Java同步之线程池详解
带着问题阅读
1、什么是池化,池化能带来什么好处
2、如何设计一个资源池
3、Java的线程池如何使用,Java提供了哪些内置线程池
4、线程池使用有哪些注意事项
池化技术
池化思想介绍
池化思想是将重量级资源预先准备好,在使用时可重复使用这些预先准备好的资源。
池化思想的核心概念有:
- 资源创建/销毁开销大
- 提前创建,集中管理
- 重复利用,资源可回收
例如大街上的共享单车,用户扫码开锁,使用完后归还到停放点,下一个用户可以继续使用,共享单车由厂商统一管理,为用户节省了购买单车的开销。
池化技术的应用
常见的池化技术应用有:资源池、连接池、线程池等。
资源池
在各种电商平台大促活动时,平台需要支撑平时几十倍的流量,因此各大平台在需要提前准备大量服务器进行扩容,在活动完毕以后,扩容的服务器资源又白白浪费。将计算资源池化,在业务高峰前进行分配,高峰结束后提供给其他业务或用户使用,即可节省大量消耗,资源池化也是云计算的核心技术之一。
连接池
网络连接的建立和释放也是一个开销较大的过程,提前在服务器之间建立好连接,在需要使用的时候从连接池中获取,使用完毕后归还连接池,以供其他请求使用,以此可节省掉大量的网络连接时间,如数据库连接池、HttpClient连接池。
线程池
线程的建立销毁都涉及到内核态切换,提前创建若干数量的线程提供给客户端复用,可节约大量的CPU消耗以便处理业务逻辑。线程池也是接下来重点要讲的内容。
如何设计一个线程池
设计一个线程池,至少需要提供的核心能力有:
- 线程池容器:用于容纳初始化时预先创建的线程。
- 线程状态管理:管理池内线程的生命周期,记录每个线程当前的可服务状态。
- 线程请求管理:对调用端提供获取和归还线程的接口。
- 线程耗尽策略:提供策略以处理线程耗尽问题,如拒绝服务、扩容线程池、排队等待等。
基于以上角度,我们来分析Java是如何设计线程池功能的。
Java线程池解析
ThreadPoolExecutor使用介绍
大象装冰箱总共分几步
// 1.创建线程池
ThreadPoolExecutor threadPool =
new ThreadPoolExecutor(1, 1, 1L, TimeUnit.MINUTES, new LinkedBlockingQueue<>());
// 2.提交任务
threadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println("task running");
}
}});
// 3.关闭线程池
threadPool.shutDown();
Java通过ThreadPoolExecutor提供线程池的实现,如示例代码,初始化一个容量为1的线程池、然后提交任务、最后关闭线程池。
ThreadPoolExecutor的核心方法主要有
构造函数:
ThreadPoolExecutor提供了多个构造函数,以下对基础构造函数进行说明。public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:线程池的核心线程数。池内线程数小于
corePoolSize时,线程池会创建新线程执行任务。maximumPoolSize:线程池的最大线程数。池内线程数大于
corePoolSize且workQueue任务等待队列已满时,线程池会创建新线程执行队列中的任务,直到线程数达到maximumPoolSize为止。keepAliveTime:非核心线程的存活时长。池内超过
corePoolSize数量的线程可存活的时长。unit:非核心线程存活时长单位。与
keepAliveTime取值配合,如示例代码表示1分钟。workQueue:任务提交队列。当无空闲核心线程时,存储待执行任务。
类型 作用 ArrayBlockingQueue 数组结构的有界阻塞队列 LinkedBlockingQueue 链表结构的阻塞队列,可设定是否有界 SynchronousQueue 不存储元素的阻塞队列,直接将任务提交给线程池执行 PriorityBlockingQueue 支持优先级的无界阻塞队列 DelayQueue 支持延时执行的无界阻塞队列 threadFactory:线程工厂。用于创建线程对象。
handler:拒绝策略。线程池线程数量达到
maximumPoolSize且workQueue已满时的处理策略。类型 作用 AbortPolicy 拒绝并抛出异常。默认 CallerRunsPolicy 由提交任务的线程执行任务 DiscardOldestPolicy 抛弃队列头部任务 DiscardPolicy 抛弃该任务
执行函数:
execute和submit,主要分别用于执行Runnable和Callable。// 提交Runnable
void execute(Runnable command); // 提交Callable并返回Future
<T> Future<T> submit(Callable<T> task); // 提交Runnable,执行结束后Future.get会返回result
<T> Future<T> submit(Runnable task, T result); // 提交Runnable,执行结束后Future.get会返回null
Future<?> submit(Runnable task);
停止函数:
shutDown和shutDownNow。// 不再接收新任务,等待剩余任务执行完毕后停止线程池
void shutdown(); // 不再接收新任务,并尝试中断执行中的任务,返回还在等待队列中的任务列表
List<Runnable> shutdownNow();
内置线程池使用
To be useful across a wide range of contexts, this class provieds many adjustable parameters and extensibility hooks. However, programmers are urged to use the more convenient {@link Executors} factory methods {@link Executors#newCachedThreadPool} (unbounded thread poll, with automatic thread reclamation), {@link Executors#newFixedThreadPool} (fixed size thread pool) and {@link Executors#newSingleThreadExecutor}(single background thread), that preconfigure settings for the most common usage scenarios.
