centos7下kubernetes(11。kubernetes-运行一次性任务)
容器按照持续运行的时间可以分为两类:服务类容器和工作类容器
服务类容器:持续提供服务
工作类容器:一次性任务,处理完后容器就退出
Deployment,replicaset和daemonset都用于管理服务类容器,
对于工作类的容器,我们用job
编辑一个简单的job类型的yml文件
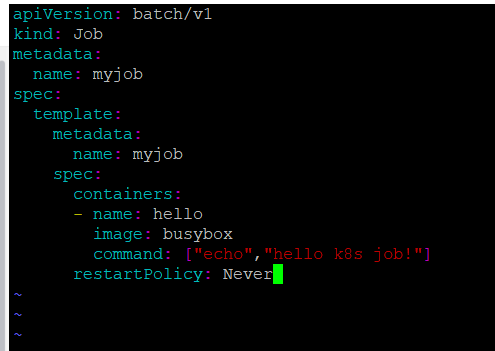
1.apiversion:当前job的apiversion是batch/v1
2.kind:当前的资源类型是job
3.restartpolicy指定什么情况下需要重启容器。对于job只能设置为never或者onfailure
对于其他的controller(比如deployment,replicaset等)可以设置为always
创建job应用

通过kubectl get job进行查看

显示destire为1,成功1
说明是按照预期启动了一个pod,并且成功执行
查看pod的状态

由于myjob的pod处于completed的状态,所以需要加--show-all参数才能显示出来
通过kubectl logs 查看pod标准输出

如果job没有执行成功,怎么办?
修改job.yml文件,故意引起一个错误,然后重新启动myjob
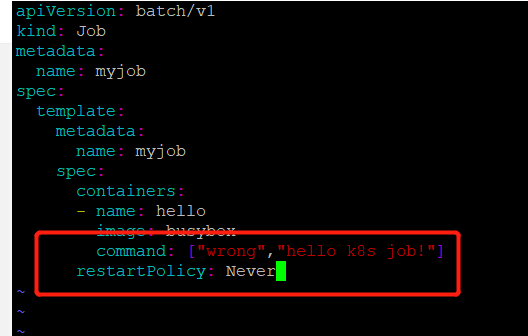
先将原来的job删除

然后重新启动一个新的job

重新启动一个job,我们发现有一个未成功的job,查看pod的时候竟然有两个job相关的pod,目标job只有1个啊,为什么??
我们再次查看一下
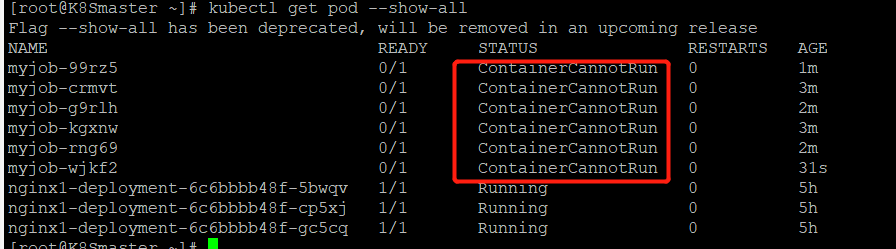
目前达到了6个
原因是:当地一个pod启动时,容器失败退出,根据restartPolicy:Never,此失败容器不会被重启,但是job destired的pod是1,目前successful为1。由于我们的命令是错误的,successful永远不能到1,
job contorller会一直创建新的pod达到job得期望状态,最多重新创建6次,因为K8S为job提供了spec.bakcofflimits来限制重试次数,默认为6.
如果将restartpolicy设置为OnFailure会怎么样?我们来实验一下
修改job.yml文件
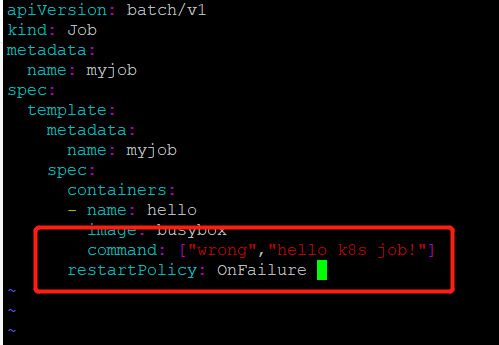
将restartpolicy修改为OnFailure
重新启动job.yml

