容
/**
* 扩容表为指可以容纳指定个数的大小(总是2的N次方)
* 假设原来的数组长度为16,则在调用tryPresize的时候,size参数的值为16<<1(32),此时sizeCtl的值为12
* 计算出来c的值为64
* 第一次扩容之后 数组长:32 sizeCtl:24
* 第二次扩容之后 数组长:64 sizeCtl:48
* 第二次扩容之后 数组长:128 sizeCtl:94 --> 这个时候才会退出扩容
*/
private final void tryPresize(int size) {
//大小变为2的幂次,size是原来大小的2倍(扩容的时候)
/*
* MAXIMUM_CAPACITY = 1 << 30
* 如果给定的大小大于等于数组容量的一半,则直接使用最大容量,
* 否则使用tableSizeFor算出来
* 后面table一直要扩容到这个值小于等于sizeCtrl(数组长度的3/4)才退出扩容
*/
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1);
int sc;
//判断当前实际容量是否大于0
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
//sc是这个对象的可用实际容量,判断tab是否被初始化
if (tab == null || (n = tab.length) == 0) {
//基础hash桶没有被初始化
//那么就初始化为计算出来的c和原来的sc中大的那个
n = (sc > c) ? sc : c;
//吧this对象的sizeCtl比较sc判断是否是sc,如果可以设置为-1
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//判断是否当前线程操作
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
//计算设置新的sc,设置为容量大小的0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
} else if (c <= sc || n >= MAXIMUM_CAPACITY) {
//如果容量c比原来的sc还要小,或者数组长度比最大容量还大那么就不用扩容了
break;
} else if (tab == table) {
//获取高位0的个数
int rs = resizeStamp(n);
if (sc < 0) {
//如果sc<0 说明还在扩容过程中
Node<K,V>[] nt;
//判断能否加入一起扩容
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0) {
break;
} /*
* transfer的线程数加一,该线程将进行transfer的帮忙
* 在transfer的时候,sc表示在transfer工作的线程数
*/
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) { transfer(tab, nt);
}
} else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) { transfer(tab, null);
}
}
}
}
最后我们看看真正的扩容逻辑
transfer
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//NCPU个数,判断每个核心处理的个数是否小于最小处理个数,如果是,那么就设置成16
//吧数组长度/8然后再除以cpu核心数,如果小于16,那么就改为16,如果如果不是小于16,那么就用这个长度作为这个线程的处理个数
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) {
stride = MIN_TRANSFER_STRIDE; // subdivide range
}
/*
* 如果复制的目标nextTab为null的话,则初始化一个table两倍长的nextTab
* 此时nextTable被设置值了(在初始情况下是为null的)
* 因为如果有一个线程开始了表的扩张的时候,其他线程也会进来帮忙扩张,
* 而只是第一个开始扩张的线程需要初始化下目标数组
*/
if (nextTab == null) { // initiating
try {
//直接创建新的node数组,长度加大一倍
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
//设置到nextTable上
nextTable = nextTab;
//设置偏移量
transferIndex = n;
}
int nextn = nextTab.length;
//创建forwardingnode对象,这个是用来控制并发的,当一个节点为空或已经被转移之后,就设置为fwd节点
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
//是否继续向前查找的标志位
boolean advance = true;
//在完成之前重新在扫描一遍数组,看看有没完成的
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
//判断是否进入扩容
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing) {
advance = false;
} else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
} else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
//设置偏移量为,nextIndex > stride ? nextIndex - stride : 0
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//判断是否完成
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) {
return;
}