由于ThreadPoolExecutor参数复杂,Java提供了三种内置线程池newCachedThreadPool、newFixedThreadPool和newSingleThreadExecutor应对大多数场景。
Executors.newCachedThreadPool()无界线程池,核心线程池大小为0,最大为Integer.MAX_VALUE,因此严格来讲并不算无界。采用SynchronousQueue作workQueue,意味着任务不会被阻塞保存在队列,而是直接递交到线程池,如线程池无可用线程,则创建新线程执行。public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Executors.newFixedThreadPool(int nThreads)固定大小线程池,其中coreSize和maxSize相等,且过期时间为0,表示经过一定数量任务提交后,线程池将始终维持在nThreads数量大小,不会新增也不会回收线程。public static ExecutorService new FixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads nThreads, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
Executors.newSingleThreadExecutor()单线程池,参数与fixedThreadPool类似,只是将数量限制在1,单线程池主要避免重复创建销毁线程对象,也可用于串行化执行任务。不同与其他线程池,单线程池采用FinallizableDelegatedExecutorService对ThreadPoolExecutor对象进行包装,感兴趣的同学可以看下源码,其方法实现仅仅是对被包装对象方法的直接调用。包装对象主要用于避免用户将线程池强制转换为ThreadPoolExecutor来修改线程池大小。public static ExecutorService newSingleThreadExecutor() {
return new FinallizableDelegatedExecutorService(
(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockQueue<Runnable>()))
);
}
ThreadPoolExecutor解析
整体设计
ThreadPoolExecutor基于ExecutorService接口实现提交任务,未采取常规资源池获取/归还资源的形式,整个线程池和线程的生命周期都由ThreadPoolExecutor进行管理,线程对象不对外暴露;ThreadPoolExecutor的任务管理机制类似于生产者消费者模型,其内部维护一个任务队列和消费者,一般情况下,任务被提交到队列中,消费线程从队列中拉取任务并将其执行。
线程池生命周期
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态
private static int workerCountOf(int c) { return c & CAPACITY; } //计算当前线程数量
private static int ctlOf(int rs, int wc) { return rs | wc; } //通过状态和线程数生成ctl
TreadPoolExecutor通过ctl维护线程池的状态和线程数量,其中高3位存储运行状态,低29位存储线程数量。
位运算操作推荐参考第三篇文章。
线程池设定了RUNNING、SHUTDOWN、STOP、TIDYING和TERMINATED五种状态,其转移图如下:
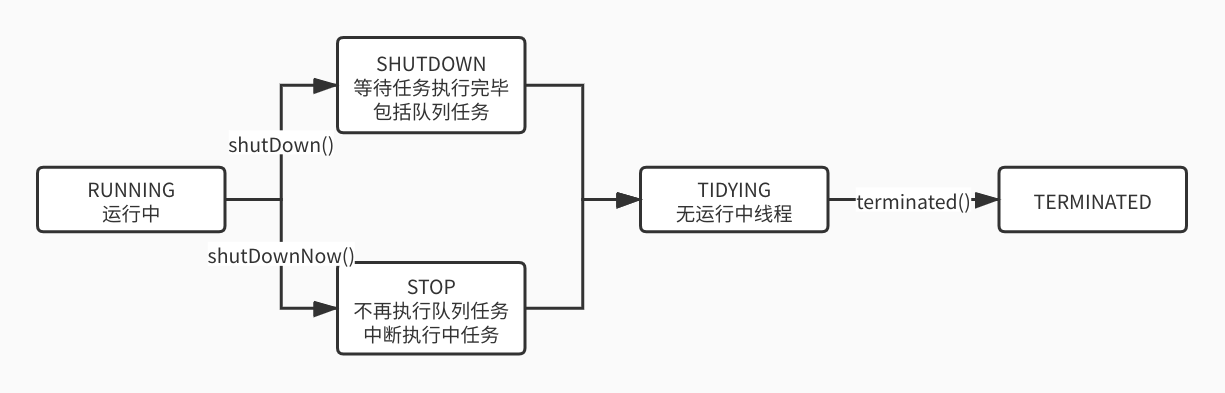