pod数量只有1,job为失败得状态
但是pod得restart得次数在变化,说明onfailure生效,容器失败后会自动重启
并行执行job
之前我们得实验都是一次运行一个job里只有一个pod,当我们同时运行多个pod得时候,怎么进行设置呢?
可以通过:parallelism设置
修改job.yml文件
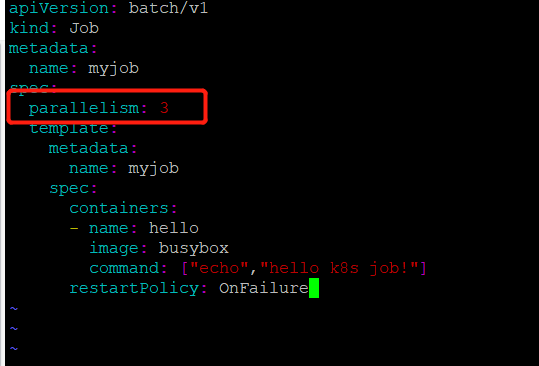
此次我们执行一个job同时运行3个pod
kubectl apply -f job.yml
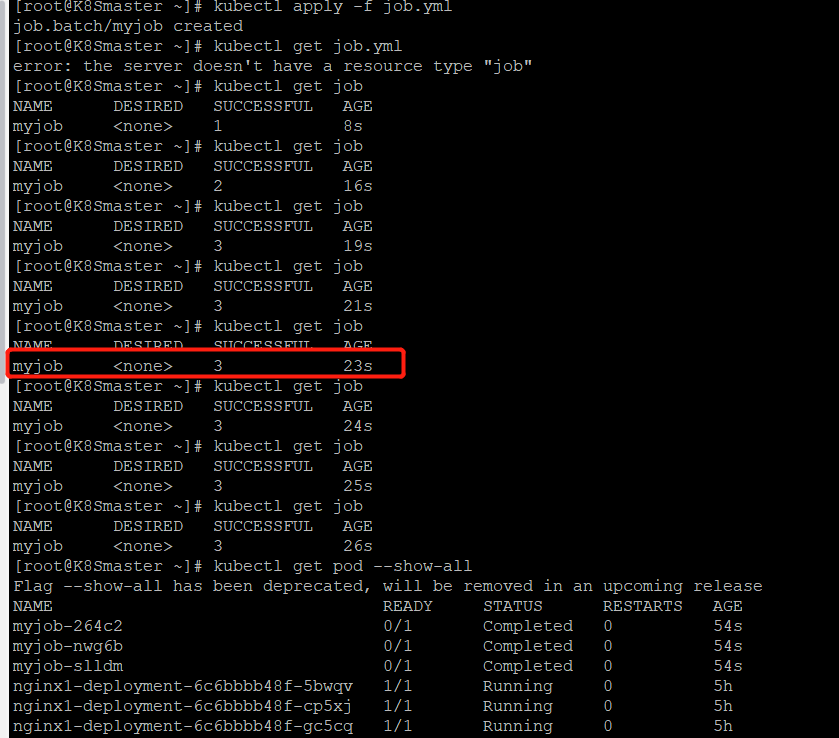
job一共启动了3个pod,而且AGE相同,说明是并行运行得。
还可以通过completions设置job成功完成pod的总数;
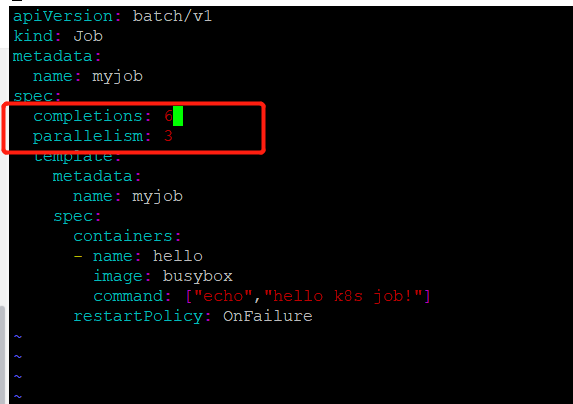
配置含义:每次运行3个pod,知道运行了6个结束
