生产调优3 HDFS-多目录配置
HDFS-多目录配置
NameNode多目录配置
NameNode的本地目录可以配置多个,且每个目录存放内容相同,增加了可靠性

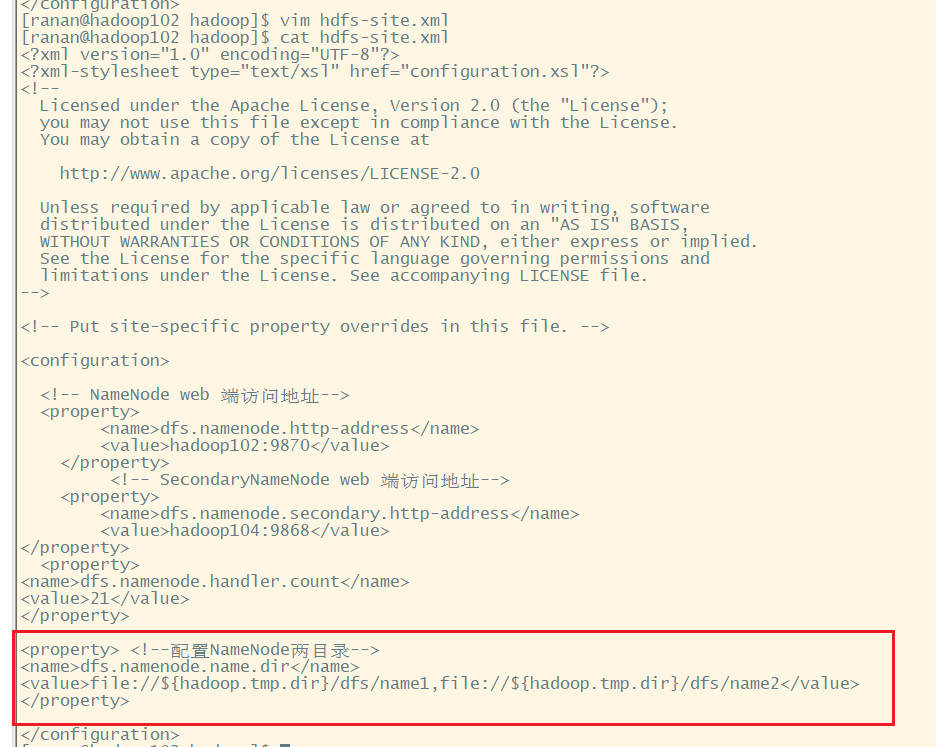
1.修改hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
注意: 因为每台服务器节点的磁盘情况不同, 所以这个配置配完之后,可以选择不分发
hadoop.tmp.dir的配置文件在 /opt/module/hadoop-3.1.3/etc/hadoop下的core-default.xml(核心配置文件)
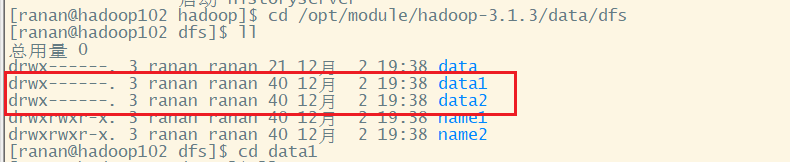
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
2.格式化NameNode
格式化NameNode步骤
1.停止集群
2.删除data和logs中的所有数据
3.格式化集群并启动
停止集群,删除三台节点的data和logs中所有数据
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
格式化集群步并启动,这里只启动HDFS
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
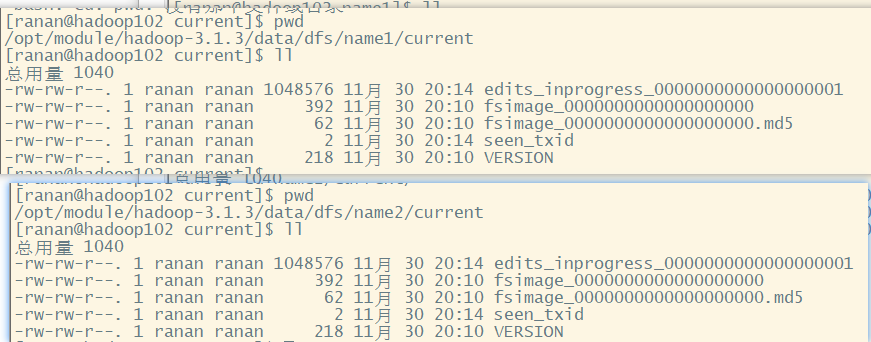
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改后的目录结构

两个NameNode目录存放内容相同,只是提高了可靠性,并没有真正提高高可用性,了解即可
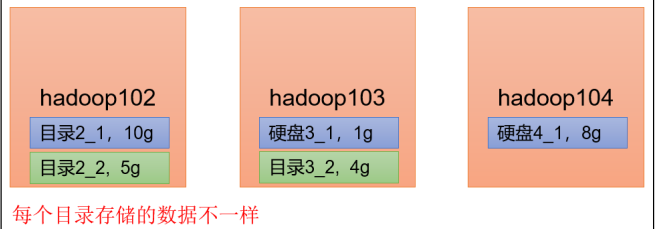
DataNode多目录配置(重要)
DataNode可以配置多个目录,每个目录存储的数据不一样(不是副本)
随着Data越来越多,可以增加硬盘空间来存储更多的数据
1.修改hdfs-site.xml
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构

修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
重启集群,去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
[ranan@hadoop102 hadoop]$ myhadoop.sh stop
[ranan@hadoop102 hadoop]$ myhadoop.sh start
[ranan@hadoop102 hadoop]$ cd /opt/module/hadoop-3.1.3/data/dfs
2.测试两个DataNode数据不一致