finishing = advance = true;
i = n; // recheck before commit
}
} else if ((f = tabAt(tab, i)) == null) { //数组中把null的元素设置为ForwardingNode节点(hash值为MOVED[-1])
advance = casTabAt(tab, i, null, fwd);
} else if ((fh = f.hash) == MOVED) {
//已经进入扩容
advance = true; // already processed
} else {
//f是指向第i个位置的节点
synchronized (f) {
if (tabAt(tab, i) == f) {
//下面关键是把链表拆分为2个部分
Node<K,V> ln, hn;
if (fh >= 0) { //该节点的hash值大于等于0,说明是一个Node节点
/*
* 因为n的值为数组的长度,且是power(2,x)的,所以,在&操作的结果只可能是0或者n
* 根据这个规则,我们计算hash位置的的时候
* 把高16和低16位进行异或操作
* (h ^ (h >>> 16)) & HASH_BITS
* 0--> 放在新表的相同位置
* n--> 放在新表的(n+原来位置)
* fh就是指定节点的hash值
* 如果还是0那么就是这个hash值和n的取余操作还是0,如果是n
* n的值是老数组的长度,用来判断位置是否改变
* 我们取余的方式使(n-1)&hashcode 因为n是2的倍数所以是01111111111&hashcode
* 因为是扩大了2倍那么新的数组的取余方式其实就是n&hashcode
*
* 因为之前取余是(n-1)&hashcode 然后如果数组扩大2倍,也就是新的链表上要定位的话,其实应该是(2n-1)hashcode
比之前多了一位,如果还是定位到多的这一位的下面,那么就不需要进行移动,也就是说有可能造成定位位置不一样的话,只有2n所在的最高的那一位的1
n:000100000000 -》 n-1 : 000011111111
2n: 001000000000 -》2n-1: 000111111111
也就是我们只要计算hashcode&n就可以知道应该换位置,还是和原来的位置保持一致了
*/
int runBit = fh & n;
//指定节点位置
Node<K,V> lastRun = f;
/*
* lastRun 表示的是需要复制的最后一个节点
* 每当新节点的hash&n -> b 发生变化的时候,就把runBit设置为这个结果b
* 这样for循环之后,runBit的值就是最后不变的hash&n的值
* 而lastRun的值就是最后一次导致hash&n 发生变化的节点(假设为p节点)
* 为什么要这么做呢?因为p节点后面的节点的hash&n 值跟p节点是一样的,
* 所以在复制到新的table的时候,它肯定还是跟p节点在同一个位置
* 在复制完p节点之后,p节点的next节点还是指向它原来的节点,就不需要进行复制了,自己就被带过去了
* 这也就导致了一个问题就是复制后的链表的顺序并不一定是原来的倒序
* runBit的值就是最后不变的hash&n的值 是值在这个链表中的最后一次变化了的位置
*/
for (Node<K,V> p = f.next; p != null; p = p.next) {
//p的hash值&n的结果,因为N是扩大2倍,那么值钱的node节点如果hash值是小于n的结果对新的位置进行取余,位置还是原来的位置
int b = p.hash & n; //n的值为扩张前的数组的长度
//判断从这位置开始是否会改变位置,如果老的hash值跟n进行&操作还是保持不变,那么扩容之后还是原来的位置
if (b != runBit) {
runBit = b;
//获取最后一次变化hash&n的节点位置
lastRun = p;
}
}
//如果runBit==0,说明低位重用
if (runBit == 0) {
ln = lastRun;
hn = null;
} else {
// 如果最后更新的 runBit 是 1, 设置高位节点
hn = lastRun;
ln = null;
}
/*
* 构造两个链表,顺序大部分和原来是反的
* 分别放到原来的位置和新增加的长度的相同位置(i/n+i)
*/
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0) {
//如果是0那么创建节点拼接到ln上
ln = new Node<K,V>(ph, pk, pv, ln);
} else {
//否则拼接到hn上
hn = new Node<K,V>(ph, pk, pv, hn);
}
}
//吧链表定位到第i个位置上
setTabAt(nextTab, i, ln);
//吧第二个链接到新扩大的节点上n
setTabAt(nextTab, i + n, hn);
//吧原来的位置的i位置设置为fwd标识正在扩容
setTabAt(tab, i, fwd);
advance = true;
} else if (f instanceof TreeBin) { //判断这个位置的节点是否是一个树形的节点
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null) {
lo = p;
} else {
loTail.next = p;
}
loTail = p;
++lc;
} else {
if ((p.prev = hiTail) == null) {
hi = p;
} else {
hiTail.next = p;
}
hiTail = p;
++hc;
}
}
/*
* 在复制完树节点之后,判断该节点处构成的树还有几个节点,
* 如果≤6个的话,就转回为一个链表
*/
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
还有一点,因为是多线程安全的,这里有个特殊操作,当进行扩容的时候,put操作进去会有个helpTransfer的函数,协助扩容,没错也就是多线程扩容,这就很NB了
至于扩容的操作我们后面再讲,反正这里需要知道的是这个方法如何参与进去,形成多线程扩容的作用
在扩容的时候,有个疑问!!!
