EXCEL:关键字有重复,其他信息一行多列显示
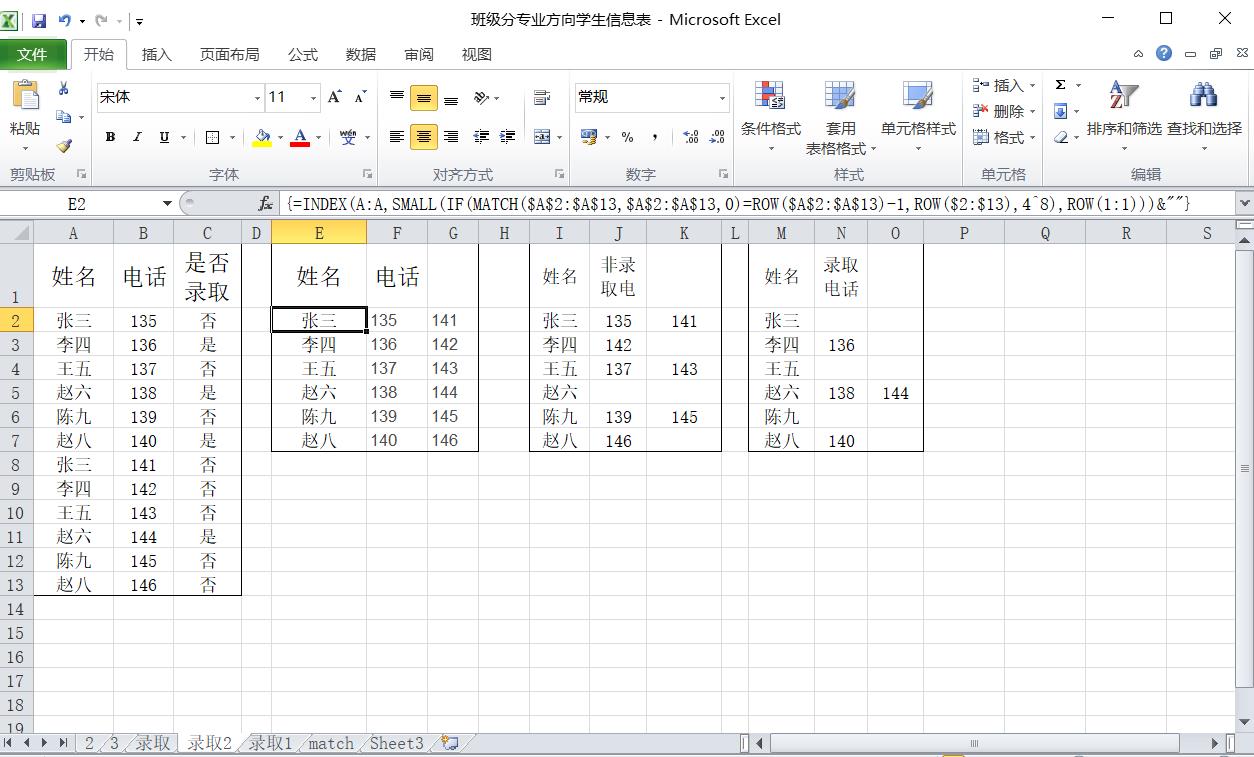
=INDEX(A:A,SMALL(IF(MATCH($A$2:$A$13,$A$2:$A$13,0)=ROW($A$2:$A$13)-1,ROW($2:$13),4^8),ROW(1:1)))&""
=INDEX($B:$B,SMALL(IF($A$2:$A$13=$E2,ROW($A$2:$A$13),4^8),COLUMN(A1)))&""
=INDEX($B:$B,SMALL(IF(($A$2:$A$13=$E2)*($c$2:$c$13="否"),ROW($A$2:$A$13),4^8),COLUMN(A1)))&""
按ctrl+shift+enter结束
EXCEL中如果公式很长,在编辑栏中选择公式一部分,按F9可得到选择部分公式的结果
公式一分析:
=INDEX(A:A,SMALL(IF(MATCH($A$2:$A$13,$A$2:$A$13,0)=ROW($A$2:$A$13)-1,ROW($2:$13),4^8),ROW(1:1)))&""
ROW($2:$13):显示区域对应的行号{2;3;4;5;6;7;8;9;10;11;12;13}
ROW($2:$13)-1:显示区域对应的行号{1;2;3;4;5;6;7;8;9;10;11;12}
MATCH($A$2:$A$13,$A$2:$A$13,0):精确匹配在区域A2:A13匹配a2的值,得到所在最行的最行号(除首行),
以a2‘张三’为例,其实际分别在第2行,结果为1
以a8‘张三’为例,其实际分别在第8行,结果为2
4^8=65536(特别大的数)
if()条件判断,第二行的‘张三’时1等于1成立,所以取row($a$2:$a$13)-1=1
第三行的“李四”时2等于2成立,所以取row($a$2:$a$13)-1=2
第四行的“王五”时2等于2成立,所以取row($a$2:$a$13)-1=3
第五行的“赵六”时2等于2成立,所以取row($a$2:$a$13)-1=4
第六行的“陈九”时2等于2成立,所以取row($a$2:$a$13)-1=5
第七行的“赵八”时2等于2成立,所以取row($a$2:$a$13)-1=6
第八行的‘张三’时1等于1成立,所以取row($a$2:$a$13)-1=65536
第九行的“李四”时2等于2成立,所以取row($a$2:$a$13)-1=65536
第十行的“王五”时2等于2成立,所以取row($a$2:$a$13)-1=65536
第11行的“赵六”时2等于2成立,所以取row($a$2:$a$13)-1=65536
第12行的“陈九”时2等于2成立,所以取row($a$2:$a$13)-1=65536
第13行的“赵八”时2等于2成立,所以取row($a$2:$a$13)-1=65536
small()取最小值,所以'张三'结果为1,依次类推,李四 王五 赵六 陈九 赵八分别为1,2,3,4,5,6
index()依次取第一种名字’张三‘,再取第二种名字‘李四’。依次类推,分别为'李四 王五 赵六 陈九 赵八’
公式2分析:
=INDEX($B:$B,SMALL(IF($A$2:$A$13=$E2,ROW($A$2:$A$13),4^8),COLUMN(A1)))&""
根据公式1的分析,该公式就是从B列查找相应的数据
公式3分析:
=INDEX($B:$B,SMALL(IF(($A$2:$A$13=$E2)*($c$2:$c$13="否"),ROW($A$2:$A$13),4^8),COLUMN(A1)))&""
实际增加了条件$c$2:$c$13="否" 或$c$2:$c$13="是"
EXCEL:关键字有重复,其他信息一行多列显示的更多相关文章
- python 去除Excel中的重复行数据
导入pandas import pandas as pd 1.读取excel中的数据: frame = pd.DataFrame(pd.read_csv('excel的绝对路径.csv'', 'She ...
