热血动漫番太好看了!用Python爬取了1T的动漫,内存都爆了

最近被室友安利热血动漫番《终末的女武神》和《拳愿阿修罗》,太上头了周末休息熬夜看完了。不过资源不太好找,辣条一怒爬取了资源,这下可以看个够了。室友崇拜连连,想起了我的班花,快点开学啊,阿西吧...
Python爬虫-vip动漫采集
效果展示
爬取目标
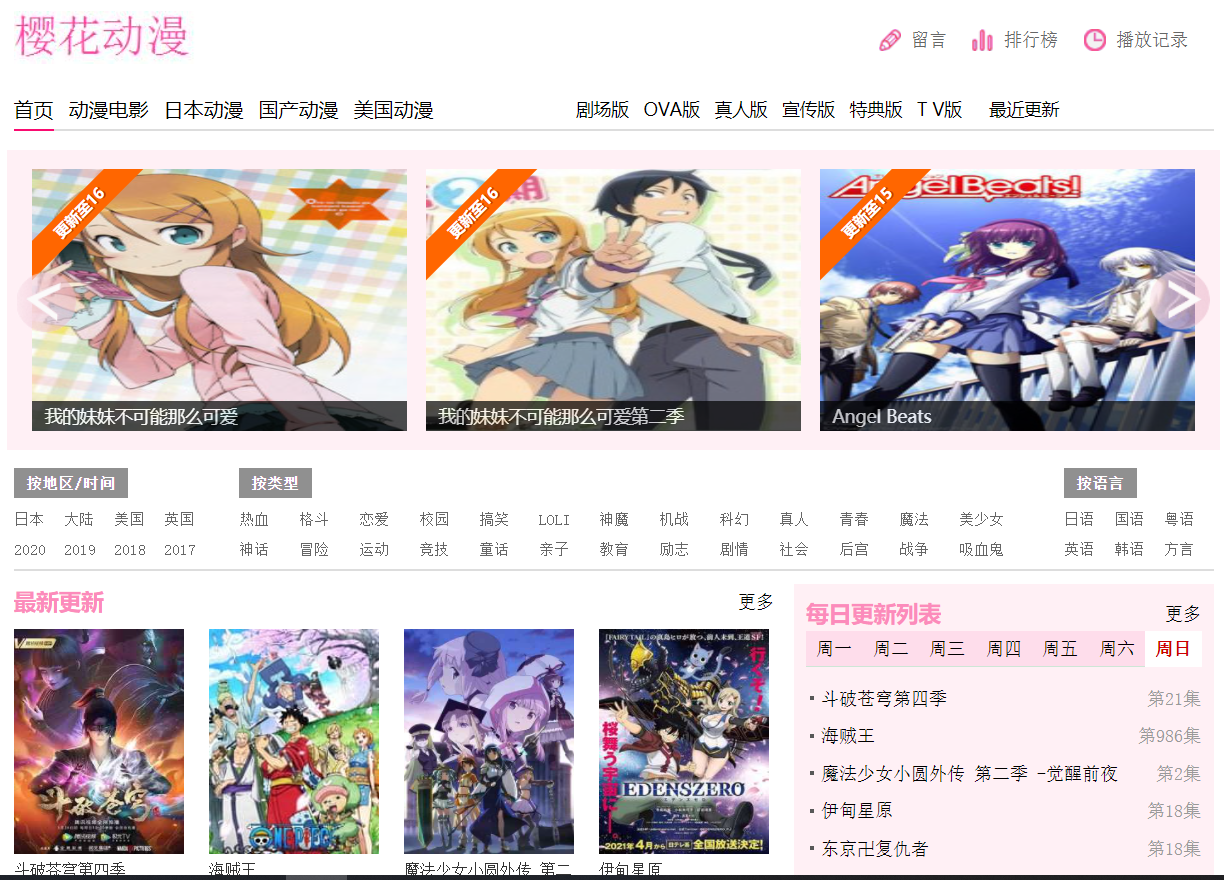
网站目标:樱花动漫
工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,lxml, re,tqdm
重点学习内容
正则的使用 tqdm的使用 各种音频数据的处理
项目思路解析
搜索你需要的动漫数据,根据自己需要的视频不同解析视频的方法也是不一样的(会挑选两种视频进行解析)
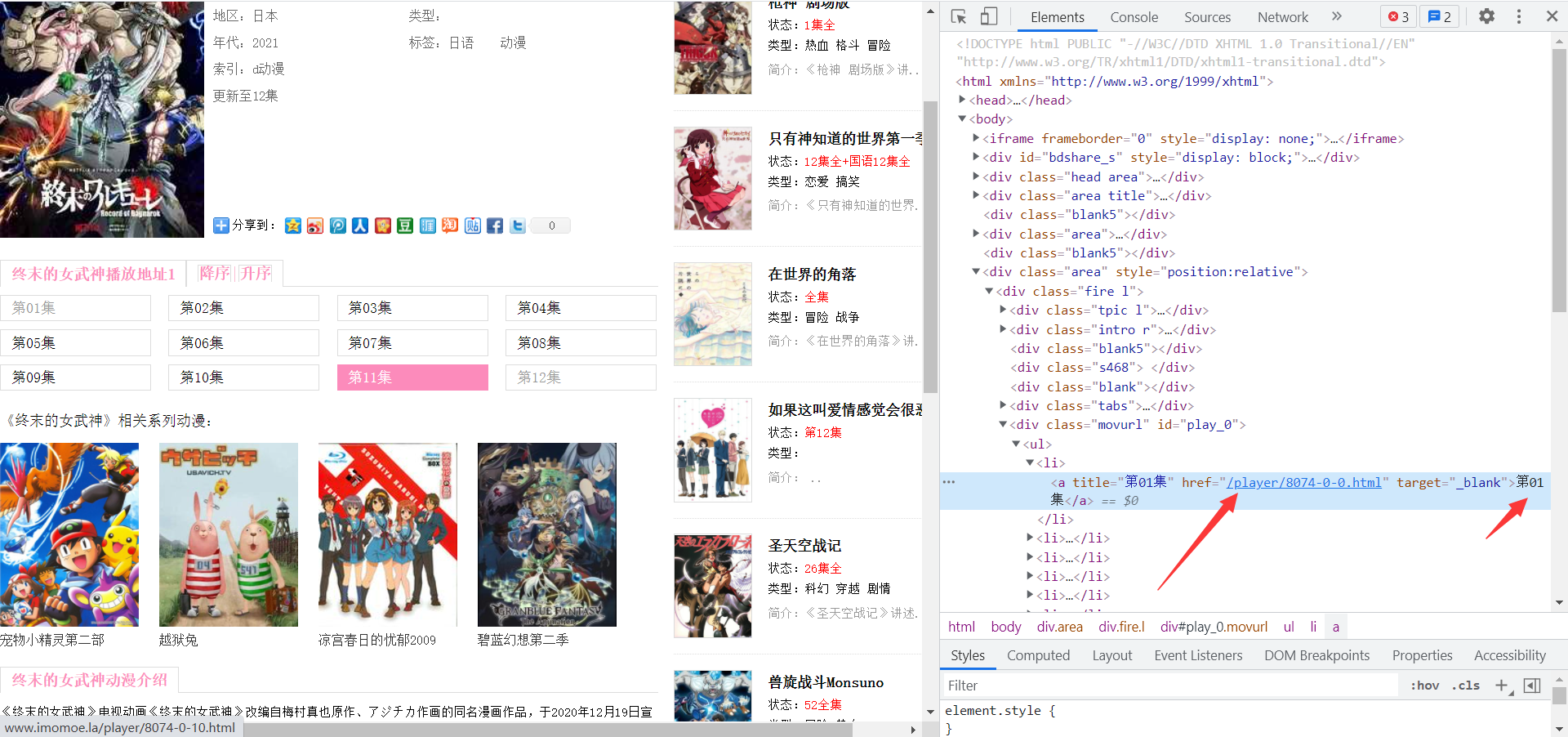
在当前页面需要提取出对应的章节信息,获取到章节信息的a标签的跳转内容,提取出每个章节的名字,提取章节的方法我使用的xpath的方法(各位大佬可自行尝试其他的方法)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Referer': 'http://www.imomoe.la/search.asp'
}
url = 'http://www.imomoe.la/view/8024.html'