重新执行一下
kubectl apply -f job.yml
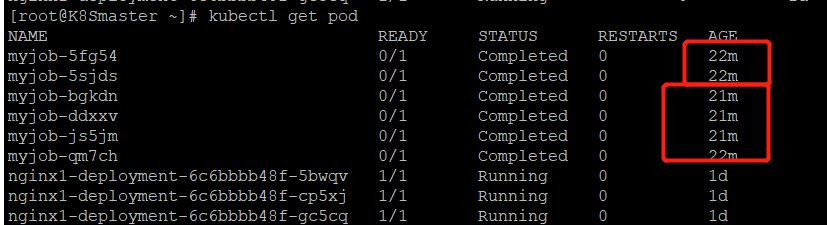
也不是很准,但是确实不是同时并行启动的
定时执行job
kubernetes提供了类似crontab定时执行任务的功能
首先修改apiserver使api支持cronjob
vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --runtime-config=batch/v1beta1=true 加入这一行
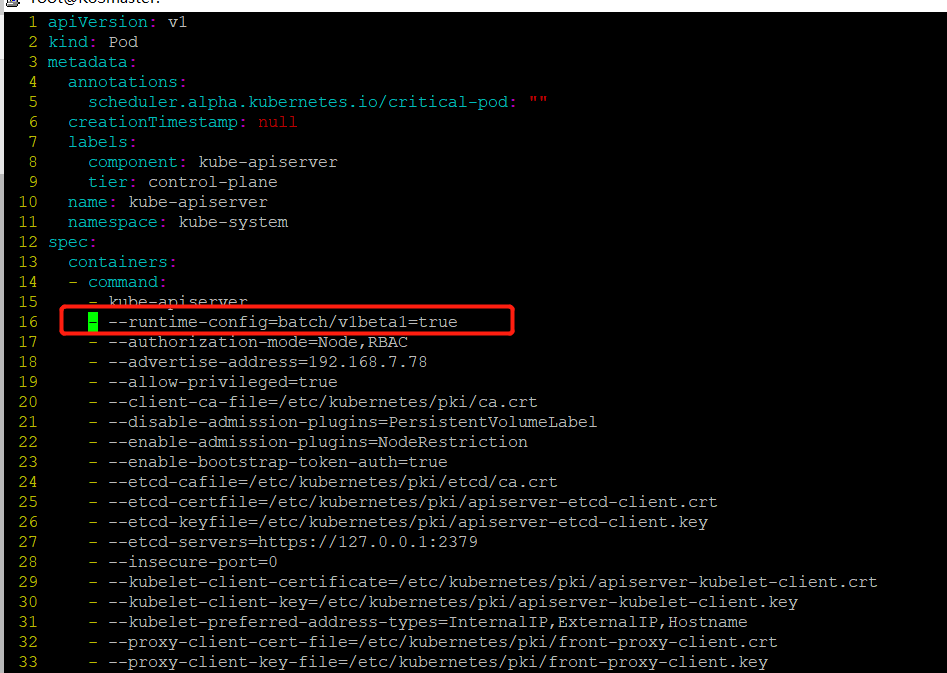
保存退出
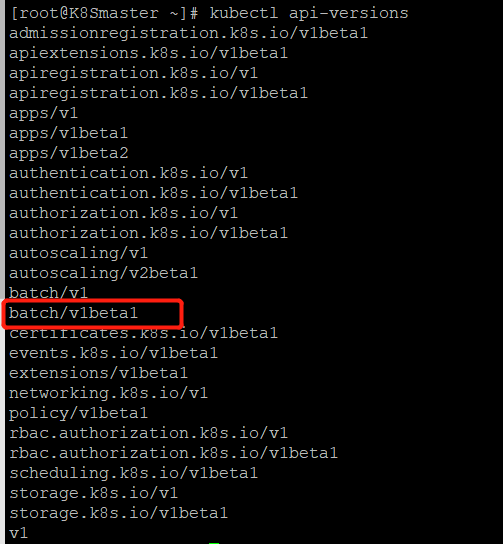
kubectl apiversions 查看api版本(如果这里没有生效的话,需要重启kubelet这个服务)
systemctl restart kubelet.service
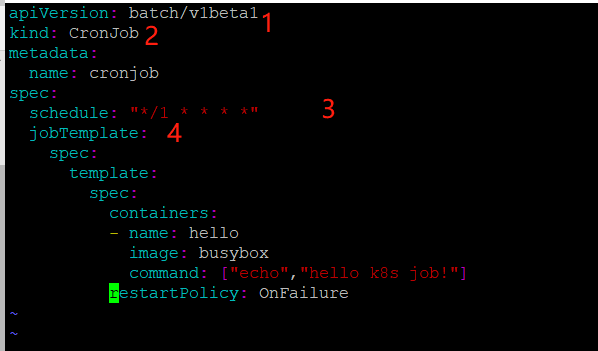
修改yml文件如下:
apiVersion: batch/v1beta1 batch/v1beta1当前cronjob的apiserver
kind: CronJob 当前资源类型为cronjob
metadata:
name: cronjob
spec:
schedule: "*/1 * * * *" 指定什么时候运行job,格式与linux中的计划任务一致
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo","hello k8s job!"]
restartPolicy: OnFailure
~
运行这个job
kubectl apply -f job.yml
如果出现一下错误请一定要检查yml文件的内容,进行修改

