Linux性能优化实战CPU篇之总结(四)
一、分析CPU瓶颈
1,性能指标
a>CPU使用率
CPU使用率描述了非空闲时间占总CPU时间的百分比,根据CPU上运行任务的不同可以分为:用户CPU、系统CPU、等待I/O CPU、软中断和硬中断等
- 用户CPU使用率,包括用户态CPU使用率(user)和低优先级用户态CPU使用率(nice),表示CPU在用户态运行的时间百分比。用户CPU使用率高,通常说明有应用程序比较繁忙
- 系统CPU使用率,表示CPU在内核态运行的时间百分比(不包括中断)。系统CPU使用率高,说明内核比较繁忙
- 等待I/O的CPU使用率,通常也称之为iowait,表示等待I/O的时间百分比。iowait高,通常说明系统与硬件设备的I/O交互时间比较长。
- 软中断和硬中断的CPU使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断
- 窃取CPU使用率(steal)和客户CPU使用率(guest),分别表示被其他虚拟机占用的CPU时间百分比和运行客户虚拟机的CPU时间百分比
b>平均负载
系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去1分钟、过去5分钟和过去15分钟的平均负载。
理想情况下,平均负载等于逻辑CPU个数,这表示每个CPU都恰好被充分利用。如果平均负载大于逻辑CPU个数,就表示负载比较重。
c>上下文切换
- 无法获取资源而导致的自愿上下文切换
- 被系统强制调度导致的非自愿上下文切换
上下文切换,本身是保证Linux正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的CPU时间,消耗寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
d>CPU的缓存命中率
https://cloud.tencent.com/developer/article/1597149
CPU的处理速度要比内存的访问速度快很多,CPU在访问内存的时候,就需要等待内存的响应。为了协调二者的巨大性能差距,CPU缓存(多级缓存)就出现了
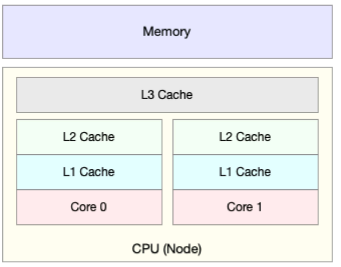
CPU缓存的速度介于CPU和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为L1、L2、L3等三级缓存,其中L1和L2常用在单核中,L3则用在多核中。