response = requests.get(url, headers=headers)
# print(response.content.decode('gbk'))
html_data = etree.HTML(response.content.decode('gbk'))
chapter_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/text()')
chapter_url_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/@href')[0]
url的数据需要自行拼接,根据新的url获取详情页面的数据
按照正常思路首先应该查看播放地址是否为静态数据
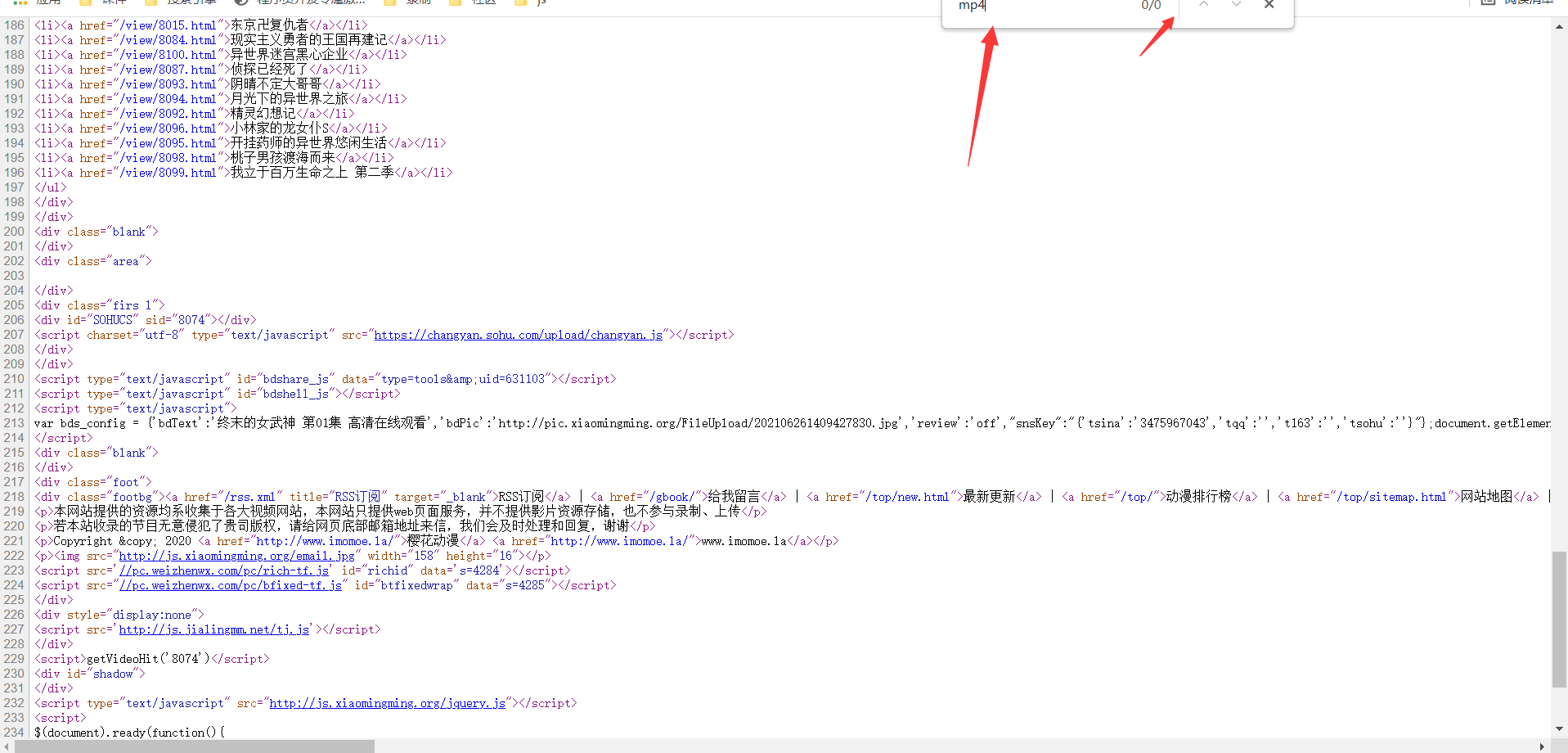
明显看出数据并不是静态数据,在区分是否为动态数据,通过抓包工具进行获取。
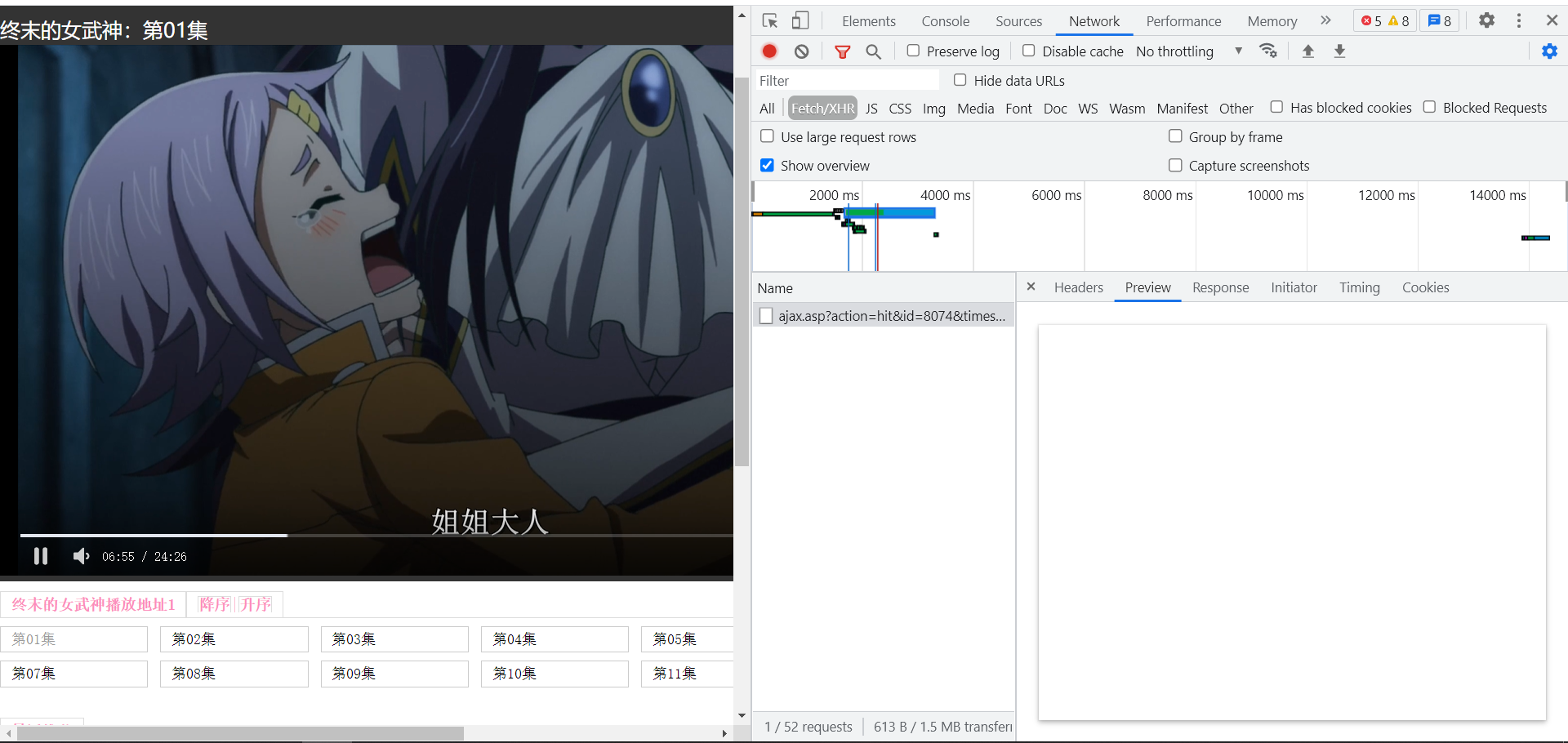
也并不是动态数据,媒体数据也不知道怎么形成的。

从头在来从前端页面在进行解析,找视频页面的事件。
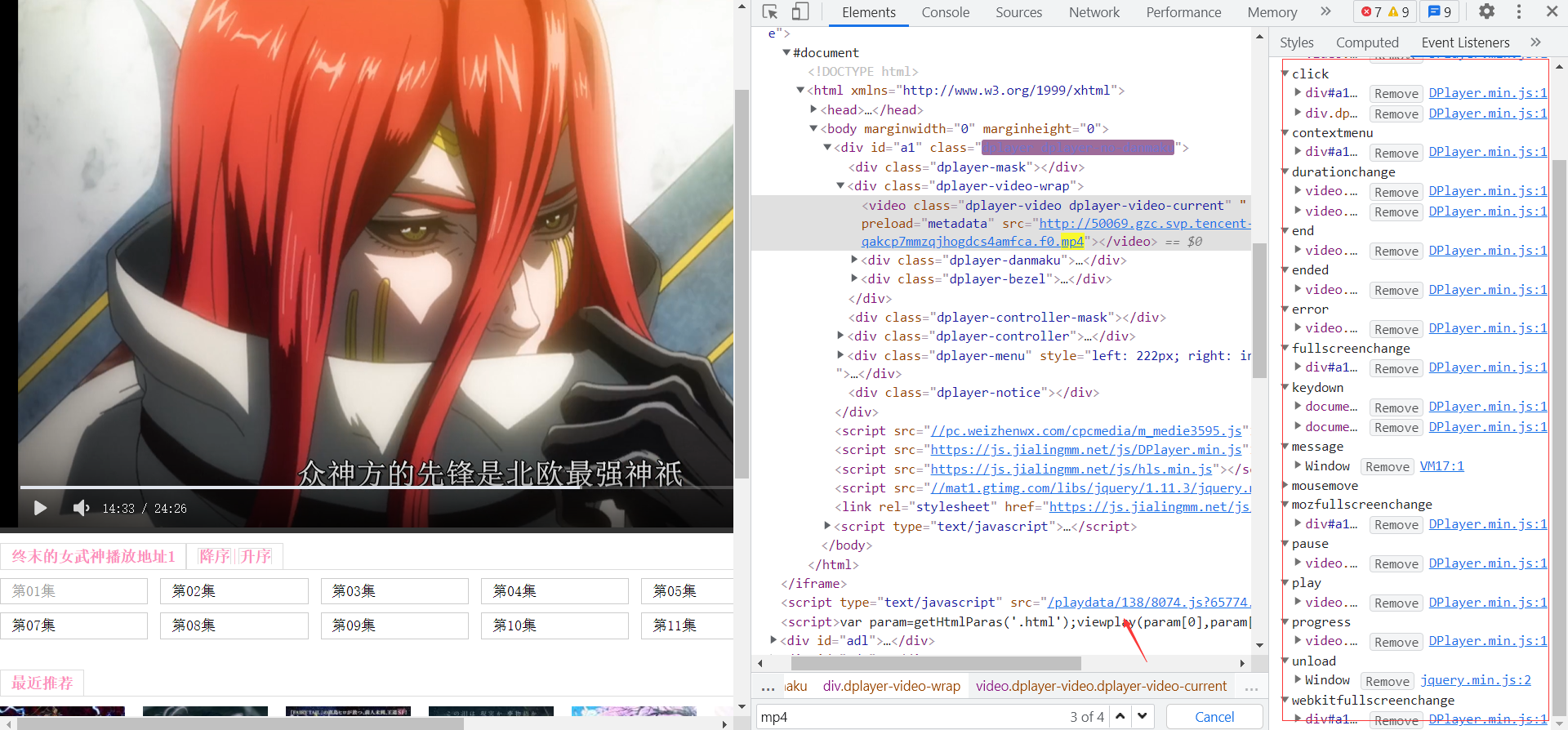
并没有发现有效数据,但是在iframe下面的Script标签有js跳转地址 ,解析的数据网址和视频的播放地址是一样的域名, 点击查看, 这不是就是我们找的视频播放地址嘛 ,终于找到了,开始实现 在当前页面通过xpath方式提取出script里的js跳转地址, 拼接出新的视频链接播放地址,发送请求,通过正则表达式提取出所有MP4播放地址。
