selenium-webdriver循环点击百度搜索结果以及获取新页面的handler
webdriver还是很有意思的,之前用过Ruby的watir的自动化测试框架,感觉selenium的这套框架更好一些,很容易就可以上手。我虽然不做自动化这块,不过先玩玩再说,多学点东西总之还是好一些的。
# coding:utf-
import time
from selenium import webdriver
import unittest
from pythontest.commlib.baselib import * #引用封装后的日志系统
log = TestLog().getlog()
class BaiBu(unittest.TestCase):
u'''【百度.类】'''
def setUp(self):
self.browser = webdriver.Firefox()
self.browser.get("http://www.baidu.com")
self.browser.implicitly_wait()
#self.base = Screen(self.browser) def tearDown(self):
self.browser.quit() def test_search(self):
log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码
#输入关键字,关键字任意
self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司")
self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值
#点击搜索结果
self.browser.find_element_by_xpath(".//*[@id='2']/h3/a").click() #根据xpath识别元素
time.sleep()
log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-
self.assertIn("软件测试",self.browser.title.encode("utf-8")) #断言,转码
time.sleep()
'''接下来的工作,是获取新页面的handler,以及循环点击搜索结果''' if __name__ == "__main__":
unittest.main()
明天有时间再优化,根据id进行随机数选取。可以参考我之前Ruby的一个自动化测试框架:http://www.cnblogs.com/zhuque/archive/2012/11/30/2796866.html
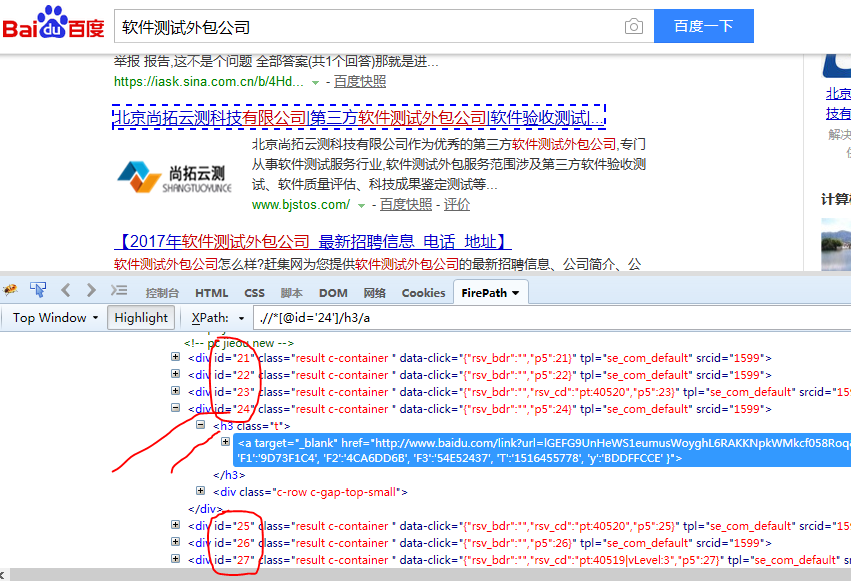
优化: 1、导入random模块,随机打开页面搜索结果;
2、获取新打开页面的页面句柄,并建立新结果页的断言
3、建立while循环,每次打开新页面前,重新获取原来结果页面的句柄
# coding:utf-
import time
from selenium import webdriver
import unittest
from pythontest.commlib.baselib import *
import random #引用封装后的日志系统
log = TestLog().getlog()
class BaiBu(unittest.TestCase):
u'''【百度.类】'''
def setUp(self):
self.browser = webdriver.Firefox()
self.browser.get("http://www.baidu.com")
self.browser.implicitly_wait()
#self.base = Screen(self.browser) def tearDown(self):
# self.browser.quit()
pass def test_search(self):
u'''接下来的工作,是获取新页面的handler,以及循环点击搜索结果'''
log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码
#输入关键字,关键字任意
self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司")
self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值
i =
while i < : #打开两次搜索结果
randid = random.randint(,) #根据搜索结果页id属性,随机打开搜索结果
#点击搜索结果
self.browser.switch_to.window(self.browser.window_handles[]) #获取搜索结果页的页面句柄
print( ".//*[@id='%s']/h3/a"%(randid) ) #对print()进行格式化输出,%(randid)
self.browser.find_element_by_xpath( ".//*[@id='%s']/h3/a"%(randid) ).click() #根据xpath识别元素
time.sleep()
self.browser.switch_to.window(self.browser.window_handles[-]) #获取新打开结果页的页面句柄
log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-
self.assertIn("尚拓云测",self.browser.title.encode("utf-8")) #断言,转码
i = i +
time.sleep() if __name__ == "__main__":
unittest.main()
测试结果如下:

selenium-webdriver循环点击百度搜索结果以及获取新页面的handler的更多相关文章
- selenium 之百度搜索,结果列表翻页查询
selenium之百度搜索,结果列表翻页查询 by:授客 QQ:1033553122 实例:百度搜索,结果列表翻页查询 解决问题:解决selenium driver获取web页面元素时,元素过期问题 ...