从L1到L3,三级缓存的大小依次增大,相应的性能依次降低(当然比内存好很多)。而它们的命中率,衡量的是CPU缓存的复用情况,命中率越高,则表示性能越好。
2,性能工具
a>平均负载
uptime查看系统的平均负载。在平均负载升高时,使用mpstat和pidstat,分别观察每个CPU和每个进程CPU的使用情况,进而定位负载升高的进程
b>上下文切换
vmstat查看系统的上下文切换次数和中断次数。使用pidstat (-w),观察进程的自愿上下文切换(cswch/s)和非自愿上下文切换(nvcswch/s);使用pidstat(-wt)输出具体线程的上下文切换。
c>CPU使用率升高
使用top观察具体的CPU情况,然后使用perf工具定位具体的线程和函数
d>不可中断进程和僵尸进程
top观察iowait升高,并发现出现大量的zombie僵尸进程,使用dstat定位为磁盘读取导致,再使用pidstat找出相关进程,最后用perf工具定位原因
e>软中断
top观察cpu使用率升高,再使用watch -d /proc/softirqs,找到变化速率较快的软中断,然后通过sar(-n DEV)显示网络收发的报告,发现为网络小包问题,最后用tcpdump,找到网络帧的类型和来源,确定为SYNFLOOD攻击导致。
3,性能指标和性能工具关联
a>根据指标找工具
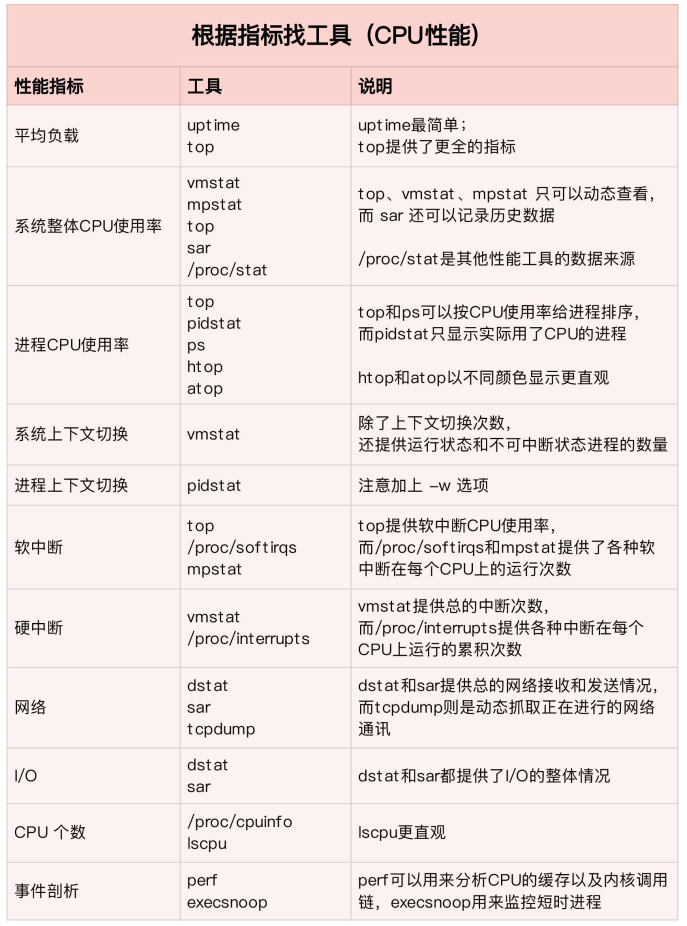
b>根据工具查指标
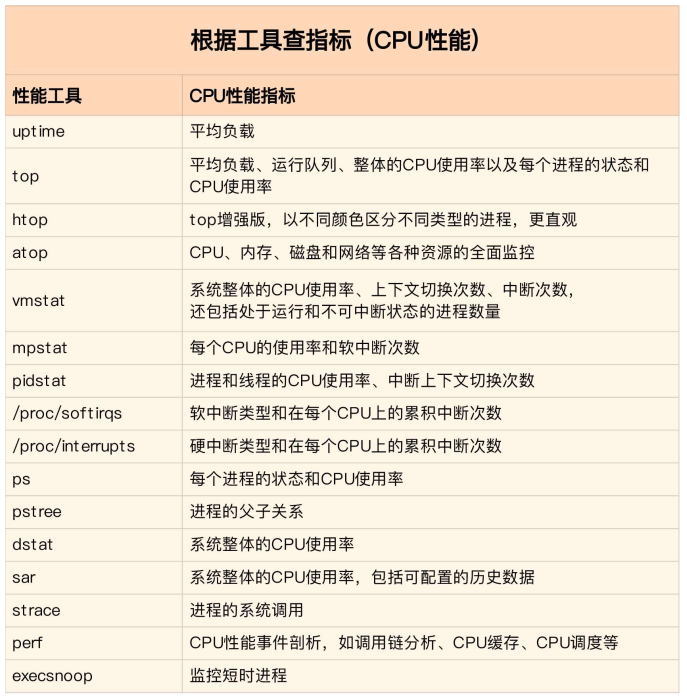
c>分析CPU性能瓶颈
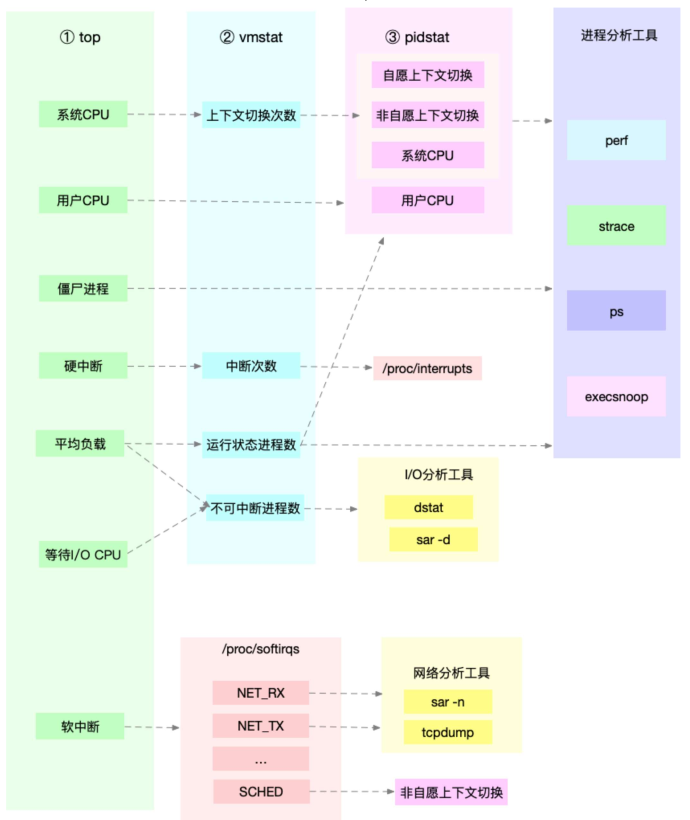
二、CPU性能优化的思路
1,如何评估性能优化效果
a>确定性能的量化指标
不要局限在单一维度的指标上。以web项目为例:
- 应用程序的维度,可以用吞吐量和请求延迟来评估应用程序的性能
- 系统资源的维度,可以用CPU使用率来评估系统的CPU使用情况
b>测试优化前的性能指标
c>测试优化后的性能指标
2,CPU优化
a>应用程序优化
降低CPU使用率的最好方法是排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等。
除此之外,应用程序的优化也包括很多方法,最常用的:
- 编译器优化:很多编译器都会提供优化选项,适当开启。比如,gcc就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用O(nlogn)的排序算法(如快排、归并排序等),代替O(n^2)的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费CPU的问题。
