Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。
其实最大改变的是hdfs,hdfs 通过最近black块计算,根据最近计算原则,本地black块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果。
1. Hadoop 3.0简介
Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,而这正是hadoop 3.0。
Hadoop 3.0的alpha版预计今年夏天发布,GA版本11月或12月发布。
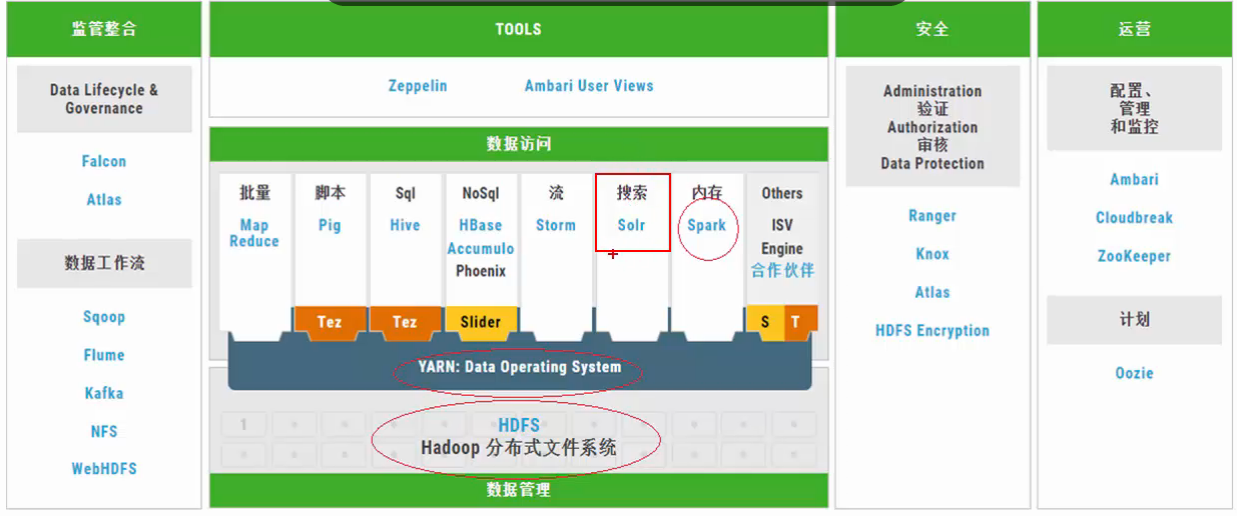
Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。

2. Hadoop 3.0新特性
Hadoop 3.0在功能和性能方面,对hadoop内核进行了多项重大改进,主要包括:
2.1 Hadoop Common
(1)精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现(比如将FileOutputCommitter缺省实现换为v2版本,废除hftp转由webhdfs替代,移除Hadoop子实现序列化库org.apache.hadoop.Records
(2)Classpath isolation以防止不同版本jar包冲突,比如google Guava在混合使用Hadoop、HBase和Spark时,很容易产生冲突。(https://issues.apache.org/jira/browse/HADOOP-11656)
(3)Shell脚本重构。 Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性,支持动态命令等。https://issues.apache.org/jira/browse/HADOOP-9902
2.2 Hadoop HDFS
(1)HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。(https://issues.apache.org/jira/browse/HDFS-7285)
(2)多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。(https://issues.apache.org/jira/browse/HDFS-6440)
2.3 Hadoop MapReduce
(1)Tasknative优化。为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。(https://issues.apache.org/jira/browse/MAPREDUCE-2841)
(2)MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,涉及到两个参数:mapreduce.{map,reduce}.memory.mb和mapreduce.{map,reduce}.java.opts,一旦设置不合理,则会使得内存资源浪费严重,比如将前者设置为4096MB,但后者却是“-Xmx2g”,则剩余2g实际上无法让java heap使用到。(https://issues.apache.org/jira/browse/MAPREDUCE-5785)
2.4 Hadoop YARN
(1)基于cgroup的内存隔离和IO Disk隔离(https://issues.apache.org/jira/browse/YARN-2619)
(2)用curator实现RM leader选举(https://issues.apache.org/jira/browse/YARN-4438)
(3)containerresizing(https://issues.apache.org/jira/browse/YARN-1197)
(4)Timelineserver next generation (https://issues.apache.org/jira/browse/YARN-2928)
以下是hadoop-3.0的最新参数
hadoop-3.0
HADOOP
Move to JDK8+
Classpath isolation on by default HADOOP-11656
Shell script rewrite HADOOP-9902
Move default ports out of ephemeral range HDFS-9427
HDFS
Removal of hftp in favor of webhdfs HDFS-5570
Support for more than two standby NameNodes HDFS-6440
Support for Erasure Codes in HDFS HDFS-7285
YARN
MAPREDUCE
Derive heap size or mapreduce.*.memory.mb automatically MAPREDUCE-5785
在HDFS-7285中,实现了Erasure Coding这个新功能.鉴于此功能还远没有到发布的阶段,可能后面此块相关的代码还会进行进一步的改造,因此只是做一个所谓的预分析,帮助大家提前了解Hadoop社区目前是如何实现这一功能的.本人之前也没有接触过Erasure Coding技术,中间过程也确实有些偶然,相信本文可以带给大家收获.
Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术.他通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性.在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复.下面结合图片进行简单的演示,首先有原始数据n个,然后加入m个校验数据块.如下图所示:
Parity部分就是校验数据块,我们把一行数据块组成为Stripe条带,每行条带由n个数据块和m个校验块组成.原始数据块和校验数据块都可以通过现有的数据块进行恢复,原则如下:
如果校验数据块发生错误,通过对原始数据块进行编码重新生成如果原始数据块发生错误, 通过校验数据块的解码可以重新生成。
而且m和n的值并不是固定不变的,可以进行相应调整。可能有人会好奇,这其中到底是什么原理呢? 其实道理很简单,你把上面这图看成矩阵,由于矩阵的运算具有可逆性,所以就能使数据进行恢复,给出一张标准的矩阵相乘图,大家可以将二者关联。
3. Hadoop3.0 总结
Hadoop 3.0的alpha版预计2016夏天发布,GA版本11月或12月发布。
Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。


Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性的更多相关文章
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- [转帖]推荐一款比 Find 快 10 倍的搜索工具 FD
推荐一款比 Find 快 10 倍的搜索工具 FD https://www.hi-linux.com/posts/15017.html 试了下 很好用呢. Posted by Mike on 2018 ...
- 比传统事务快10倍?一张图读懂阿里云全局事务服务GTS
近日,阿里云全局事务服务GTS正式上线,为微服务架构中的分布式事务提供一站式解决方案.GTS的原理是将分布式事务与具体业务分离,在平台层面开发通用的事务中间件GTS,由事务中间件协调各服务的调用一致性 ...
- 搜索 比MySQL快10倍?这可能是目前AWS Aurora最详解读!
作者介绍 朱阅岸,中国人民大学博士,现供职于腾讯云数据库团队.研究方向主要为数据库系统理论与实现.新硬件平台下的数据库系统以及TP+AP型混合系统. 编者按 Aurora作为AWS云上的关系数据库 ...
- TDengine能比Hadoop快10倍?
之前对国产的时序大数据存储引擎 TDengine 感兴趣,因为号称比Hadoop快十倍,一直很好奇怎么实现的,所以最近抽空看了下白皮书和设计文档. 如果用一句话总结,就是 TDengine 是为特定的 ...
- Android Studio 2.0 稳定版新特性介绍
Android Studio 2.0 最终迎来了稳定版本号,喜大普奔. 以下这篇文章是2.0新特性的一些简介. 假设想看具体内容请看这里<Android Studio有用指南> 文章转自这 ...
- Kafka 0.11新功能介绍:空消费组延迟rebalance
Kafka 0.11新功能介绍:空消费组延迟rebalance 在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer inst ...
- 超详细 Java 15 新功能介绍
点赞再看,动力无限.微信搜「程序猿阿朗 」,认认真真写文章. 本文 Github.com/niumoo/JavaNotes 和 未读代码博客 已经收录,有很多知识点和系列文章. Java 15 在 2 ...
- Nacos 2.0 正式发布,性能提升 10 倍!!
3月20号,Nacos 2.0.0 正式发布了! Nacos 简介: 一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 通俗点讲,Nacos 就是一把微服务双刃剑:注册中心 + 配置中 ...
随机推荐
- .NET(c#)new关键字的三种用法
前几天去家公司面试,有一道这样的题:写出c#中new关键字的三种用法,思前想后挖空心思也只想出了两种用法,回来查了下msdn,还真是有第三种用法:用于在泛型声明中约束可能用作类型参数的参数的类型,这是 ...
- js中对象判断
1.typeof 形如 var x = "xx"; typeof x == 'string' 返回类型有:'undefined' “string” 'number' 'bool ...
- 线上Linux服务器运维安全策略经验分享
线上Linux服务器运维安全策略经验分享 https://mp.weixin.qq.com/s?__biz=MjM5NTU2MTQwNA==&mid=402022683&idx=1&a ...
- Android EditText 改变边框颜色
第一步:为了更好的比较,准备两个一模一样的EditText(当Activity启动时,焦点会在第一个EditText上,如果你不希望这样只需要写一个高度和宽带为0的EditText即可避免,这里就不这 ...
- eclipse打开jar包出现乱码问题解决方法
今天做项目时候,用eclipse打开.class文件出现乱码问题.jar编码和本地编辑器编码格式不对造成的错误. 首先我们打开eclipse,点击菜单下的window-->preferences ...
- IntelliJ IDEA 修改缓存文件设置
今天在查看C盘,发现虽然我idea安装在了D盘,但是idea的缓存还是在C盘 config 目录是 IntelliJ IDEA 个性化化配置目录,或者说是整个 IDE 设置目录.也是我个人认为最重要的 ...
- 第六篇 SQL Server代理深入作业步骤工作流
本篇文章是SQL Server代理系列的第六篇,详细内容请参考原文. 正如这一系列的前几篇所述,SQL Server代理作业是由一系列的作业步骤组成,每个步骤由一个独立的类型去执行.每个作业步骤在技术 ...
- 用UIImageView作出动画效果
#import "AppDelegate.h" @interface AppDelegate () @end @implementation AppDelegate - (BOOL ...
- Java Socket常见异常处理 和 网络编程需要注意的问题
在java网络编程Socket通信中,通常会遇到以下异常情况: 第1个异常是 java.net.BindException:Address already in use: JVM_Bind. 该异常发 ...
- Java数据库操作大全
1.提取单条记录 //import java.sql.*; Connection con=null; Statement stmt=null; ResultSet %%6=null; try { Cl ...