正常运行如下:

查看cronjob
kubectl get cronjob

查看job,通过时间间隔可以看到,每1分种创建一个pod
kubectl get job

查看pod日志

删除cronjob
kubectl delete cronjob cronjob

centos7下kubernetes(11。kubernetes-运行一次性任务)的更多相关文章
- Centos7下yum安装kubernetes
一.前言 Kubernetes 是Google开源的容器集群管理系统,基于Docker构建一个容器的调度服务,提供资源调度.均衡容灾.服务注册.动态扩缩容等功能套件,目前centos yum源上 ...
- centos7下搭建JAVA项目运行环境。 JAVA+MYSQL+TOMCAT+NGINX
环境: centos 7 64位 一.配置mysql 5.71.下载mysql源安装包wget http://dev.mysql.com/get/mysql57-community-release-e ...
- [Kubernetes]关于 Kubernetes ,你想要的,都在这儿了
陆陆续续,关于 Kubernetes 写了有 20+ 篇文章了. 今天这篇文章来一个整合,从实践到理论,可以按需查看(我是按照博客发表时间来排序的,如果后续有想要更新的内容,也会及时更新到这篇文章中) ...
- centos7下kubernetes(3。部署kubernetes)
环境:三个centos7 K8s2是Master;K8s1是node1:K8s3是node2 官方文档:https://kubernetes.io/docs/setup/independent/ins ...
- [Kubernetes]CentOS7下Etcd集群搭建
Etcd简要介绍 Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息 Etcd构建自身高可用集群主要有三种形式: ①静态发现: 预先已知 Etcd 集 ...
- centos7.5下kubeadm安装kubernetes集群安装
文章是按https://blog.csdn.net/Excairun/article/details/88962769,来进行操作并记录相关结果 版本:k8s V14.0,docker-ce 18.0 ...
- [Kubernetes]CentOS7下搭建Harbor仓库
环境依赖: Harbor仓库需要环境:Python 2.7或以上版本,Docker 1.10或以上,Docker Compose 1.6.0或以上. CentOS7自带Python,所以不需要安装. ...
- Centos7 使用 kubeadm 安装Kubernetes 1.13.3
目录 目录 什么是Kubeadm? 什么是容器存储接口(CSI)? 什么是CoreDNS? 1.环境准备 1.1.网络配置 1.2.更改 hostname 1.3.配置 SSH 免密码登录登录 1.4 ...
- centos7使用kubeadm搭建kubernetes集群
一.本地实验环境准备 服务器虚拟机准备 IP CPU 内存 hostname 192.168.222.129 >=2c >=2G master 192.168.222.130 >=2 ...
- 从centos7镜像到搭建kubernetes集群(kubeadm方式安装)
在网上看了不少关于Kubernetes的视频,虽然现在还未用上,但是也是时候总结记录一下,父亲常教我的一句话:学到手的东西总有一天会有用!我也相信在将来的某一天会用到现在所学的技术.废话不多扯了... ...
随机推荐
- 你安装的是SUN/Oracle JDK还是OpenJDK?
目录 1 如何查看你安装的JDK版本 1.1 要用到的命令行工具 1.2 查看JDK的版本 2 什么是 OpenJDK 2.1 OpenJDK 的来历 2.2 Oracle JDK的来历 3 Orac ...
- Chapter 4 Invitations——12
"I don't know what you mean," I said, my voice guarded. “我不知道你什么意思”我声音谨慎地说道. "It's be ...
- 用PMML实现机器学习模型的跨平台上线
在机器学习用于产品的时候,我们经常会遇到跨平台的问题.比如我们用Python基于一系列的机器学习库训练了一个模型,但是有时候其他的产品和项目想把这个模型集成进去,但是这些产品很多只支持某些特定的生产环 ...
- [软件开发技巧]·树莓派极简安装OpenCv
树莓派极简安装OpenCv 个人主页–> https://xiaosongshine.github.io/ 因为最近在开发使用树莓派+usb摄像头识别模块,打算用OpenCv,发现网上的树莓派O ...
- 【深度学习与TensorFlow 2.0】卷积神经网络(CNN)
注:在很长一段时间,MNIST数据集都是机器学习界很多分类算法的benchmark.初学深度学习,在这个数据集上训练一个有效的卷积神经网络就相当于学习编程的时候打印出一行“Hello World!”. ...
- leetcode — interleaving-string
/** * Source : https://oj.leetcode.com/problems/interleaving-string/ * * * Given s1, s2, s3, find wh ...
- MaxCompute/DataWorks权限问题排查建议
MaxCompute/DataWorks权限问题排查建议 __前提:__MaxCompute与DataWorks为两个产品,在权限体系上既有交集又要一定的差别.在权限问题之前需了解两个产品独特的权限体 ...
- SpringCloud(2) 服务注册和发现Eureka Server
一.简介 EureKa在Spring Cloud全家桶中担任着服务的注册与发现的落地实现.Netflix在设计EureKa时遵循着AP原则,它基于REST的服务,用于定位服务,以实现云端中间层服务发现 ...
- 【.Net Core】获取绝对路径、相对路径
一.绝对路径 1.获取应用程序运行当前目录Directory.GetCurrentDirectory(). System.IO命名空间中存在Directory类,提供了获取应用程序运行当前目录的静态方 ...
- 关闭open页面时刷新父页面列表
var winObjEI = window.open("/Invoice/InvoiceViewEI?invoiceid=" + data.InvoiceId); ; //关闭op ...