向集群上传一个文件,再次观察两个文件夹里面的内容一个有一个没有
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put liubei.txt /
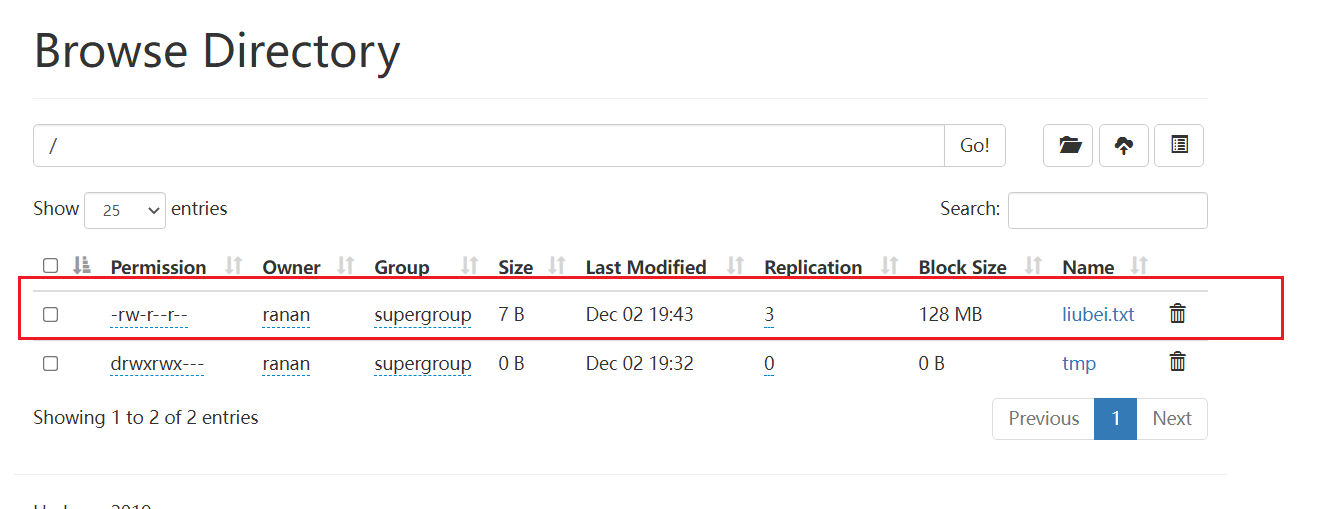
data2数据为空
[ranan@hadoop102 finalized]$ ll
总用量 0
[ranan@hadoop102 finalized]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data2/current/BP-233650876-192.168.10.102-1638274259376/current/finalized
data1有数据
[ranan@hadoop102 finalized]$ cd /opt/module/hadoop-3.1.3/data/dfs/data1/current/BP-233650876-192.168.10.102-1638274259376/current/finalized/subdir0/subdir0/
[ranan@hadoop102 subdir0]$ ll
总用量 8
-rw-rw-r--. 1 ranan ranan 7 12月 2 19:43 blk_1073741825
-rw-rw-r--. 1 ranan ranan 11 12月 2 19:43 blk_1073741825_1001.meta
单节点内磁盘间数据均衡(Hadoop3.x 新特性)
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可
以执行磁盘数据均衡命令,让磁盘数据均匀。
针对单节点内部磁盘之间的均衡

1 生成均衡计划
如果只有一块磁盘,不会生成计划
注意:这里使用虚拟机模拟的,虚拟机装在了D盘只有一个磁盘,虽然之前给了两个路径但实际还是一块,这里没办法演示
不同的两块硬盘,有独立地址
hdfs diskbalancer -plan hadoop102
2 执行均衡计划
hadoop103.plan.json 是上一步生成的文件
hdfs diskbalancer -execute hadoop102.plan.json
3 查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
4 取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json生产调优3 HDFS-多目录配置的更多相关文章
- JVM调优之Tomcat启动参数配置及详解
开发项目中会遇到Tomcat内存溢出(java.lang.OutOfMemoryError: PermGen space)的问题,通过查找资料找到是通过设置Tomcat 启动堆空间大小.年轻代大小.每 ...
