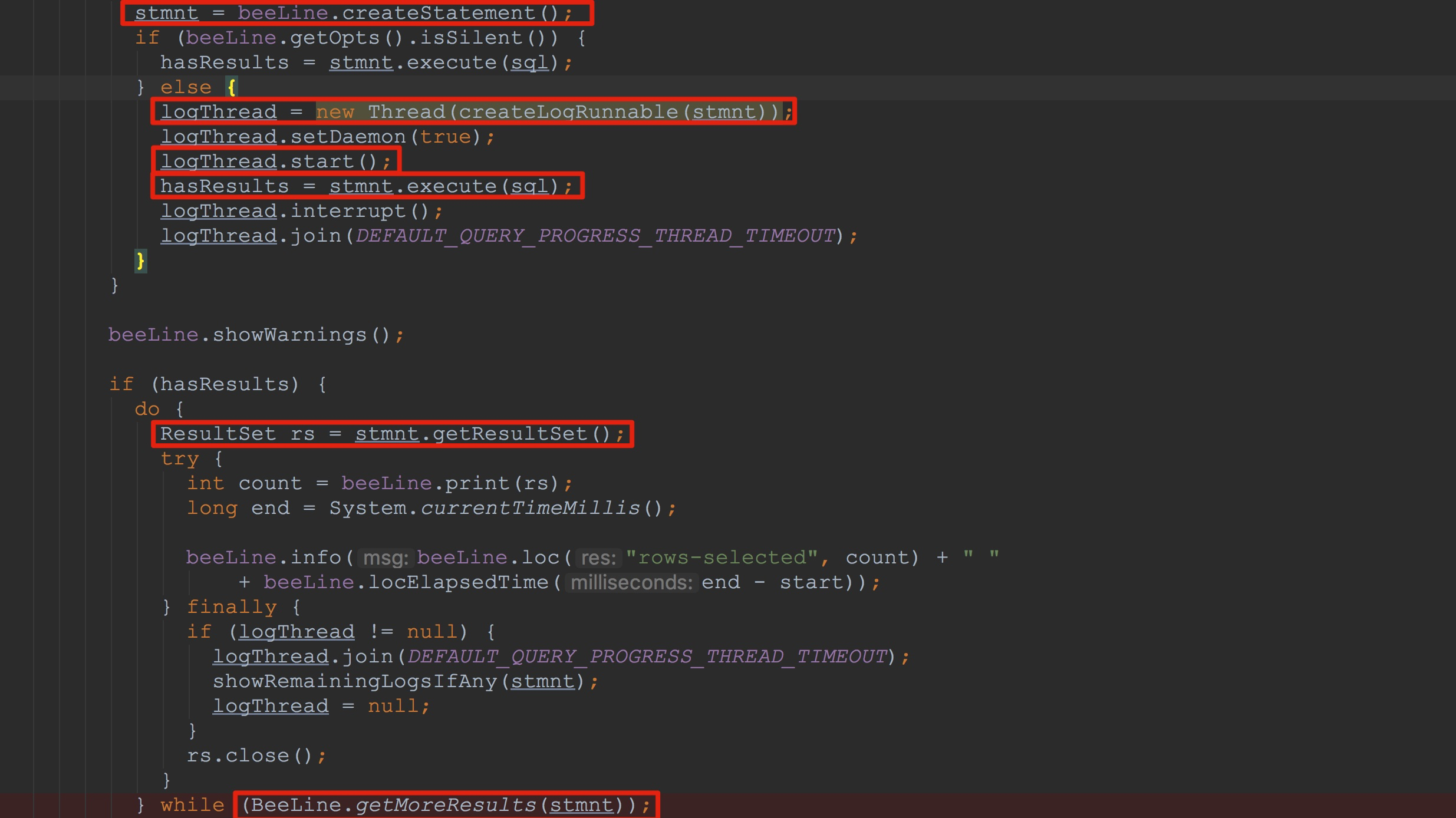
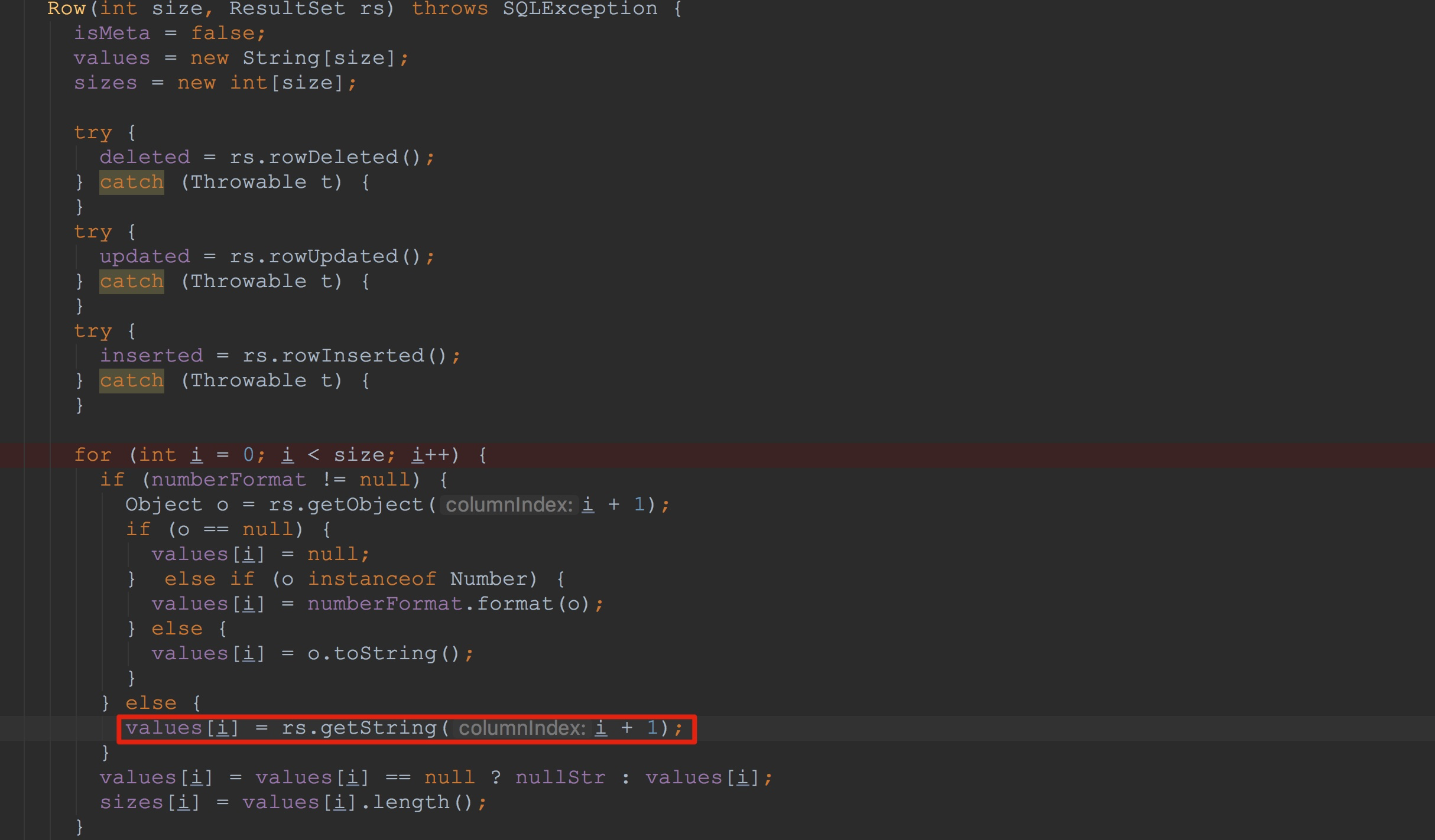
hive中beeline取回数据的完整流程

hive中beeline取回数据的完整流程的更多相关文章
- Hive中的HiveServer2、Beeline及数据的压缩和存储
1.使用HiveServer2及Beeline HiveServer2的作用:将hive变成一种server服务对外开放,多个客户端可以连接. 启动namenode.datanode.resource ...
