pythonのdjango select_related 和 prefetch_related()
在数据库有外键的时候,使用select_related() 和 prefetch_related() 可以很好的减少数据库请求次数,从而提高性能。
(1)select_related()当执行它的查询时它沿着外键关系查询关联的对象数据。它会生成一个复杂的查询并引起性能的消耗,但是在以后使用外键关系时将不需要数据库查询。
(2)prefetch_related()返回的也是QuerySet,它将在单个批处理中自动检索每个指定查找的对象。这具有与select_related类似的目的,两者都被设计为阻止由访问相关对象而导致的数据库查询的泛滥,但是策略是完全不同的。
(3)select_related通过创建SQL连接并在SELECT语句中包括相关对象的字段来工作。因此,select_related在同一数据库查询中获取相关对象。然而,为了避免由于跨越“多个'关系而导致的大得多的结果集,select_related限于单值关系 -外键和一对一关系。
(4)prefetch_related,另一方面,为每个关系单独查找,并在Python中“加入”。这允许它预取多对多和多对一对象,除了外键和一对一关系,它们不能使用select_related来完成。
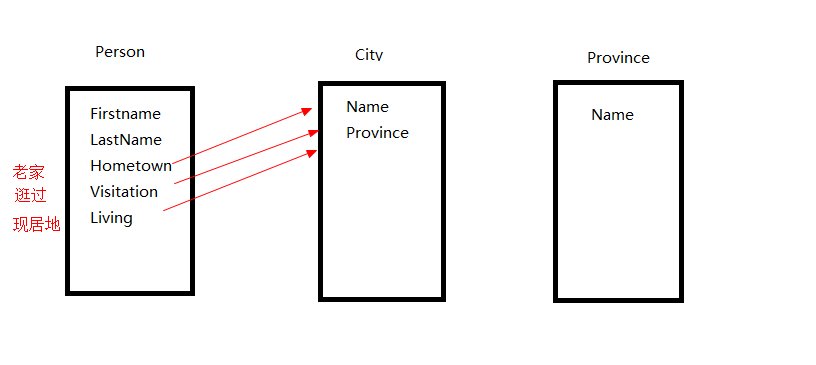
依据图示,编写model代码,model.py代码如下:
from django.db import models # Create your models here. class Province(models.Model):
name = models.CharField(max_length=10)
def __str__(self):
return self.name class City(models.Model):
name = models.CharField(max_length=5)
province = models.ForeignKey(Province,on_delete=True,null=True)
def __str__(self):
return self.name class Person(models.Model):
firstname = models.CharField(max_length=10)
lastname = models.CharField(max_length=10)
visitation = models.ManyToManyField(City,related_name="visitor") # visitation字段与city表时多对多关系
hometown = models.ForeignKey(City,related_name="birth",on_delete=True,null=True) # related_name 是直接给外键起好名字
living = models.ForeignKey(City,related_name="citizen",on_delete=True,null=True)
def __str__(self):
return self.firstname + self.lastname
app名称为stark,我们在province中添加如下数据:
INSERT INTO `modeltest`.`stark_province` (`id`, `name`) VALUES ('', '北京');
INSERT INTO `modeltest`.`stark_province` (`id`, `name`) VALUES ('', '河南');
在city中添加如下数据:
INSERT INTO `modeltest`.`stark_city` (`id`, `name`, `province_id`) VALUES ('', '昌平', '');
INSERT INTO `modeltest`.`stark_city` (`id`, `name`, `province_id`) VALUES ('', '海淀', '');
INSERT INTO `modeltest`.`stark_city` (`id`, `name`, `province_id`) VALUES ('', '郑州', '');
INSERT INTO `modeltest`.`stark_city` (`id`, `name`, `province_id`) VALUES ('', '焦作', '');
select_related()
文章解释:https://www.cnblogs.com/tuifeideyouran/p/4232028.html
对于一对一字段(OneToOneField)和外键字段(ForeignKey),可以使用select_related()来对QuerySet进行优化.