- [转]oracle性能调优之--Oracle 10g AWR 配置
一.ASH和AWR的故事 1.1 关于ASH 我们都知道,用户在ORACLE数据库中执行操作时,必然要创建相应的连接和会话,其中,所有当前的会话信息都保存在动态性能视图V$SESSION中,通过该视图 ...
- 生产调优2 HDFS-集群压测
目录 2 HDFS-集群压测 2.1 测试HDFS写性能 测试1 限制网络 1 向HDFS集群写10个128M的文件 测试结果分析 测试2 不限制网络 1 向HDFS集群写10个128M的文件 2 测 ...
- 生产调优1 HDFS-核心参数
目录 1 HFDS核心参数 1.1 NameNode 内存生产配置 问题描述 hadoop-env.sh中配置 1.2 NameNode 心跳并发配置 修改hdfs-site.xml配置 1.3 开启 ...
- 生产调优4 HDFS-集群扩容及缩容(含服务器间数据均衡)
目录 HDFS-集群扩容及缩容 添加白名单 配置白名单的步骤 二次配置白名单 增加新服务器 需求 环境准备 服役新节点具体步骤 问题1 服务器间数据均衡 问题2 105是怎么关联到集群的 服务器间数据 ...
- PHP性能调优---PHP调试工具Xdebug安装配置教程
说到PHP代码调试,对于有经验的PHPer,通过echo.print_r.var_dump函数,或PHP开发工具zend studio.editplus可解决大部分问题,但是对于PHP入门学习的童鞋来 ...
- 部署和调优 3.1 dns安装配置-1
安装配置DNS服务器 装一个bind,首先搜一下. yum list |grep bind bind.x86_64 我们安装这个 安装 yum install bind.x86_64 -y 看一下 ...
- 部署和调优 2.7 mysql主从配置-1
MySQL 主从(MySQL Replication),主要用于 MySQL 的时时备份或者读写分离.在配置之前先做一下准备工作,配置两台 mysql 服务器,如果你的机器不能同时跑两台 Linux虚 ...
- 部署和调优 3.3 dns安装配置-3
只有一台DNS服务器是不保险的,现在给他配置个从服务器. 在另外一台虚拟机上安装配置DNS服务器.先查看虚拟机ip为:192.168.1.111 ifconfig 给从安装bind和dig命令 yum ...
随机推荐
- binary-tree-postorder-traversal leetcode C++
Given a binary tree, return the postorder traversal of its nodes' values. For example: Given binary ...
- hdu 1159 Common Subsequence(最长公共子序列,DP)
题意: 两个字符串,判断最长公共子序列的长度. 思路: 直接看代码,,注意边界处理 代码: char s1[505], s2[505]; int dp[505][505]; int main(){ w ...
- oracle 账号解锁 java.sql.SQLException: ORA-28000: the account is locked
日志报错:ORA-28000: the account is locked 1.plsql登录提示用户被锁定 2.sys登录sqlplus登录查看 SQL> select username,ac ...
- Swift-技巧(三)使用元组(tuple)
最近看 iOS 的官方功能的 Demo 时,发现代码中使用元组的地方很多,所以兴趣上来,查了下元组的出处. 在苹果的文档中就只有简短的两句,使用元组创建一个组合的值,从函数中返回多个值.元组中的可以使 ...
- 欢迎加入XiyouLinuxGroup邮件列表
一:为什么要使用邮件列表? 与QQ,微信等即时通讯的交流方式相比,使用邮件列表交流有以下好处: 保存性好,易于阅读.它能将一个问题讨论的过程完全保存下来,但是QQ的话,聊天记录很容易就刷没了,再也无法 ...
- TDSQL | 在整个技术解决方案中HTAP对应的混合交易以及分析系统应该如何实现?
从主交易到传输,到插件式解决方案,每个厂商对HTAP的理解和实验方式都有自己的独到解法,在未来整个数据解决方案当中都会往HTAP中去牵引.那么在整个技术解决方案中HTAP对应的混合交易以及分析系统应该 ...
- PTA 列车调度 (25分)
PTA 列车调度 (25分) [程序实现] #include<bits/stdc++.h> using namespace std; int main(){ int num,n; cin& ...
- codeforces心得1---747div2
codeforces心得1---747div2 cf div2的前AB题一般是字符串or数论的找规律结论题 因此标程极为精简 1.小窍门是看样例或者自己打表或造数据找规律 2.一些不确定的操作,可以化 ...
- c++学习笔记1(引用)
引用 格式:类型名&引用名=某变量名: 概念 实例:编写交换整型变量的函数对比 不用引用 实机操作 使用引用 实机操作 实例2:用作函数的返回值 可对函数返回值赋值 常引用 使用格式,在引用前 ...
- C 语言基础,来喽!
前言 C 语言是一门抽象的.面向过程的语言,C 语言广泛应用于底层开发,C 语言在计算机体系中占据着不可替代的作用,可以说 C 语言是编程的基础,也就是说,不管你学习任何语言,都应该把 C 语言放在首 ...