ArcGis——好好的属性表,咋就乱码了呢?
我就瞎说一下,反正你也不懂。
——见到许多ArcGis属性表乱码的问题,也见过各种哭笑不得的解说
目录
第一节 字符编码那些事儿
计算机以二进制的形式存储信息。每个“字”都会用特定的一组代码(1-4个不等的字节,1个字节=8个二进制位)表示,也就是编个号,这种表示规则叫做“字符编码”。计算机会根据二进制的“编号”信息去“编号规则(字符编码)”对应的“字符集”查找其所对应的“字”,使用对应的字体(字符集对应若干“字体库”)显示出来。从别处拷贝或者网络来一个文件,系统环境或者编码规则没选对,那就乱了呗。
ASCII
话说当年,美国佬最早发明了“字符编码”这种东西,起名叫ASCII(American standard Code for information Interchange)。它包含了128个字符(0-127),每个字符用8个二进制位表示,第1位规定为0,后7位标识一个字符。比如‘A’表示为二进制是01000001,十进制是65,十六进制是0x41,这也就是我们常说的一个英文字母占1个字节,8bit=1Byte。
美国佬觉得一个字节(可以表示256个十进制编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前128个编码)。后来,欧洲国家不干了,他们发现ASCII并不能标识他们的字母,于是ASCII中127号之后的空位被用来表示这些字符,128-255这一页字符集被称为扩展字符集。为啥是-255?8个二进制位表示十进制数最大也就是255。
这就够了?差的远呢!
GB2312
后来,中国也用上计算机了,日本、韩国……一众国家也用上了,这回事儿大了,这么些文字怎么表示?
字符编码方案GB2312就这样出来了,它相当于对ASCII的扩展。该编码方案中,小于等于127的继续使用原ASCII编码,用2个大于127的字节表示一个中文字符,前面的一个字节(称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样就一组就给大约7000多个简体汉字编码了。在这些编码中,数学符号,希腊的字母,日文的假名都编进去了,连ASCII里本来就有的数字,标点,字母都统统重新编了两个字节长的编码,这就是常说的“全角”符号,原有的127号以前的那些字符称为“半角”符号。
当然,日本、韩国等的一众国家也整出了自己的双字节字符编码方案。
GBK
再后来……这点中文还是不够用啊!生僻字和繁体字等还是无法识别怎么办?于是改了编码规则:要求高字节(第一个字节)大于127的就认为是2字节的中文字符(低字节(第二个字节)那里0-127也用上了),这样拓展之后就是GBK标准。GBK收录了2万多汉字及符号,因其最早被WINDOWS采用,所以其应用范围非常广。但后来少数民族同胞也要用计算机,于是为了扩展少数民族字符,GBK被扩展为GB18030。
中国GBK、日本Shift_JIS、韩国EUC-KR……这些编码规则都使用了ANSI标准,这里面存在一个bug。都是双字节表示一个文字,那中文到韩文系统下会发生什么情况?乱码!你猜对了。
UTF-8
上面太乱了,ISO(国际标准化组织)决定制定一个统一的包括全世界所有字符的编码标准,包括字符集、编码方案等,叫做"Universal Multiple-Octet Coded Chracter Set",简称UCS,俗称Unicode标准(注意想想ANSI标准,它俩都不是具体的字符编码规则),“万国码”出来了,看你还怎么乱。
作为Unicode字符集的一种编码方式,UTF-8采用变长编码,使用1-4个字节表示一个字符,其特点是,对不同范围的字符使用不同长度的编码。这样,UTF-8中那些半角字符就用1个字节(8个二进制位)表示,而中文使用3个字节表示。
第二节 都是编码惹的祸
编码说,这个锅它不想背。
前面说了windows系统默认使用ANSI编码标准,中文系统下是GBK,10.2之前的ArcGis也默认这个“默认”给dbf编码,所以2个字节表示一个汉字,所以一个字段名最多(11字节)5个汉字。
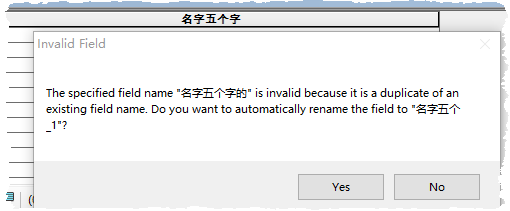
而自10.2.1之后,Esri潮了一把,dbf编码用了UTF-8,这样一个字段名也就只能写3个汉字了,因为11mod3=2。
这样一来,导出新的文件由gbk→UTF8就导致字段名字符截断的问题。
从别处拷贝或者网络来一个Shapefile文件,系统环境或者编码规则没选对,那就乱了呗。
第三节 dbf犯的错
在ArcGIS Desktop 创建 shapefile 文件,其头文件(dBase Header)中,一般会包含shapefile使用的编码类型的信息,即 LDID ( Language Driver ID),它告诉应用程序用何种编码类型去正确读取它。一般,在Shapefile的子文件中有同名 *.cpg 文件,也存储了编码信息,用记事本打开,可看到如UTF-8、GBK。二者都标识了dbf的编码方式,被ArcGIS 识别的优先顺序是,LDID 优先于 CPG文件。
修改默认Codepage,可以改变ArcGis创建新Shapefile文件时dbf的编码格式。注意!这里划重点,改了这里只是以后创建新的采用何种编码方式,并不会改变已有dbf文件的编码方式,也就解决不了它的乱码!