- selenium,webdriver模仿浏览器访问百度 基础2
学python理念 : 代码要多敲 一定要多敲 哪怕很基础 注释要清晰 由于基础1有一些注释写的很详细, 在这里有些注释没有写的很详细 可以配合基础1一起学习哦 from selenium im ...
- python + selenium登陆并点击百度平台
from PIL import Imagefrom selenium.webdriver import DesiredCapabilitiesfrom selenium import webdrive ...
- selenium,webdriver模仿浏览器访问百度 基础1
这是一种比较好的反反爬技术 #安装:pip install selenium=2.48.0 #显示:pip show selenium #卸载:pip uninstall selenium #模拟用户 ...
- 转载 基于Selenium WebDriver的Web应用自动化测试
转载原地址: https://www.ibm.com/developerworks/cn/web/1306_chenlei_webdriver/ 对于 Web 应用,软件测试人员在日常的测试工作中, ...
- python--selenium简单模拟百度搜索点击器
python--selenium简单模拟百度搜索点击器 发布时间:2018-02-28 来源:网络 上传者:用户 关键字: selenium 模拟 简单 点击 搜索 百度 发表文章摘要:用途:简单模拟 ...
- C#+Selenium抓取百度搜索结果前100网址
需求 爬取百度搜索某个关键字对应的前一百个网址. 实现方式 VS2017 + Chrome .NET Framework + C# + Selenium(浏览器自动化测试框架) 环境准备 创建控制台应 ...
- (java)selenium webdriver学习--通过id、name定位,输入内容,搜索,关闭操作、通过tagname查找元素
selenium webdriver学习--通过id.name定位,输入内容,搜索,关闭操作:通过tagname查找元素 打开谷歌浏览器,输入不同的网站,搜索框的定位含有不同元素(有时为id,有时为n ...
- 使用python和selenium写一个百度搜索的case
今天练习的内容主要写了一个小功能,在百度上搜索某词汇,然后实现web上的back功能 代码如下: import unittest from selenium import webdriver from ...
随机推荐
- openstack安装过程报错
问题一 .执行启动neutron服务报错[root@localhost ~]# systemctl start neutron-server.service Job for neutron-serve ...
- 在JavaScript中使用三目运算符时进行多个操作
今天使用三目运算符时,刚好需要在false时进行两个操作,故测试并记录在三目运算符中使用多个操作的方式 例子如下: true ? (console.log(1),console.log(2), tes ...
- 使用栈实现队列(2)(Java)
class MyQueue { private Stack s1; private Stack s2; public MyQueue(int size) { this.s1 = new Stack(s ...
- [转帖]Windows7/2008中批量删除隧道适配器的方法
https://www.jb51.net/os/windows/479838.html 客户现场的硬件信息总是发生变化 这里查找一下资料 尝试一下. 1.在网卡属性的“网络”中,将“Internet协 ...
- MyBatis 3
MyBatis 3 学习笔记 一.Mybatis 基础知识 1.MyBatis 3编写步骤: 根据mybatis-config.xml配置文件创建一个SqlSessionFactory对象. sql映 ...
- 【MySQL 读书笔记】RR(REPEATABLE-READ)事务隔离详解
这篇我觉得有点难度,我会更慢的更详细的分析一些 case . MySQL 的默认事务隔离级别和其他几个主流数据库隔离级别不同,他的事务隔离级别是 RR(REPEATABLE-READ) 其他的主流数据 ...
- easyui判断下拉列表
{field:'state',title:'状态',width:100, formatter : function(value, row, index){ if (value == 0) { retu ...
- JavaScript判断是否为微信浏览器或支付宝浏览器
可以用手机安装的微信和支付宝扫描下方二维码测试 <!DOCTYPE html> <html lang="en"> <head> <meta ...
- hdu-4612(无向图缩点+树的直径)
题意:给你n个点和m条边的无向图,问你如果多加一条边的话,那么这个图最少的桥是什么 解题思路:无向图缩点和树的直径,用并查集缩点: #include<iostream> #include& ...
- CF802C Heidi and Library (hard)
题目描述 你有一个容量为k的空书架,现在共有n个请求,每个请求给定一本书ai,如果你的书架里没有这本书,你就必须以ci的价格购买这本书放入书架.当然,你可以在任何时候丢掉书架里的某本书.请求出完成这n ...