selenium-webdriver循环点击百度搜索结果以及获取新页面的handler
webdriver还是很有意思的,之前用过Ruby的watir的自动化测试框架,感觉selenium的这套框架更好一些,很容易就可以上手。我虽然不做自动化这块,不过先玩玩再说,多学点东西总之还是好一些的。
# coding:utf-
import time
from selenium import webdriver
import unittest
from pythontest.commlib.baselib import * #引用封装后的日志系统
log = TestLog().getlog()
class BaiBu(unittest.TestCase):
u'''【百度.类】'''
def setUp(self):
self.browser = webdriver.Firefox()
self.browser.get("http://www.baidu.com")
self.browser.implicitly_wait()
#self.base = Screen(self.browser) def tearDown(self):
self.browser.quit() def test_search(self):
log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码
#输入关键字,关键字任意
self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司")
self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值
#点击搜索结果
self.browser.find_element_by_xpath(".//*[@id='2']/h3/a").click() #根据xpath识别元素
time.sleep()
log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-
self.assertIn("软件测试",self.browser.title.encode("utf-8")) #断言,转码
time.sleep()
'''接下来的工作,是获取新页面的handler,以及循环点击搜索结果''' if __name__ == "__main__":
unittest.main()
明天有时间再优化,根据id进行随机数选取。可以参考我之前Ruby的一个自动化测试框架:http://www.cnblogs.com/zhuque/archive/2012/11/30/2796866.html
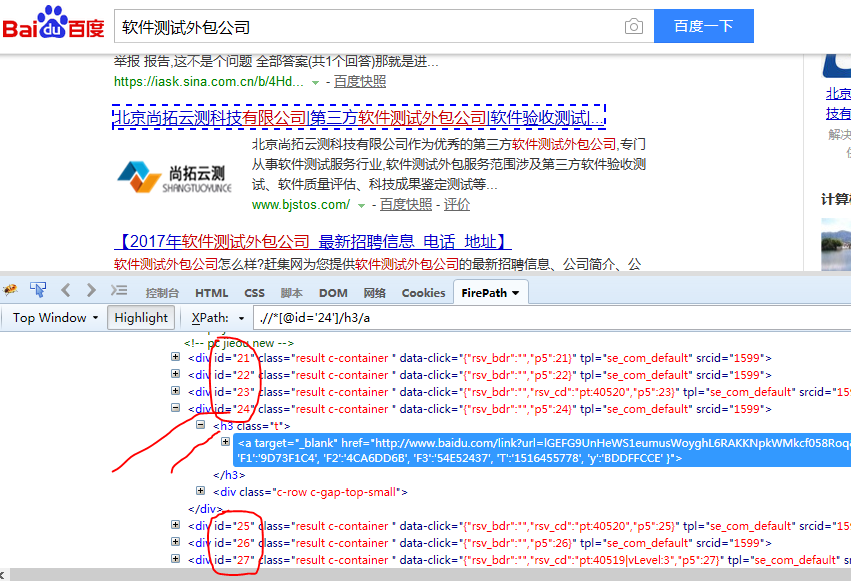
优化: 1、导入random模块,随机打开页面搜索结果;
2、获取新打开页面的页面句柄,并建立新结果页的断言
3、建立while循环,每次打开新页面前,重新获取原来结果页面的句柄
# coding:utf-
import time
from selenium import webdriver
import unittest
from pythontest.commlib.baselib import *
import random #引用封装后的日志系统
log = TestLog().getlog()
class BaiBu(unittest.TestCase):
u'''【百度.类】'''
def setUp(self):
self.browser = webdriver.Firefox()
self.browser.get("http://www.baidu.com")
self.browser.implicitly_wait()
#self.base = Screen(self.browser) def tearDown(self):
# self.browser.quit()
pass def test_search(self):
u'''接下来的工作,是获取新页面的handler,以及循环点击搜索结果'''
log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码
#输入关键字,关键字任意
self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司")
self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值
i =
while i < : #打开两次搜索结果
randid = random.randint(,) #根据搜索结果页id属性,随机打开搜索结果
#点击搜索结果
self.browser.switch_to.window(self.browser.window_handles[]) #获取搜索结果页的页面句柄
print( ".//*[@id='%s']/h3/a"%(randid) ) #对print()进行格式化输出,%(randid)
self.browser.find_element_by_xpath( ".//*[@id='%s']/h3/a"%(randid) ).click() #根据xpath识别元素
time.sleep()
self.browser.switch_to.window(self.browser.window_handles[-]) #获取新打开结果页的页面句柄
log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-
self.assertIn("尚拓云测",self.browser.title.encode("utf-8")) #断言,转码
i = i +
time.sleep() if __name__ == "__main__":
unittest.main()
测试结果如下:

selenium-webdriver循环点击百度搜索结果以及获取新页面的handler的更多相关文章
- selenium 之百度搜索,结果列表翻页查询
selenium之百度搜索,结果列表翻页查询 by:授客 QQ:1033553122 实例:百度搜索,结果列表翻页查询 解决问题:解决selenium driver获取web页面元素时,元素过期问题 ...