在这5种状态中,只有RUNNING时线程池可接收新任务,其余4种状态在调用shutDown或shutDownNow后触发转换,且在这4种状态时,线程池均不再接收新任务。
任务管理解析
// 用于存放提交任务的队列
private final BlockingQueue<Runnable> workQueue;
// 用于保存池内的工作线程,Java将Thread包装成Worker存储
private final HashSet<Worder> workers = new HashSet<Worker>();
ThreadPoolExecutor主要通过workQueue和workers两个字段用于管理和执行任务。
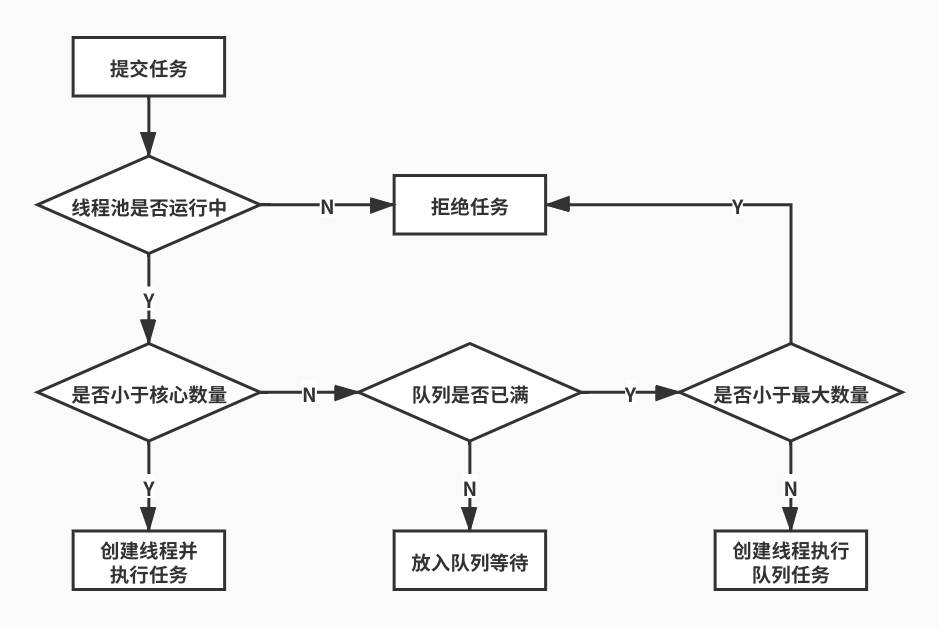
线程池任务执行流程如图,结合ThreadPoolExecutor.execute源码,对任务执行流程进行说明:
当任务提交到线程池时,如果当前线程数量小于核心线程数,则会将为该任务直接创建一个
worker并将任务交由worker执行。if (workerCountOf(c) < corePoolSize) {
// 创建新worker执行任务,true表示核心线程
if (addWorker(command, true))
return;
c = ctl.get();
}
当已经达到核心线程数后,任务会提交到队列保存;
// 放入workQueue队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 这里采用double check再次检测线程池状态
if (! isRunning(recheck) && remove(command))
reject(command);
// 避免加入队列后,所有worker都已被回收无可用线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
如果队列已满,则依据最大线程数量创建新
worker执行。如果新增worker失败,则依据设定策略拒绝任务。// 接上,放入队列失败
// 添加新worker执行任务,false表示非核心线程
else if (!addWorker(command, false))
// 如添加失败,执行拒绝策略
reject(command);
woker对象
ThreadPoolExecutor没有直接使用Thread记录线程,而是定义了worker用于包装线程对象。
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
...
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
// worker对象被创建后就会执行
public void run() {
runWorker(this);
}
}
worker对象通过addWorker方法创建,一般会为其指定一个初始任务firstTask,当worker执行完毕以后,worker会从阻塞队列中读取任务,如果没有任务,则该worker会陷入阻塞状态给出worker的核心逻辑代码:
private boolean addWorker(Runnable firstTask, boolean core) {
...
// 指定firstTask,可能为null
w = new Worker(firstTask);
...
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
workerAdded = true;
}
...
// 执行新添加的worker
if (workerAdded) {
t.start();
workerStarted = true;
}
}
final void runWorker(Worker w) {
// 等待workQueue的任务
while (task != null || (task = getTask()) != null) {
...