- 怎样去除EXCEL中的重复行
工具/原料 安装了EXCEL2010的电脑一台 步骤/方法 假如我们的表格中有下图所示的一系列数据,可以看出其中有一些重复. 首先我们选中所有数据.可以先用鼠标点击"A1单元格&qu ...
- Python:读取txt中按列分布的数据,并将结果保存在Excel文件中 && 保存每一行的元素为list
import xlwt import os def write_excel(words,filename): #写入Excel的函数,words是数据,filename是文件名 wb=xlwt.Wor ...
- Excel 表格查找重复数据,去重复统计
找出表格是否有重复数据: =IF(AND(G20=G19,D20=D19),"是","否") 筛选移除[重复的数据]然后开始统计 =SUBTOTAL(9,E2: ...
- EXCEL统计不重复值的数量
如这一列中,有多少不重复值? 1.可以点击,数据,删除重复项,清除重复值,然后剩下的统计一下即可知道: ===> 2.用公式:=SUMPRODUCT((MATCH(E3:E20,E3 ...
- 【Excel】删除重复值
- Excel如何查找名字重复的数据
来源于:http://jingyan.baidu.com/article/414eccf6091ff86b431f0aec.html Cokery今天在帮助同事整理数据的时候遇到了一个难题,就是在Ex ...
- 检验Excel中数据是否与数据库中数据重复
#region 记录Excel中的重复列 /// <summary> /// 记录Excel中的重复列 /// </summary> /// <param name=&q ...
- MySql避免重复插入记录
今天用python抓取数据入库需要避免重复数据插入,在网上找了一些方法: 方案一:使用ignore关键字 如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用 ...
随机推荐
- TheSuperego 实验六 团队作业3:项目需求分析与原型设计
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 团队名称 TheSuperego 团队成员分工描述 杨丽霞:组织QQ会议,合理明确组内分工,推进任务,实施关于我们原型设计陈来弟:负 ...
- Volatile 原理及使用,java并发中的可见性问题
1.解决并发编程中的可见性问题 volatile 代表不使用cpu缓存,修改后的数据,将直接刷到内存中,被volatile修饰的变量,读取的时候,也是从内存中读取,不从cpu缓存中读取 上代码 // ...
- 将TVM集成到PyTorch
将TVM集成到PyTorch 随着TVM不断展示出对深度学习执行效率的改进,很明显PyTorch将从直接利用编译器堆栈中受益.PyTorch的主要宗旨是提供无缝且强大的集成,而这不会妨碍用户.PyTo ...
- deeplearning模型分析
deeplearning模型分析 FLOPs paddleslim.analysis.flops(program, detail=False) 获得指定网络的浮点运算次数(FLOPs). 参数: pr ...
- 在Yolov5 Yolov4 Yolov3 TensorRT 实现Implementation
在Yolov5 Yolov4 Yolov3 TensorRT 实现Implementation news: yolov5 support 引论 该项目是nvidia官方yolo-tensorrt的封装 ...
- java后端知识点梳理——MySQL
MySQL的索引 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息,就像一本书的目录一样,可以加快查询速度.InnoDB 存储引擎的索引模型底层实现数据结构为 ...
- React开发中react-route-dom使用BrowserRouter部署到服务器上刷新时报404的问题
React项目部署中遇到的问题 react开发中react-route使用BrowserRoute路径在iis服务器上刷新时报404的问题 解决:在发布的项目根目录添加web.config配置文件 在 ...
- 史上最详细的Air7xx驱动安装教程
由于Air7xx系列4G模块需要安装USB驱动,但是很多开发者对USB驱动的安装方法不是十分了解,所以经常出现问题,导致安装失败.特书此文,手把手教你装USB驱动. 第一步 从官网下载最新的驱动程序 ...
- xshell连接时报错:Could not connect to '192.168.2.125' (port 22): Connection failed.
解决思路: 1.首先用主机ping下虚拟机IP,看是否能ping通 2.如果ping不通就看虚拟机防火墙是否开启,service iptables status [root@mysql ~]# ser ...
- 解决java socket在传输汉字时出现截断导致乱码的问题
解决java socket在传输汉字时出现截断导致乱码的问题 当使用socket进行TCP数据传输时,传输的字符串会编码成字节数组,当采用utf8编码时,数字与字母长度为1个字节,而汉字一般为3个字节 ...