如何运用jieba库分词
使用jieba库分词
一.什么是jieba库
1.jieba库概述
jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语。
2.jieba库的使用:(jieba库支持3种分词模式)
通过中文词库的方式识别
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本所有可能的词语都描述出来,有冗余
搜索引擎模式:在精确模式的基础上,对长词进行切分
3.jieba库是属于python中优秀的中文分词第三方库,需要额外安装
二.安装jieba库
途径1:百度jieba库下载(百度上很多jieba库的安装教程,可以参考一下)
方法2:在计算机命令行输入
pip install jieba
按下回车就会自动安装,稍微等待就可以了
三.函数库的调用

jieba库在python的 IDLE中运行时可以使用两种导入方式
(1)
导入库函数:import <库名>
使用库中函数:<库名> . <函数名> (<函数参数>)
例如:import jieba
jieba.lcut()
jieba.lcut(" ",cut_all=True)
jieba.lcut_for_search()

(2) 导入库函数:from <库名> import * ( *为通配符 )
使用库中函数:<函数名> (<函数参数>)
例如:from jieba import *
lcut()
lcut(" ",cut_all=True)
lcut_for_search()

四.jieba库的实际应用(对文本的词频统计)
文本是水浒传,百度上下载的
from jieba import *
excludes=lcut_for_search("头领两个一个武松如何只见说道军马众人那里")
txt=open("水浒传.txt","r").read()
words=lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
elif word =="及时雨" or word == "公明" or word =="哥哥" or word == "公明曰":
rword ="宋江"
elif word =="黑旋风" or word =="黑牛":
rword ="李逵"
elif word =="豹子头" or word == "林教头":
rword ="林冲"
elif word =="智多星" or word =="吴用曰":
rword ="吴用"
else:
rword=word
counts[word]=counts.get(word,0)+1
for word in excludes:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
运行结果:(有些多余的词语未做好排除,代码仍需要改进)