}
}
private Runnable getTask() {
...
for (;;) {
...
// 如果是普通工作线程,则根据线程存活时间读取阻塞队列
// 如果是核心工作线程,则直接陷入阻塞状态,等待workQueue获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
...
}
}
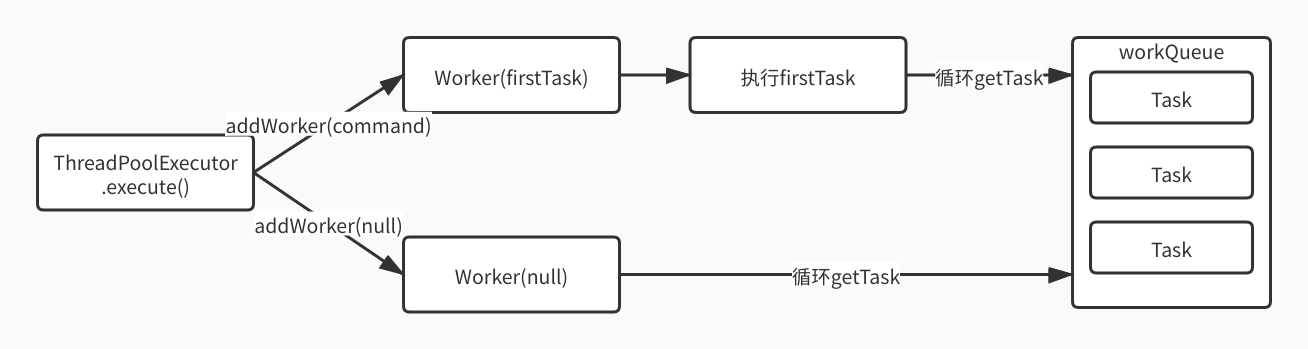
如下图,任务提交后触发addWorker创建worker对象,该对象执行任务完毕后,则循环获取队列中任务等待执行。
Java线程池实践建议
不建议使用Exectuors
线程池不允许使用
Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。《阿里巴巴开发手册》
虽然Java推荐开发者直接使用Executors提供的线程池,但实际开发中通常不使用。主要考虑问题有:
潜在的OOM问题
CachedThreadPool将最大数量设置为Integer.MAX_VALUE,如果一直提交任务,可能造成Thread对象过多引起OOM。FixedThreadPool和SingleThreadPoo的队列LinkedBlockingQueue无容量限制,阻塞任务过多也可能造成OOM。线程问题定位不便
由于未指定
ThreadFactory,线程名称默认为pool-poolNumber-thread-thredNumber,线程出现问题后不便定位具体线程池。线程池分散
通常在完善的项目中,由于线程是重量资源,因此线程池由统一模块管理,重复创建线程池容易造成资源分散,难以管理。
线程池大小设置
通常按照IO繁忙型和CPU繁忙型任务分别采用以下两个普遍公式。
\\
N_{thread} = N_{cpu} + 1
\]
在理论场景中,如一个任务IO耗时40ms,CPU耗时10ms,那么在IO处理期间,CPU是空闲的,此时还可以处理4个任务(40/10),因此理论上可以按照IO和CPU的时间消耗比设定线程池大小。
\\
N_{thread} = (Ratio + 1) * N_{cpu}
\]
《JAVA并发编程实践》中还考虑数量乘以目标CPU的利用率
在实际场景中,我们通常无法准确测算IO和CPU的耗时占比,并且随着流量变化,任务的耗时占比也不能固定。因此可根据业务需求,开设线程池运维接口,根据线上指标动态调整线程池参数。
推荐参考第二篇美团线程池应用
线程池监控
ThreadPoolExecutor提供以下方法监控线程池:
getTaskCount()返回被调度过的任务数量getCompletedTaskCount()返回完成的任务数量getPoolSize()返回当前线程池线程数量getActiveCount()返回活跃线程数量getQueue()获取队列,一般用于监控阻塞任务数量和队列空间大小
参考
《Java并发编程实践》
Java同步之线程池详解的更多相关文章
- Java多线程之线程池详解
前言 在认识线程池之前,我们需要使用线程就去创建一个线程,但是我们会发现有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因 ...
- Java 并发编程 | 线程池详解
原文: https://chenmingyu.top/concurrent-threadpool/ 线程池 线程池用来处理异步任务或者并发执行的任务 优点: 重复利用已创建的线程,减少创建和销毁线程造 ...