为什么int runBit=fh&n;的值可以判断这个节点位置的链表是否需要进行重定位
这个地方我网上找了很多地方都没有明确说明是为什么。
其实要解答这个问题还得从hashMap的取余方式说起,这个在我之前的hashmap篇有说明
因为之前取余是(n-1)&hashcode 然后如果数组扩大2倍,也就是新的链表上要定位的话,其实应该是(2n-1)hashcode
比之前多了一位,如果还是定位到多的这一位的下面,那么就不需要进行移动,也就是说有可能造成定位位置不一样的话,只有2n所在的最高的那一位的1
n:000100000000 -》 n-1 : 000011111111
2n: 001000000000 -》2n-1: 000111111111
也就是我们只要计算hashcode&n就可以知道应该换位置,还是和原来的位置保持一致了
8.总结
参考:
https://www.cnblogs.com/zerotomax/p/8687425.html
https://segmentfault.com/a/1190000019014835
https://blog.csdn.net/xia744510124/article/details/89478031
https://blog.csdn.net/zmx729618/article/details/78528227
https://www.cnblogs.com/softidea/p/10261414.html
【数据结构】12.java源码关于ConcurrentHashMap的更多相关文章
- Java源码之ConcurrentHashMap
⑴背景 ConcurrentHashMap是线程安全高效的HashMap.而HashMap在多线程情况下强行使用HashMap的put方法可能会导致程序死循环,使CPU使用率达到100%.(http: ...
- Java 源码刨析 - HashMap 底层实现原理是什么?JDK8 做了哪些优化?
[基本结构] 在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的: JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构,它的 ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- Programming a Spider in Java 源码帖
Programming a Spider in Java 源码帖 Listing 1: Finding the bad links (CheckLinks.java) import java.awt. ...
- [收藏] Java源码阅读的真实体会
收藏自http://www.iteye.com/topic/1113732 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我 ...
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
随机推荐
- [PHP] Laravel 5.5 打印SQL语句
[PHP] Laravel 5.5 打印SQL语句 四种方法 第一种方法: 打印SQL默认是关闭的,需要在/vendor/illuminate/database/Connection.php中打开. ...
- request登录案例
一.案例需求 1.编写login.html登录页面 username & password 两个输入框 2.使用Druid数据库连接池技术,操作mysql,day14数据库中user表 3.使 ...
- 洛谷P3258 [JLOI]2014松鼠的新家
题目 树上差分 树上点差分,注意会出现路径端点多记录的情况,这时需要在最后输出的时候输出子树的差分数组的和-1,而不是在处理原数据的时候减1.并且a[n]不需要糖果,最后也减去就行. #include ...
- 一起学Makefile(四)
变量的定义 makefile中的变量,与C语言中的宏类似,它为一个文本字符串(变量的值,其类型只能是字符串类型)提供了一个名字(变量名). 变量的基本格式: 变量名 赋值符 变量值 变量名指的 ...
- UDF——Fluent与Matlab数据耦合
本文编译工具:VC++ UDF Studio 该插件可以直接在Visual Studio中一键编译.加载.调试UDF源码,极大提高编写排错效率,且支持C++,MFC,Windows API和第三方库, ...
- redis渐进式rehash机制
在Redis中,键值对(Key-Value Pair)存储方式是由字典(Dict)保存的,而字典底层是通过哈希表来实现的.通过哈希表中的节点保存字典中的键值对.我们知道当HashMap中由于Hash冲 ...
- GlusterFS 安装
一.简介 GlusterFS 是近年兴起的一个高性能开源分布式文件系统,其目标是全局命名空间.分布式前端的高性能文件系统,目前已被 RedHat 看中,GlusterFS 具有高扩展.高可性.高性能. ...
- quartz 1.6.2之前的版本,定时任务自动停掉问题
https://searchcode.com/codesearch/view/28831622/ Quartz 1.6.2 Release Notes This release contains a ...
- Metasploit使用内网跳板, 扫描局域网主机
最近,拿到一台内网机器, 苦于无法使用nmap扫描改主机的内网, 所以才有此文 在跳板机子获取一定权限后,需要积极的向内网主机权限发展,获取指定的目标信息,探查系统漏洞,借助msf已经得到的meter ...
- Python适合练手的项目
原文地址:https://www.jianshu.com/p/039156321e30 项目地址:https://github.com/DeqianBai/Python-Project/tree/ma ...