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- CSS从大图中抠取小图完整教程(background-position应用)
CSS从大图中抠取小图完整教程(background-position应用) 转自: http://www.cnblogs.com/iyangyuan/archive/2013/06/01/3111 ...
- SQL Server中CURD语句的锁流程分析
我只在数据库选项已开启“行版本控制的已提交读”(READ_COMMITTED_SNAPSHOT为ON)中进行了观察. 因此只适用于这种环境的数据库. 该类数据库支持四种不同事务隔离级别,下面分别观察数 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Grunt搭建自动化web前端开发环境--完整流程
Grunt搭建自动化web前端开发环境-完整流程 jQuery在使用grunt,bootstrap在使用grunt,百度UEditor在使用grunt,你没有理由不学.不用! 1. 前言 各位web前 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- hive中数据存储格式对比:textfile,parquent,orc,thrift,avro,protubuf
这篇文章我会从业务中关注的: 1. 存储大小 2.查询效率 3.是否支持表结构变更既数据版本变迁 5.能否避免分隔符问题 6.优势和劣势总结 几方面完整的介绍下hive中数据以下几种数据格式:text ...
- Hive中自定义Map/Reduce示例 In Java
Hive支持自定义map与reduce script.接下来我用一个简单的wordcount例子加以说明. 如果自己使用Java开发,需要处理System.in,System,out以及key/val ...
随机推荐
- Java新手问题集锦
Java是目前最流行的编程语言之一——它可以用来编写Windows程序或者是Web应用,移动应用,网络程序,消费电子产品,机顶盒设备,它无处不在. 有超过30亿的设备是运行在Java之上的.根据Ora ...
- 在Net MVC中应用JsTree
先实现个基本用法 1 - 引入js和css 2 - html <div id="list_left" class="col-md-2 pre-scrollable ...
- 这篇通俗实用的Vlookup函数教程,5分钟就可以包你一学就会
如何利用Vlookup函数获取学号中的班级信息.换言之,咱们源数据中放着姓名性别学号班级等信息,而在另一张表格中一定有学号信息,但其他信息就未必有,这需要我们将缺失的信息自动同步过去.使用vlooku ...
- Linux中CPU亲和性(affinity)
0.准备知识 超线程技术(Hyper-Threading):就是利用特殊的硬件指令,把两个逻辑内核(CPU core)模拟成两个物理芯片, 让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和 ...
- Github 上怎样把新 commits 使用在自己的 fork 上
作者:黄晓佳 链接:https://www.zhihu.com/question/20393785/answer/105370502 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转 ...
- Docker 学习6 Docker存储卷
一.什么是存储卷 二.为什么要用到数据卷 三.数据卷是怎么被管理的 四.存储卷种类 五.在容器中使用存储卷 1.只声明容器路径 [root@localhost docker]# docker run ...
- CentOs查看某个字符串在某个目录下的行数
如果你想在当前目录下 查找"hello,world!"字符串,可以这样: grep -rn "hello,world!" ./ ./ : 表示路径为当前目录. ...
- python3控制语句---选择结构语句
python中的控制语句主要有if.if--else.if--slif--else.pass语句.其实python的控制语句与其他语言的控制语句工作原理基本一样.控制语句可以分为选择结构语句和循环结构 ...
- 运用SqlSugar框架+Axios写的增删查案例
使用SqlSugar框架需要引用NuGet程序包否则会出现报错. 前台页面创建代码: @{ ViewBag.Title = "Index";}<h2>Index& ...
- 如何简单地理解Python中的if __name__ == '__main__'
https://blog.csdn.net/yjk13703623757/article/details/77918633 1. 摘要 通俗的理解__name__ == '__main__':假如你叫 ...