- Java线程池详解(二)
一.前言 在总结了线程池的一些原理及实现细节之后,产出了一篇文章:Java线程池详解(一),后面的(一)是在本文出现之后加上的,而本文就成了(二).因为在写完第一篇关于java线程池的文章之后,越发觉 ...
- 三、VIP课程:并发编程专题->01-并发编程之Executor线程池详解
01-并发编程之Executor线程池详解 线程:什么是线程&多线程 线程:线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系 ...
- nginx源码分析线程池详解
nginx源码分析线程池详解 一.前言 nginx是采用多进程模型,master和worker之间主要通过pipe管道的方式进行通信,多进程的优势就在于各个进程互不影响.但是经常会有人问道,n ...
- Java线程池详解
一.线程池初探 所谓线程池,就是将多个线程放在一个池子里面(所谓池化技术),然后需要线程的时候不是创建一个线程,而是从线程池里面获取一个可用的线程,然后执行我们的任务.线程池的关键在于它为我们管理了多 ...
- Java线程池详解(一)
一.线程池初探 所谓线程池,就是将多个线程放在一个池子里面(所谓池化技术),然后需要线程的时候不是创建一个线程,而是从线程池里面获取一个可用的线程,然后执行我们的任务.线程池的关键在于它为我们管理了多 ...
- java多线程、线程池及Spring配置线程池详解
1.java中为什么要使用多线程使用多线程,可以把一些大任务分解成多个小任务来执行,多个小任务之间互不影像,同时进行,这样,充分利用了cpu资源.2.java中简单的实现多线程的方式 继承Thread ...
- Java线程池详解,看这篇就够了!
构造一个线程池为什么需要几个参数?如果避免线程池出现OOM?Runnable和Callable的区别是什么?本文将对这些问题一一解答,同时还将给出使用线程池的常见场景和代码片段. 基础知识 Execu ...
随机推荐
- 【洛谷P1140 相似基因】动态规划
分析 f[i][j] 表示 1数组的第i位和2数组的第j位匹配的最大值 f[1][1]=-2 f[2][1]=-2+5=3 f[3][1]=-2+5+5=8 三个决策: 1.由f[i-1][j-1]直 ...
- mysql为什么用b+树做索引
关键字就是key的意思 一.B-Tree的性质 1.定义任意非叶子结点最多只有M个儿子,且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点的儿子数为[M/2, M]: ...
- 承载童年的游戏机,已停产!但我在 GitHub 找到了它们
那些年,上网用的是电话线,小企鹅也只会笨拙地左右摇晃,手机还只是打电话的工具.虽然那些年没有互联网,但游戏机承载了我的童年. 小时候我老是追着我的两个哥哥,他们带我玩了好多种游戏机,比如街机.红白机. ...
- Mybatis学习笔记-分页
为何要分页 减少数据处理量 便于前端展示数据 使用Limit分页 语法结构 SELECT * FROM user LIMIT startIndex,pageSize; SELECT * FROM us ...
- Java程序设计(2021春)——第四章接口与多态笔记与思考
Java程序设计(2021春)--第四章接口与多态笔记与思考 本章概览: 4.1 接口(接口的概念和声明接口.实现接口的语法) 4.2 类型转换 4.3 多态的概念 4.4 多态的应用 4.5 构造方 ...
- 智能合约审计-不安全的delegatecall
简介 当合约A以delegatecall方式调用时, 相当于将外部合约B的func()代码复制过来 (其函数中涉及的变量或函数都需要在本地存在), 在合约A上下文空间中执行. 合约 pragma so ...
- 606页Android最新面试题含答案,助力成为offer收割机
如何才能通过一线互联网公司面试?相信这是很多人的疑惑,希望看完本篇文章能给大家一些启发. 下面是我花了将近一个月的时间整理的一份面试题库.这些面试题,包括我本人自己去面试遇到的,还有其他人员去面试遇到 ...
- Spring全家桶--单数据源的配置
前言 spring数据源的配置网络上有很多例子,这里我也来介绍一下单数据源配置的例子,基于SpringBoot的方式和原生的Spring的方式. 一.生成项目骨架(SpringBoot),运行一个简单 ...
- Python实现发送邮件(实现单发/群发邮件验证码)
Python smtplib 教程展示了如何使用 smtplib 模块在 Python 中发送电子邮件. 要发送电子邮件,我们使用 Python 开发服务器,Mailtrap 在线服务和共享的网络托管 ...
- docker安装maven私服
目录 一.nexus3安装 二.创建私服仓库 三.发布jar包到私服 四.引用maven私服jar包 五.参考 一.nexus3安装 1.安装镜像 docker pull sonatype/nexus ...