- 多线程代替多进程:相对于进程上下文切换, 线程上下文切换并不切换进程选址空间,因此可以降低上下文切换的成本
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
b>系统优化
从系统的角度来说,优化CPU的运行,一方面要充分利用CPU缓存的本地性,加速缓存访问;另一方面,就是要控制进程的CPU使用情况,减少进程间的相互影响。常见方法:
- CPU绑定:把进程绑定到一个或者多个CPU上,可以提高CPU缓存的命中率,减少跨CPU调度带来的上下文切换问题
- CPU独占:跟CPU绑定类似,进一步将CPU分组,并通过CPU亲和性机制为其分配进程。这样,这些CPU就由指定的进程独占,换句话说,不允许其他进程再来使用这些CPU。
- 优先级调整:使用nice调整进程的优先级,正值调低优先级,负值调高优先级。适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用Linux cgroups 来设置进程的CPU使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源
- NUMA(Non-Uniform Memory Accesss)优化:支持NUMA的处理器会被划分为多个node,每个node都有自己的本地内存空间。NUMA优化,其实就是让CPU尽可能只访问本地内存。
- 中断负载均衡:无论软中断还是硬中断,它们的中断处理程序都可能会耗费大量的CPU。开启irqbalance服务或者配置smp_affinity,就可以吧中断处理过程自动负载均衡到多个CPU上。
Linux性能优化实战CPU篇之总结(四)的更多相关文章
- Linux性能优化实战CPU篇之软中断(三)
一.软中断 1,中断的定义 a>定义 举例:你点了一份外卖,在无法获知外卖进度的情况下,配送员送外卖是不等人的,到了发现没人取会直接走,所以你只能苦苦等着,时不时去门口看送到没有,无法干别的事情 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战内存篇(五)
一.Linux内存工作原理 1,内存映射 Linux内核给每个进程都提供了一个独立的虚拟空间,并且这个地址空间是连续的.这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存. 虚拟地址空间的内部 ...