在对QuerySet使用select_related()函数后,Django会获取相应外键对应的对象,从而在之后需要的时候不必再查询数据库了。
But我实际应用时:
并没有发现什么好处
不用select_related()情况的一个例子:
obj1 = models.City.objects.all()
for c in obj1:
print(c.province)
这样会导致线性的SQL查询,SQL查询语句如下:
(0.001) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None
(0.000) SELECT `stark_city`.`id`, `stark_city`.`name`, `stark_city`.`province_id` FROM `stark_city`; args=()
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 1; args=(1,)
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 1; args=(1,)
(0.000) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 2; args=(2,)
用select_related()的例子:
obj2 = models.City.objects.select_related().all()
for c1 in obj2:
print(c1.province)
控制台打印结果如下:
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 2; args=(2,)
(0.001) SELECT `stark_city`.`id`, `stark_city`.`name`, `stark_city`.`province_id` FROM `stark_city`; args=()
(0.000) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 1; args=(1,)
(0.000) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 1; args=(1,)
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 2; args=(2,)
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` = 2; args=(2,)
北京
北京
河南
河南
经过对比SQL,几乎呈现一直状态,并未实现我参考的文章中所出现的:

感受不到这种优越感~~~~~
select_related() 接受可变长参数,每个参数是需要获取的外键(父表的内容)的字段名,以及外键的外键的字段名、外键的外键的外键…。若要选择外键的外键需要使用两个下划线“__”来连接。
例如获得张三的现居省份
print("------------------------")
zhangs = models.Person.objects.select_related("hometown__province","living__province").get(firstname="张",lastname="三")
print(zhangs)
控制台数据SQL如下:
(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None
(0.003) SELECT `stark_person`.`id`, `stark_person`.`firstname`, `stark_person`.`lastname`,
`stark_person`.`hometown_id`, `stark_person`.`living_id`, `stark_city`.`id`, `stark_city`.`name`,
`stark_city`.`province_id`, `stark_province`.`id`, `stark_province`.`name`, T4.`id`, T4.`name`,
T4.`province_id`, T5.`id`, T5.`name` FROM `stark_person` LEFT OUTER JOIN `stark_city` ON
(`stark_person`.`hometown_id` = `stark_city`.`id`) LEFT OUTER JOIN `stark_province` ON
(`stark_city`.`province_id` = `stark_province`.`id`) LEFT OUTER JOIN `stark_city` T4 ON
(`stark_person`.`living_id` = T4.`id`) LEFT OUTER JOIN `stark_province` T5 ON
(T4.`province_id` = T5.`id`) WHERE (`stark_person`.`firstname` = '张' AND `stark_person`.`lastname` = '三'); args=('张', '三')
[08/Jan/2019 14:36:03] "GET /index/ HTTP/1.1" 200 2
张三
另外,django1.7以后两个外键同时关联使用时可以采用以下方法:
print("------------------------")
zhangs = models.Person.objects.select_related("living__province").select_related("hometown__province").get(firstname="张",lastname="三")
print(zhangs)
return HttpResponse("ok")
django使用了三次LEFT OUTER JOIN来完成请求。而之前这边使用的INNER JOIN 来完成请求,两种关联查询区别在于:
-------------------------------------------------------------------额外知识点SQL-------------------------------------------------------------------
Table A 是左边的表。Table B 是右边的表。
1.INNER JOIN 产生的结果是AB的交集
SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name
INNER JOIN 产生的结果是AB的交集 INNER JOIN 产生的结果是AB的交集
2.LEFT [OUTER] JOIN 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name
LEFT [OUTER] JOIN 产生表A的完全集,而B表中匹配的则有值 LEFT [OUTER] JOIN 产生表A的完全集,而B表中匹配的则有值
3.RIGHT [OUTER] JOIN 产生表B的完全集,而A表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM TableA RIGHT OUTER JOIN TableB ON TableA.name = TableB.name
与left join类似。
4.FULL [OUTER] JOIN 产生A和B的并集。对于没有匹配的记录,则会以null做为值。
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
你可以通过is NULL将没有匹配的值找出来:
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
WHERE TableA.id IS null OR TableB.id IS null
FULL [OUTER] JOIN 产生A和B的并集 FULL [OUTER] JOIN 产生A和B的并集
5. CROSS JOIN 把表A和表B的数据进行一个N*M的组合,即笛卡尔积。如本例会产生4*4=16条记录,在开发过程中我们肯定是要过滤数据,所以这种很少用。
SELECT * FROM TableA CROSS JOIN TableB
相信大家对inner join、outer join和cross join的区别一目了然了。
-------------------------------------------------------------------end-------------------------------------------------------------------
由于我不知道django的那个版本开始改的,所以,我只能给大家说,这样改完后,我们需要注意的是数据结果的变化。从以前的交集查询变成了现在的左连接查询,只有左表存在方存在数据。
总结:
1.select_related主要针一对一和多对一关系进行优化。
2.select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
3.可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
4.也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
5.也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
6.Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个。
prefetch_related()
对于多对多字段(ManyToManyField)和一对多(ForeignKey)字段,可以使用prefetch_related()来进行优化.