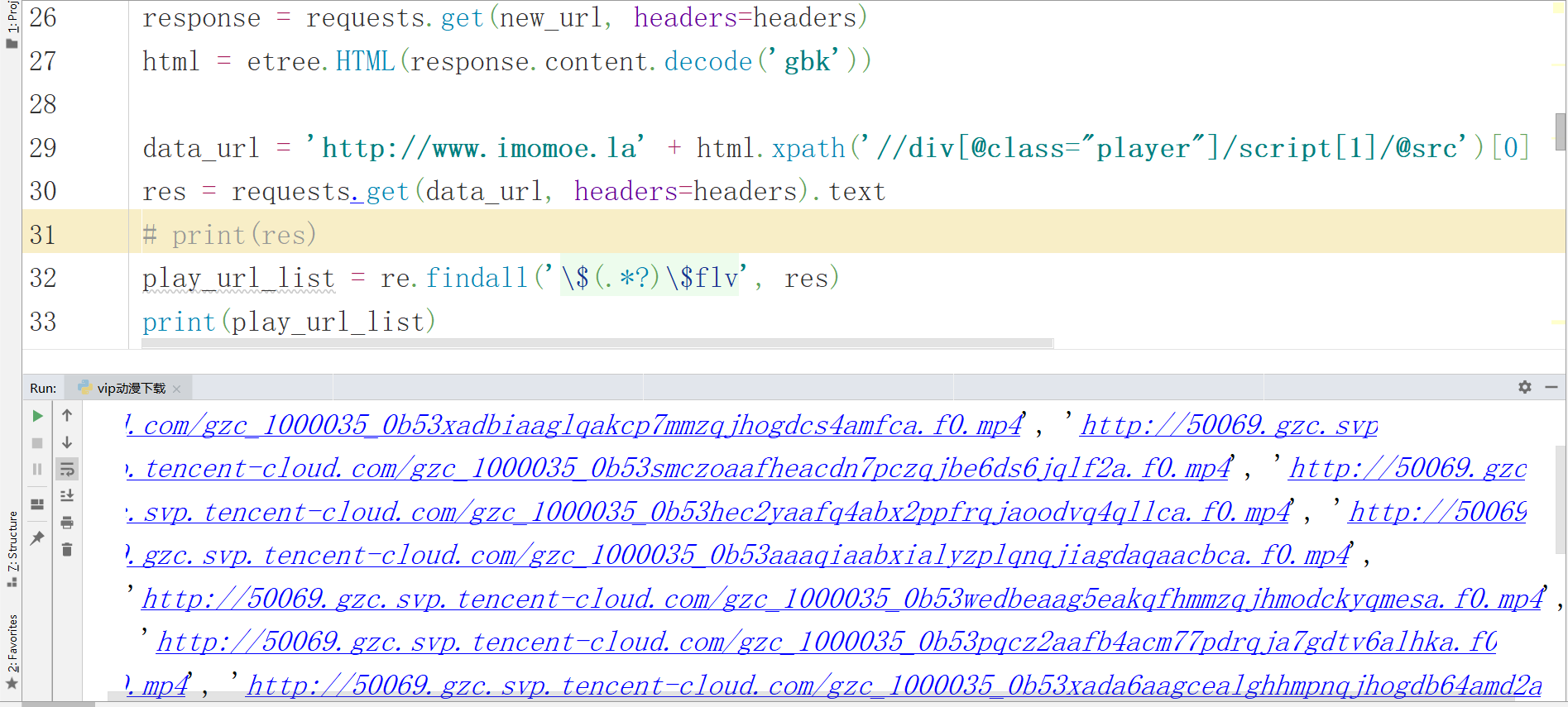
new_url = 'http://www.imomoe.la' + chapter_url_list
response = requests.get(new_url, headers=headers)
html = etree.HTML(response.content.decode('gbk'))
data_url = 'http://www.imomoe.la' + html.xpath('//div[@class="player"]/script[1]/@src')[0]
res = requests.get(data_url, headers=headers).text
# print(res)
play_url_list = re.findall('\$(.*?)\$flv', res)
print(play_url_list)
保存对视频数据发送请求,保存数据到mp4 ,通过tqdm工具能查看对应下载的速度以及下载的进度
for chapter, play_url in tqdm(zip(chapter_list, play_url_list)):
result = requests.get(play_url, headers=headers).content
