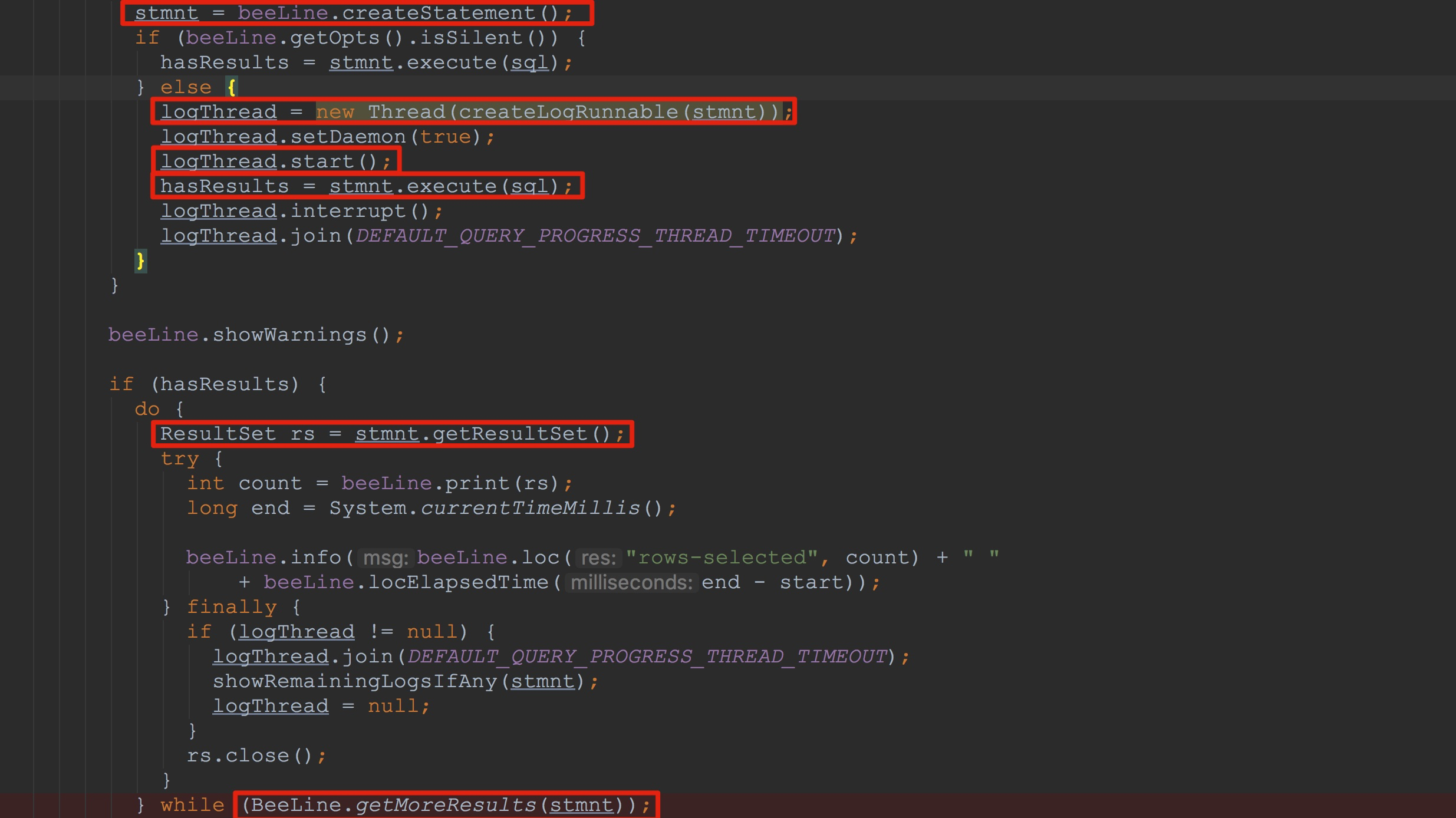
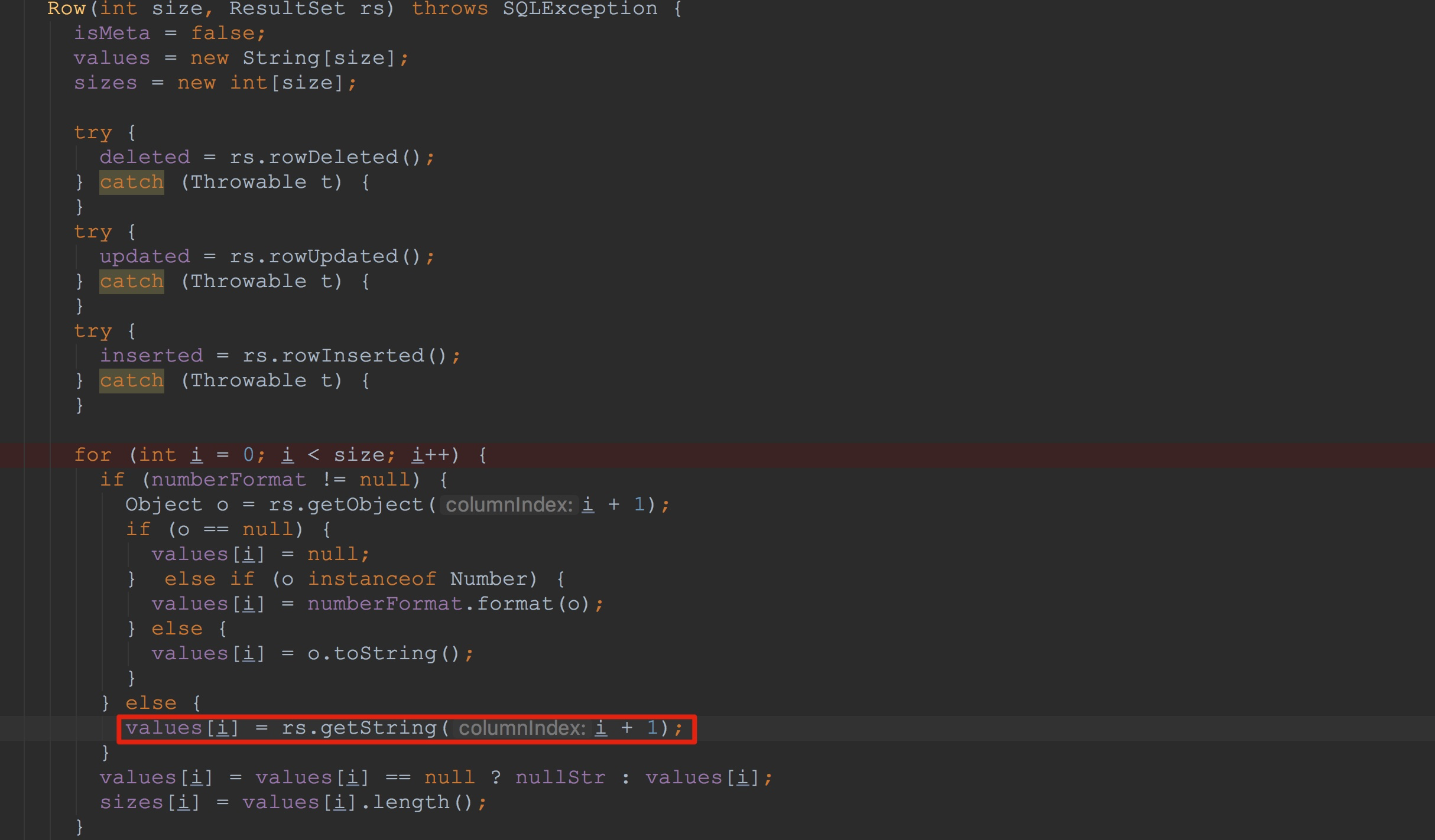
hive中beeline取回数据的完整流程

hive中beeline取回数据的完整流程的更多相关文章
- Hive中的HiveServer2、Beeline及数据的压缩和存储
1.使用HiveServer2及Beeline HiveServer2的作用:将hive变成一种server服务对外开放,多个客户端可以连接. 启动namenode.datanode.resource ...