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者 是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL 语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。
如果我们要获得张三所有去过的城市.
zhangs = models.Person.objects.prefetch_related("visitation").get(firstname="张",lastname="三")
for city in zhangs.visitation.all():
print(city)
控制台输出如下:
------------------------
(0.001) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None
(0.002) SELECT `stark_person`.`id`, `stark_person`.`firstname`, `stark_person`.`lastname`, `stark_person`.`hometown_id`,
`stark_person`.`living_id`
FROM `stark_person`
WHERE (`stark_person`.`firstname` = '张' AND `stark_person`.`lastname` = '三'); args=('张', '三')
昌平
海淀
郑州
(0.001) SELECT (`stark_person_visitation`.`person_id`) AS `_prefetch_related_val_person_id`, `stark_city`.`id`,
`stark_city`.`name`, `stark_city`.`province_id`
FROM `stark_city`
INNER JOIN `stark_person_visitation` ON (`stark_city`.`id` = `stark_person_visitation`.`city_id`)
WHERE `stark_person_visitation`.`person_id` IN (1); args=(1,)
[08/Jan/2019 15:55:03] "GET /index/ HTTP/1.1" 200 2
第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`stark_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表.
或者我们要获得河南的所有城市名
hn = models.Province.objects.prefetch_related("city_set").get(name__iexact='河南')
for city in hn.city_set.all():
print(city.name)
控制台输出SQL语句如下:
------------------------
(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None
(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`name` LIKE '河南'; args=('河南',)
郑州
(0.001) SELECT `stark_city`.`id`, `stark_city`.`name`, `stark_city`.`province_id`
FROM `stark_city` WHERE `stark_city`.`province_id` IN (2); args=(2,)
焦作
[08/Jan/2019 16:04:50] "GET /index/ HTTP/1.1" 200 2
例如要获得所有姓王的人去过的省:
wangs = models.Person.objects.prefetch_related("visitation__province").filter(firstname__iexact='王')
for i in wangs :
print(i)
for city in i.visitation.all():
print(city.province.name)
控制台SQL代码如下:
*************************
(0.001) SELECT `stark_person`.`id`, `stark_person`.`firstname`, `stark_person`.`lastname`, `stark_person`.`hometown_id`, `stark_person`.`living_id` FROM `stark_person` WHERE `stark_person`.`firstname` LIKE '王'; args=('王',)
(0.001) SELECT (`stark_person_visitation`.`person_id`) AS `_prefetch_related_val_person_id`, `stark_city`.`id`, `stark_city`.`name`, `stark_city`.`province_id` FROM `stark_city` INNER JOIN `stark_person_visitation` ON (`stark_city`.`id` = `stark_person_visitation`.`city_id`) WHERE `stark_person_visitation`.`person_id` IN (2); args=(2,)
(0.001) SELECT `stark_province`.`id`, `stark_province`.`name` FROM `stark_province` WHERE `stark_province`.`id` IN (1, 2); args=(1, 2)
[08/Jan/2019 17:06:03] "GET /index/ HTTP/1.1" 200 2
Person object (2)
北京
河南
河南
要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导 致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变 SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
None
可以通过传入一个None来清空之前的prefetch_related。就像这样:
prefetch_cleared_qset = zhangs.prefetch_related(None)
select_related()的效率要高于prefetch_related()。因此,最好在能用select_related()的地方尽量使用它,也就是说,对于ForeignKey字段,避免使用prefetch_related()。
django使用了两次INNER JOIN来完成请求,但是未指定的外键则不会被添加到结果中,例如张三的故乡.