f = open('终末的女武神/' + chapter + '.mp4', "wb")
f.write(result)
到这大功告成 但是当我把网址修改成斗破苍穹这个动漫时,却返回的数据为空

这个视频的加载数据的规则是不一样的加载的数据为m3u8的格式, 其他的音频的数据加载可能也不一样, 处理m3u8的数据稍稍的有丢丢复杂,它的m3u8的文件内部有嵌套了m3u8链接地址, 需要转换对应的数据接口,进行链接地址拼接, 取出ts文件进行下载,拼接成视频。
m3u8_url_list = re.findall('\$(.*?)\$bdhd', res)
for m3u8_url, chapter in zip(m3u8_url_list, chapter_list):
data = requests.get(m3u8_url, headers=headers)
# print(data.text)
new_m3u8_url = 'https://cdn.605-zy.com/' + re.findall('/(.*?m3u8)', data.text)[0]
# print(new_m3u8_url)
ts_data = requests.get(new_m3u8_url, headers=headers)
ts_url_list = re.findall('/(.*?ts)', ts_data.text)
print("正在下载:", chapter)
for ts_url in tqdm(ts_url_list):
result = requests.get('https://cdn.605-zy.com/' + ts_url).content
f = open('斗破苍穹/' + chapter + '.mp4', "ab")
f.write(result)
项目思路总结
获取到想要动漫的地址
提取详情页面的名字已经跳转地址
获取页面的静态js文件
解析视频播放地址或者m3u8文件
保存对应数据
简易源码分享
import requests
from lxml import etree
import re
from tqdm import tqdm
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Referer': 'http://www.imomoe.la/search.asp'
}
url = 'http://www.imomoe.la/view/8024.html'
response = requests.get(url, headers=headers)
# print(response.content.decode('gbk'))
html_data = etree.HTML(response.content.decode('gbk'))
chapter_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/text()')