- Linux性能优化实战学习笔记:第四十六讲
一.上节回顾 不知不觉,我们已经学完了整个专栏的四大基础模块,即 CPU.内存.文件系统和磁盘 I/O.以及网络的性能分析和优化.相信你已经掌握了这些基础模块的基本分析.定位思路,并熟悉了相关的优化方 ...
- Linux性能优化实战学习笔记:第四十讲
一.上节回顾 上一节,我们学习了碰到分布式拒绝服务(DDoS)的缓解方法.简单回顾一下,DDoS利用大量的伪造请求,导致目标服务要耗费大量资源,来处理这些无效请求,进而无法正常响应正常用户的请求. 由 ...
- Linux性能优化实战学习笔记:第四十七讲
一.上节回顾 上一节,我们梳理了,应用程序容器化后性能下降的分析方法.一起先简单回顾下.容器利用 Linux 内核提供的命名空间技术,将不同应用程序的运行隔离起来,并用统一的镜像,来管理应用程序的依赖 ...
- Linux性能优化实战学习笔记:第四十二讲
一.上节回顾 上一节,我们学习了 NAT 的原理,明白了如何在 Linux 中管理 NAT 规则.先来简单复习一下. NAT 技术能够重写 IP 数据包的源 IP 或目的 IP,所以普遍用来解决公网 ...
随机推荐
- 【记录一个问题】cv::cuda::BufferPool发生assert错误
cv::cuda::setBufferPoolUsage(true); const int width = 512; const int height = 848; const int channel ...
- Windows系统安装和office版本兼容
MSDN, I tell you 下载windows10系统各种纯净镜像.但是还是推荐使用官网修改参数显示出下载链接,下载windows10最新版. 在最近几次重做系统中,PE工具似乎无法识别从MSD ...
- 外观模式(Facade模式)
外观模式的定义与特点 外观(Facade)模式又叫作门面模式,是一种通过为多个复杂的子系统提供一个一致的接口,而使这些子系统更加容易被访问的模式.该模式对外有一个统一接口,外部应用程序不用关心内部子系 ...
- postgresql安装(windows)
官网: https://www.postgresql.org/ 下载页面:https://www.enterprisedb.com/downloads/postgres-postgresql-down ...
- Ubuntu 14.04更换内核
1:查看当前安装的内核 dpkg -l|grep linux-image 2:查看可以更新的内核版本: sudo apt-cache search linux-image 3:安装新内核 sudo a ...
- 前端基础之CSS(浮动-解决溢出-实现个人头像框)
目录 一:浮动float 1.什么是浮动? 2.浮动的作用 3.浮动有两个特点 4.float格式 二:代码实现左右浮动边框 三:浮动造成父标签塌陷问题(清除浮动) 1.浮动会造成父标签的影响 三:清 ...
- 操作系统的发展史(并发与并行)<异步与同步>《进程与程序》[非堵塞与堵塞]
目录 一:一:手工操作 -- 穿孔卡片 1.简介 二:手工操作方式两个特点: 三:批处理 -- 磁带存储 1.联机批处理系统 2.脱机批处理系统 3.多道程序系统 4.多道批处理系统 四:总结发展史 ...
- 幸运转轮(Cakra)
题目描述 lxx参加了某卫视举办的一场选秀节目,凭借曼妙的舞姿和动人的歌声,他在众多idol中脱颖而出.现在在他的面前,有四个大转轮,这四个转轮将决定他能否赢得最终大奖--出道,机会只有一次! 每 ...
- Python 序列类型小结
序列是python中最基本的数据结构. 序列中每一个元素都有其对应的索引,索引是从0开始,0,1,2......依次类推 python中的序列类型有:字符串str.列表list.元组tuple.Uni ...
- 随机UA
from fake_useragent import UserAgent ua = UserAgent().random headers={ 'User-Agent':ua } print(heade ...