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- CSS从大图中抠取小图完整教程(background-position应用)
CSS从大图中抠取小图完整教程(background-position应用) 转自: http://www.cnblogs.com/iyangyuan/archive/2013/06/01/3111 ...
- SQL Server中CURD语句的锁流程分析
我只在数据库选项已开启“行版本控制的已提交读”(READ_COMMITTED_SNAPSHOT为ON)中进行了观察. 因此只适用于这种环境的数据库. 该类数据库支持四种不同事务隔离级别,下面分别观察数 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Grunt搭建自动化web前端开发环境--完整流程
Grunt搭建自动化web前端开发环境-完整流程 jQuery在使用grunt,bootstrap在使用grunt,百度UEditor在使用grunt,你没有理由不学.不用! 1. 前言 各位web前 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- hive中数据存储格式对比:textfile,parquent,orc,thrift,avro,protubuf
这篇文章我会从业务中关注的: 1. 存储大小 2.查询效率 3.是否支持表结构变更既数据版本变迁 5.能否避免分隔符问题 6.优势和劣势总结 几方面完整的介绍下hive中数据以下几种数据格式:text ...
- Hive中自定义Map/Reduce示例 In Java
Hive支持自定义map与reduce script.接下来我用一个简单的wordcount例子加以说明. 如果自己使用Java开发,需要处理System.in,System,out以及key/val ...
随机推荐
- Oracle 正则表达式 分割字符串
inData='12345|张三|男' SELECT REGEXP_SUBSTR (inData, '[^|]+', 1,1) into 用户ID FROM DUAL;SELECT REGEXP_SU ...
- [转] 使用Node.js实现简易MVC框架
在使用Node.js搭建静态资源服务器一文中我们完成了服务器对静态资源请求的处理,但并未涉及动态请求,目前还无法根据客户端发出的不同请求而返回个性化的内容.单靠静态资源岂能撑得起这些复杂的网站应用,本 ...
- 单机千万级MQTT连接服务器测试报告
目标:测试创建1000万客户端连接到服务器端,服务器操作系统 Linux(任意一款发行版服务器版本).分别在两台硬件一样的服务器,其中一台用于服务器端运行,另一台用于创建千万客户端连接客户端机器.在硬 ...
- html_Dom
Document: 每个载入浏览器的HTML文档都会成为一个Document对象. Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问. 并且Document 对象是 Wi ...
- 部分手机浏览器存在将ajax请求当成广告过滤的情况,及解决方案
我们发现h5页面在某些浏览器请求不到数据,经过排查,是浏览器的广告拦截模块搞的鬼. 通过删减参数,发现adtype和adnum参数去掉后,接口可以正常请求,开始以为是官方拦截关键词带有ad的参数,后来 ...
- MDK5 设置project targents?如何实现的有知道的请共享一下谢谢感激不尽!!!!
就在刚刚阅读NRF51822相关的文档时遇到问题,官方给出了一份模板,我从我安装的example中找出了官方的列程,看到是soft config的方式配置的,于是根据列程的配置,自己新建了一个工程之后 ...
- Alpha冲刺(1/10)——2019.4.23
作业描述 课程 软件工程1916|W(福州大学) 团队名称 修!咻咻! 作业要求 项目Alpha冲刺(团队) 团队目标 切实可行的计算机协会维修预约平台 开发工具 Eclipse 团队信息 队员学号 ...
- HBase数据库增删改查常用命令操作
最近测试用到了Hbase数据库,新建一个学生表,对表进行增删改查操作,把常用命令贴出来分享给大家~ 官方API:https://hbase.apache.org/book.html#quickstar ...
- 平时作业六 java
编写一个Java应用程序,使用Java的输入输出流技术将Input.txt的内容(Input.txt为文本文件)逐行读出,每读出一行就顺序为其添加行号(从1开始,逐行递增),并写入到另一个文本文件Ou ...
- Java实现生产者与消费者模式
生产者不断向队列中添加数据,消费者不断从队列中获取数据.如果队列满了,则生产者不能添加数据:如果队列为空,则消费者不能获取数据.借助实现了BlockingQueue接口的LinkedBlockingQ ...