chapter_url_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/@href')[0]
# print(chapter_list)
# print(chapter_url_list)
new_url = 'http://www.imomoe.la' + chapter_url_list
response = requests.get(new_url, headers=headers)
html = etree.HTML(response.content.decode('gbk'))
data_url = 'http://www.imomoe.la' + html.xpath('//div[@class="player"]/script[1]/@src')[0]
res = requests.get(data_url, headers=headers).text
# print(res)
play_url_list = re.findall('\$(.*?)\$flv', res)
print(play_url_list)
for chapter, play_url in tqdm(zip(chapter_list, play_url_list)):
result = requests.get(play_url, headers=headers).content
f = open('终末的女武神/' + chapter + '.mp4', "wb")
f.write(result)

发现不会的或者学习Python的,可以直接评论留言或者私我【非常感谢你的点赞、收藏、关注、评论,一键四连支持】

热血动漫番太好看了!用Python爬取了1T的动漫,内存都爆了的更多相关文章
- 这届网友实在是太有才了!用python爬取15万条《我是余欢水》弹幕
年初时我们用数据解读了几部热度高,但评分差强人意的国产剧,而最近正午阳光带着两部新剧来了,<我是余欢水>和<清平乐>,截止到目前为止,这两部剧在豆瓣分别为7.5分和7.9分,算 ...
- Python爬取十四万条书籍信息告诉你哪本网络小说更好看
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TM0831 PS:如有需要Python学习资料的小伙伴可以加点击 ...
- python爬虫09 | 上来,自己动 !这就是 selenium 的牛逼之处
作为一个男人 在最高光的时刻 就是说出那句 之后 还不会被人打 ... 虽然在现实生活中你无法这样 但是在这里 就让你体验一番 那种呼风唤雨的感觉 我们之前在爬取某些网站的时候 使用到了一些 pyth ...
- python爬虫13 | 秒爬,这多线程爬取速度也太猛了,这次就是要让你的爬虫效率杠杠的
快 快了 啊 嘿 小老弟 想啥呢 今天这篇爬虫教程的主题就是一个字 快 想要做到秒爬 就需要知道 什么是多进程 什么是多线程 什么是协程(微线程) 你先去沏杯茶 坐下来 小帅b这就好好给你说道说道 关 ...