五.词云图(jieba库与wordcloud库的结合应用)
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from jieba import * # 生成词云
def create_word_cloud(filename):
text = open("{}.txt".format(filename)).read()
font = 'C:\Windows\Fonts\simfang.ttf'
wordlist = cut(text, cut_all=True) # 结巴分词
wl = " ".join(wordlist) # 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="black",
# 设置最大显示的词云数
max_words=200,
# 这种字体都在电脑字体中,一般路径
font_path= font,
height=1200,
width=1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=100,
) myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('img_book.png') # 把词云保存下 if __name__ == '__main__':
create_word_cloud('水浒传')
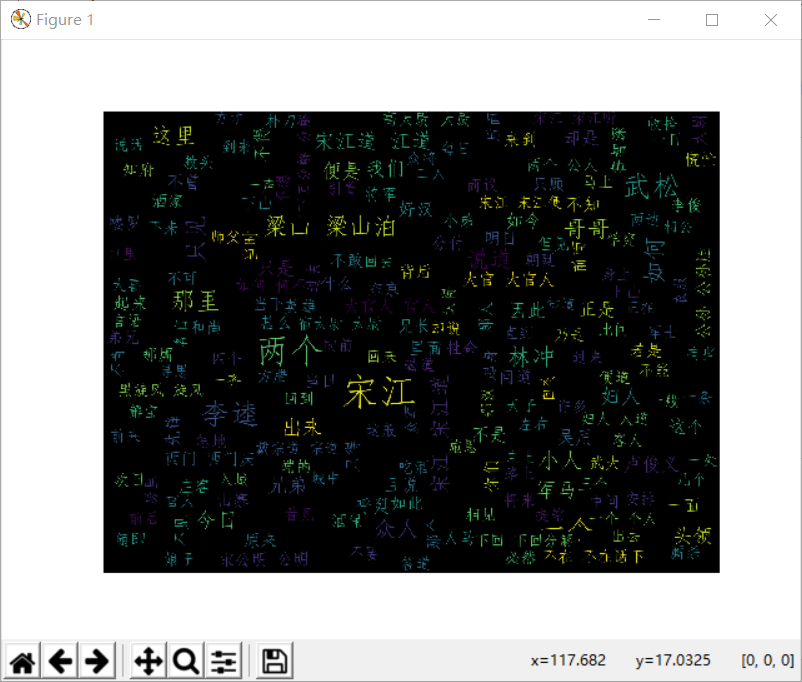
运行结果
如何运用jieba库分词的更多相关文章
- python jieba 库分词结合Wordcloud词云统计
import jieba jieba.add_word("福军") jieba.add_word("少安") excludes={"一个", ...
- jieba库分词统计
代码在github网站,https://github.com/chaigee/chaigee,中的z3.py文件 py.txt为团队中文简介文件 代码运行后词频统计使用xlwt库将数据发送到excel ...
- jieba库分词
(1)团队简介的词频统计 import jieba import collections s="制作一个购票小程序,这个购票小程序可以根据客户曾经的购票历史" s+="和 ...
- 运用jieba库分词
代码: 统计出团队中文简介中词频 import jieba txt=open("C:\\Users\\Administrator\\Desktop\\介绍.txt","r ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- python jieba库的基本使用
第一步:先安装jieba库 输入命令:pip install jieba jieba库常用函数: jieba库分词的三种模式: 1.精准模式:把文本精准地分开,不存在冗余 2.全模式:把文中所有可能的 ...
- python实例 三国人物出场次序 jieba库
#Cal3kingdoms.py import jieba txt = open("threekingdoms.txt", "r", encoding=&quo ...
- python第三方库------jieba库(中文分词)
jieba“结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 特点支持三种分词模式: 精确模式,试图将句子最精确地切开, ...
- python 读写txt文件并用jieba库进行中文分词
python用来批量处理一些数据的第一步吧. 对于我这样的的萌新.这是第一步. #encoding=utf-8 file='test.txt' fn=open(file,"r") ...
随机推荐
- django连接sqlserver
http://www.cnblogs.com/yijiaming/p/9684601.html 方法一: 1.需要安装pymssql pip install pymssql 2.使用方法: impor ...
- LeetCode算法题-Self Dividing Numbers(Java实现)
这是悦乐书的第305次更新,第324篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第173题(顺位题号是728).自分割数是一个可被其包含的每个数字整除的数字.例如,12 ...
- Parameter 'ids' not found. Available parameters are [array]
传的参数是一个数组, Long[] ids 后台错误写法 <delete id="deleteById"> delete from table where id in ...
- Scrapy框架-Spider和CrawlSpider的区别
目录 1.目标 2.方法1:通过Spider爬取 3. 通过CrawlSpider爬取 1.目标 http://wz.sun0769.com/index.php/question/questionTy ...
- Why Ambari is setting the security protocol of the kafka to PLAINTEXTSASL instead of SASL_PLAINTEXT?
首页 / Data Ingestion & Streaming / Why Ambari is setting the security protocol of the kafka to PL ...
- codeforces div2 220 解题
这套题我只写了a, b, c.. 对不起,是我太菜了. A:思路:就是直接简化为一个矩阵按照特定的步骤从一个顶角走到与之对应的对角线上的顶角.如图所示. 解释一下特定的步骤,就像马走日,象走田一样. ...
- [蓝桥杯]2016蓝桥省赛B组题目及详解
/*——————————————————————————————————————————————————————————— [结果填空题]T1 (分值:3) 题目:煤球数目 有一堆煤球,堆成三角棱锥形 ...
- g.DrawImage图片合成在本机可以,在服务器一直报内存不够
g.DrawImage图片合成在本机可以,在服务器一直报内存不够,发现是这个要设为false
- hashlib 模块:加密
import hashlib # 基本使用 cipher = hashlib.md5('需要加密的数据的二进制形式'.encode('utf-8')) print(cipher.hexdigest() ...
- 基于Android P系统对selinux相关整理
1.首先selinux是一种加强文件安全的一种策略.主要包含进程和文件对象. 在system\sepolicy\public\attributes文件中有: # All types used for ...