pythonのdjango select_related 和 prefetch_related()的更多相关文章
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(三)
4.一些实例 如果我们想要获得所有家乡是湖北的人,最无脑的做法是先获得湖北省,再获得湖北的所有城市,最后获得故乡是这个城市的人.就像这样: 1 2 3 4 5 >>> hb = Pr ...
- Django框架详细介绍---ORM相关操作---select_related和prefetch_related函数对 QuerySet 查询的优化
Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化 引言 在数据库存在外键的其情况下,使用select_related()和pre ...
- Django的select_related 和 prefetch_related 函数优化查询
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用.虽然Q ...
- 转载 :实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(一)
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用.虽然Q ...
- Django中的select_related与prefetch_related
Django是一个基于Python的网站开发框架,一个很重要的特点就是Battery Included,简单来说就是包含了常规开发中所需要的一切东西,包括但不限于完整的ORM模型.中间件.会话处理 ...
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化
引言 在数据库存在外键的其情况下,使用select_related()和prefetch_related()很大程度上减少对数据库的请求次数以提高性能 1.实例准备 模型: from django.d ...
- 转 实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(三)
这是本系列的最后一篇,主要是select_related() 和 prefetch_related() 的最佳实践. 第一篇在这里 讲例子和select_related() 第二篇在这里 讲prefe ...
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(一)
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用.虽然Q ...
- 详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用. 1. ...
随机推荐
- SkiaSharp图像处理
SkiaSharp图像处理 .NET Core使用skiasharp文字头像生成方案(基于docker发布) 一.问题背景 目前.NET Core下面针对于图像处理的库微软并没有集成,在.NET ...
- FreeMarker 入门
目录 FreeMarker是什么 为什么要学习FreeMarker FreeMarker相关站点
- Spring boot的第一个demo
由于SpringBoot的问世使开发的门槛有降低了不少,就其这一点,早已使其名声大振,如雷贯耳.我之前是使用spring开发的,刚才使用了spring boot试验了一下,果然名不虚传,开发速度贼快. ...
- DAY30、网络编程
一.网络编程 软件开发 c/s架构 c:客户端 s:服务端 b/s架构 b:浏览器 s:服务端 本质:b/s其实也是c/s 服务端:24小时不间断提供服务,谁来救服务谁 客户端:想什么时候体验服务,就 ...
- js 实现数据结构 -- 字典
原文: 在Javascript 中学习数据结构与算法. 概念: 集合.字典.散列表都可以存储不重复的数据.字典和我们上面实现的集合很像. 当然,字典中的数据具有不重复的特性.js 中 Object 的 ...
- python format() 函数
转载 https://www.cnblogs.com/wushuaishuai/p/7687728.html 正文 Python2.6 开始,新增了一种格式化字符串的函数 format() ,它增强了 ...
- 仿照selalchemy实现简单的mongo查询
首先这是一个很奇葩的需求,时间紧迫顺手胡写了一个,以后看看有没有好的思路 def and_(item_list): return "%s:[%s]" % ("$and&q ...
- laravel 配置MySQL读写分离
前言:说到应对大流量.高并发的解决方案的时候,总会有这样的回答,如:读写分离,主从复制...等,数据库层今天先不讨论,那么今天我们就来看看怎么在应用层实现读写分离. 框架:laravel5.7(所有配 ...
- @Controller @RestController
知识点:@RestController注解相当于@ResponseBody + @Controller合在一起的作用. 1) 如果只是使用@RestController注解Controller,则Co ...
- CSS上下左右居中的几种方法
1.absolute,margin: auto .container { position: relative; } .content { position: absolute; margin: au ...