- 他爬取了B站所有番剧信息,发现了这些……
本文来自「楼+ 之数据分析与挖掘实战 」第 4 期学员 -- Yueyec 的作业.他爬取了B站上所有的番剧信息,发现了很多有趣的数据- 关键信息:最高播放量 / 最强up主 / 用户追番数据 / 云 ...
- python3爬虫 爬取动漫视频
起因 因为本人家里有时候网速不行,所以看动漫的时候播放器总是一卡一卡的,看的太难受了.闲暇无聊又F12看看.但是动漫网站却无法打开控制台.这就勾起了我的兴趣.正好反正无事,去寻找下视频源. 但是这里事 ...
- Requests库入门——应用实例-网络图片的爬取与保存(好看的小姐姐≧▽≦)
在B站学习这一节的时候,弹幕最为激烈,不管大家是出于什么目的都想体验一下网络爬虫爬取图片的魅力,毕竟之前的实例实话说都是一些没有太大作用的信息. 好了,直接上代码: import requests i ...
- Ajax介绍及爬取哔哩哔哩番剧索引追番人数排行
Ajax,是利用JavaScript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术.简单的说,Ajax使得网页无需刷新即可更新其内容.举个例子,我们用浏览器打开新浪微博 ...
- 爬虫练习四:爬取b站番剧字幕
由于个人经常在空闲时间在b站看些小视频欢乐一下,这次就想到了爬取b站视频的弹幕. 这里就以番剧<我的妹妹不可能那么可爱>第一季为例,抓取这一番剧每一话对应的弹幕. 1. 分析页面 这部番剧 ...
随机推荐
- 使用VS调试时出现 :provider: Named Pipes Provider, error: 40 - 无法打开到 SQL Server 的连接 解决方案
首先检查链接的数据库名称是否正确 其二是看看你的主机名称由没有写对,有些写成 127.0.0.1会出错.我就是将sessionState中的127.0.0.1出错,改为自己的主机名称就OK啦
- js 判断是什么浏览器加载页面
一.Navigator 属性: 1)appcodeName 返回浏览器代码名 2)appminorVersion 返回浏览器次级版本 3)appname 返回浏览器名称 4)browserLan ...
- web自动化页面元素不能键盘输入
一.背景 web自动化中存在一部分元素属性是readonly属性,导致我们在使用自动化代码的时候无法使用sendkeys()方法传入数据,以12306网站选择出发日期为例,见下图 二.json语句处理 ...
- Linux:Linux更新yum方法
[内容指引]进入目录:cd查看目录下的内容:ls重命名备份:mv从网络下载:wgetyum更新:yum update 第一次运行yum安装软件前,建议更新yum. 1.进入yum源目录 命令: cd ...
- 在 Docker 上配置 Oracle
地址:https://github.com/wnameless/docker-oracle-xe-11g .直接 git clone 到本地就行了 ##安装 docker shell 下: docke ...
- swoole实现任务定时自动化调度详解
开发环境 环境:lnmp下进行试验 问题描述 这几天做银行对帐接口时,踩了一个坑,具体需求大致描述一下. 银行每天凌晨后,会开始准备昨天的交易流水数据,需要我们这边请求拿到. 因为他们给的是一个bas ...
- XCTF GAME
首先这题有两种解法,一种是使用ida查看伪代码直接写exp跑出flag,另外一种是调试,因为最近在学调试,刚好用于实战上了. 一.查壳 二.32位文件拖入od动态调试 先找到game的主要函数,插件中 ...
- [zebra源码]分片语句ShardPreparedStatement执行过程
主要过程包括: 分库分表的路由定位 sql语句的 ast 抽象语法树的解析 通过自定义 SQLASTVisitor (MySQLSelectASTVisitor) 遍历sql ast,解析出逻辑表名 ...
- 「AGC032E」 Modulo Pairing
「AGC032E」 Modulo Pairing 传送门 如果所有数都 \(<\lfloor \frac m 2\rfloor\),一个自然的想法是对所有数排序过后大小搭配,这样显然是最优秀的. ...
- 「POJ3436」ACM Computer Factory题解
题意: 有很多台机器,可以把物件从一种状态改装成另一种状态,初始全为\(0\),最终状态全为\(1\),让你可以拼凑机器,请问最大总性能为多少,且要求输出方案. 题解: 这道题是真的水啊,我不想写太多 ...