ArcMap读取dbf属性表乱码
由于Shapefile是开放数据格式,所以有可能在使用第三方工具创建或者其他一些情况中,忽略了 Language Driver ID的声明,会导致读取乱码,这时,尝试添加同名文件 *.cpg 。
ArcGis属性表导出Excel乱码
移步ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
参考:
ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
十分钟搞清字符集和字符编码
GB2312 80信息交换用汉字编码字符集 基本集
ArcGis——好好的属性表,咋就乱码了呢?的更多相关文章
- ArcGIS学习记录—属性表的编辑与修改
原文地址: ArcGIS问题:属性表的编辑与修改 - Silent Dawn的日志 - 网易博客 http://gisman.blog.163.com/blog/static/344933882009 ...
- ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
2019年4月 拓展: ArcGis——好好的属性表,咋就乱码了呢? 2019年3月27日补充: 在ArcMap10.3+(根据官网描述应该是,作者测试使用10.5,可行)以后的版本,可以使用ArcT ...
- ArcGis dbf读写——挂接Excel到属性表 C#
ArcMap提供了挂接Excel表格信息到属性表的功能,但是当数据量较大到以万计甚至十万计的时候这个功能就歇菜了,当然,你可以考虑分段挂接.这个挂接功能只是做了一个表关联,属性记录每个字段的信息需要通 ...
- 解决ArcGIS10.3属性表中文乱码问题
问题描述:在10.3刚出为不久,就发现有时属性表会出现中文乱码的问题. 解决方法:在Cmd命令行中输入以下命令: reg add HKEY_CURRENT_USER\Software\ESRI\Des ...
- ArcGIS10.3_解决属性表中文乱码问题
借鉴前辈们解决ArcMap低版本属性表乱码的问题解决方法,勇敢的尝试了一下Pro中的解决方法,其实道理都一样.先来看看第一种方法:打开CMD,如果是ArcMap,输入如下命令: reg add HKE ...
- 如何将Excel表批量赋值到ArcGIS属性表
情景再现 现需要将Excel表信息批量赋值(不是挂接)到Shp文件的属性表,两张表的字段.记录数一模一样,至于为什么会出现这样的问题,咱也不敢问,只有想个法子把它搞定! 原始的Excel信息表共57列 ...
- 解析ArcGis的字段计算器(二)——有玄机的要素Geometry属性,在属性表标记重复点线面
这里所说的重复是指完成重复的,不是叠在一起的两个或多个要素,这种应该叫做“压盖”或“重叠”.重复往往是在合并多Shpfile文件时不小心重复导入造成的. 这里提供一种可能的解决办法,数据无价,请备份! ...
- arcEngine开发之查看属性表
这篇文章给出实现属性表功能的具体步骤,之后再对这些步骤中的代码进行分析. 环境准备 拖动TOCControl.MapControl控件到Form窗体上,然后拖动ContextMenuStrip控件至T ...
- AE二次开发中几个功能速成归纳(符号设计器、创建要素、图形编辑、属性表编辑、缓冲区分析)
/* * 实习课上讲进阶功能所用文档,因为赶时间从网上抄抄改改,凑合能用,记录一下以备个人后用. * * ----------------------------------------------- ...
随机推荐
- 分布式缓存Redis集群配置使用
Redis 简介 redis是一种开源的.基于内存的.可持久化的.高性能的Key-Value数据存储系统. redis能做什么? 持久化存储 高速缓存 消息中间件 ...
- ORM初探(一)
Object Relational Mapping(ORM): 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象 ...
- 西湖论剑2019-msc之奇怪的TTL
msc1给了一串很长的TTL字符,参考一些隐写的文章,猜测是在ttl中藏了信息,题目是这样的 我们截获了一些IP数据报,发现报文头中的TTL值特别可疑,怀疑是通信方嵌入了数据到TTL,我们将这些TTL ...
- Runnable和Callable之间的区别
Runnable和Callable之间的区别 1.Runnable任务执行后没有返回值:Callable任务执行后可以获得返回值 2.Runnable的方法是run(),没有返回值:Callable的 ...
- Docker(4):Docker集中化web界面管理平台—Shipyard部署
//关闭防火墙 并禁止自启 [root@localhost ~]# systemctl stop firewalld [root@localhost ~]# systemctl disable fir ...
- 实战 EF(LINQ) 如何以子查询的形式来 Join
如题,大多数网上关于 LINQ Join 的示例都是以 from x in TableA join ... 这样的形式,这种有好处,也有劣势,就是在比如我们使用的框架如果已经封装了很多方法,比如分页 ...
- Eclipse中快捷键Ctrl + Alt + 向上箭头 或者 Ctrl + Alt + 向下箭头与Windows冲突
原文地址:https://blog.csdn.net/buaaroid/article/details/50804608 clipse中按ctrl + alt + 向上箭头没有任何反应,按ctrl + ...
- Element ui 日期限制范围
时间限定范围: <el-date-picker type="date" placeholder="选择日期" v-model="addForm. ...
- Object 与 T的差别 导致swagger 的model 显示的数据为空
情景复现: 在整合swagger的时候,自己对原本定于的Object的data做了修改,把Object修改为了T,data的set方法的返回类型由于编译器没有报错,就没有去做修改, 这个时候就导致了, ...
- scala的多种集合的使用(2)之集合常用方法
一.常用的集合方法 1.可遍历集合的常用方法 下表列出了Traverable在所有集合常用的方法.接下来的符号: c代表一个集合 f代表一个函数 p代表一个谓词 n代表一个数字 op代表一个简单的操作 ...