- selenium,webdriver模仿浏览器访问百度 基础2
学python理念 : 代码要多敲 一定要多敲 哪怕很基础 注释要清晰 由于基础1有一些注释写的很详细, 在这里有些注释没有写的很详细 可以配合基础1一起学习哦 from selenium im ...
- python + selenium登陆并点击百度平台
from PIL import Imagefrom selenium.webdriver import DesiredCapabilitiesfrom selenium import webdrive ...
- selenium,webdriver模仿浏览器访问百度 基础1
这是一种比较好的反反爬技术 #安装:pip install selenium=2.48.0 #显示:pip show selenium #卸载:pip uninstall selenium #模拟用户 ...
- 转载 基于Selenium WebDriver的Web应用自动化测试
转载原地址: https://www.ibm.com/developerworks/cn/web/1306_chenlei_webdriver/ 对于 Web 应用,软件测试人员在日常的测试工作中, ...
- python--selenium简单模拟百度搜索点击器
python--selenium简单模拟百度搜索点击器 发布时间:2018-02-28 来源:网络 上传者:用户 关键字: selenium 模拟 简单 点击 搜索 百度 发表文章摘要:用途:简单模拟 ...
- C#+Selenium抓取百度搜索结果前100网址
需求 爬取百度搜索某个关键字对应的前一百个网址. 实现方式 VS2017 + Chrome .NET Framework + C# + Selenium(浏览器自动化测试框架) 环境准备 创建控制台应 ...
- (java)selenium webdriver学习--通过id、name定位,输入内容,搜索,关闭操作、通过tagname查找元素
selenium webdriver学习--通过id.name定位,输入内容,搜索,关闭操作:通过tagname查找元素 打开谷歌浏览器,输入不同的网站,搜索框的定位含有不同元素(有时为id,有时为n ...
- 使用python和selenium写一个百度搜索的case
今天练习的内容主要写了一个小功能,在百度上搜索某词汇,然后实现web上的back功能 代码如下: import unittest from selenium import webdriver from ...
随机推荐
- IDEA编译器的常用快捷键
今天想简单分享一下IDEA编译器的常用快捷键 1. -----------自动代码-------- 常用的有fori/sout/psvm+Tab即可生成循环.System.out.main方法等boi ...
- Appium 客户端类库
Appium 支持以下语言的客户端类库: 语言 Ruby Python Java JavaScript PHP C# Objective-C 锁定注意,一些方法类似 endTestCoverage() ...
- java订单金额分级计算
package ord; import java.util.ArrayList; public class order { public String orderid; public user use ...
- Adding appsettings.json to a .NET Core console app
This is something that strangely doesn’t seem to be that well documented and took me a while to figu ...
- [题解]小X的液体混合
版权说明:来自 石门ss学校 Guohao OJ ,禁止转载 题目描述 虽然小X不喜欢化学原理,但他特别喜欢把一大堆液体倒在一起. 现在小X有n种液体,其中m对会发生反应.现在他想把这n种液体按某种顺 ...
- nginx springboot配置
1.下载安装nginx 2.nginx.conf文件修改参数 上方是代理后的端口,代理的server.下方是需要代理的路径 3.windows 下操作指令 启动 直接点击Nginx目录下的nginx. ...
- 使用Python操作MongoDB
MongoDB简介(摘自:http://www.runoob.com/mongodb/mongodb-intro.html) MongoDB 由C++语言编写,是一个基于分布式文件存储的开源数据库系统 ...
- 【LUOGU???】WD与地图 整体二分 线段树合并
题目大意 有一个简单有向图.每个点有点权. 有三种操作: 修改点权 删除一条边 询问和某个点在同一个强连通分量中的点的前 \(k\) 大点权和. \(n\leq 100000,m,q\leq 2000 ...
- 超越村后端开发(3:安装djangorestframework+序列化+API开发前期准备)
1.安装djangorestframework 1.安装djangorestframework及其依赖包markdown.django-filter. pip install djangorestfr ...
- iOS开发,这样写简历才能让大厂面试官看重你!
前言: 对于职场来说,简历就如同门面.若是没想好,出了差错,耽误些时日倒不打紧,便是这简历入不了HR的眼,费力伤神还不能觅得好去处,这数年来勤学苦练的大好光阴,岂不辜负? 简历,简而有力.是对一个人工 ...