生产调优3 HDFS-多目录配置
HDFS-多目录配置
NameNode多目录配置
NameNode的本地目录可以配置多个,且每个目录存放内容相同,增加了可靠性

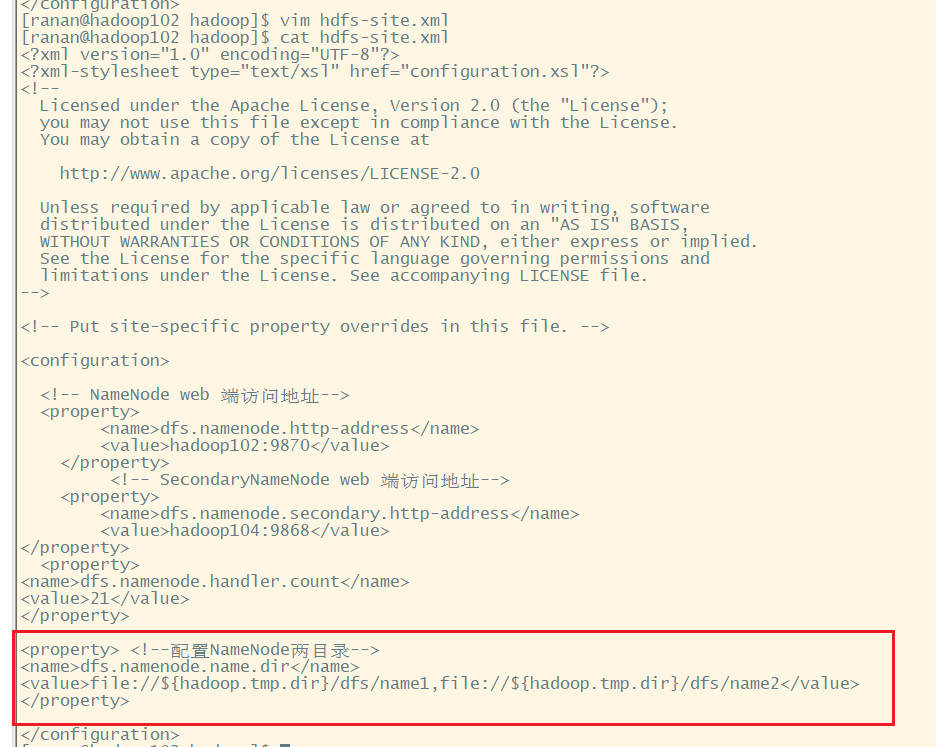
1.修改hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
注意: 因为每台服务器节点的磁盘情况不同, 所以这个配置配完之后,可以选择不分发
hadoop.tmp.dir的配置文件在 /opt/module/hadoop-3.1.3/etc/hadoop下的core-default.xml(核心配置文件)
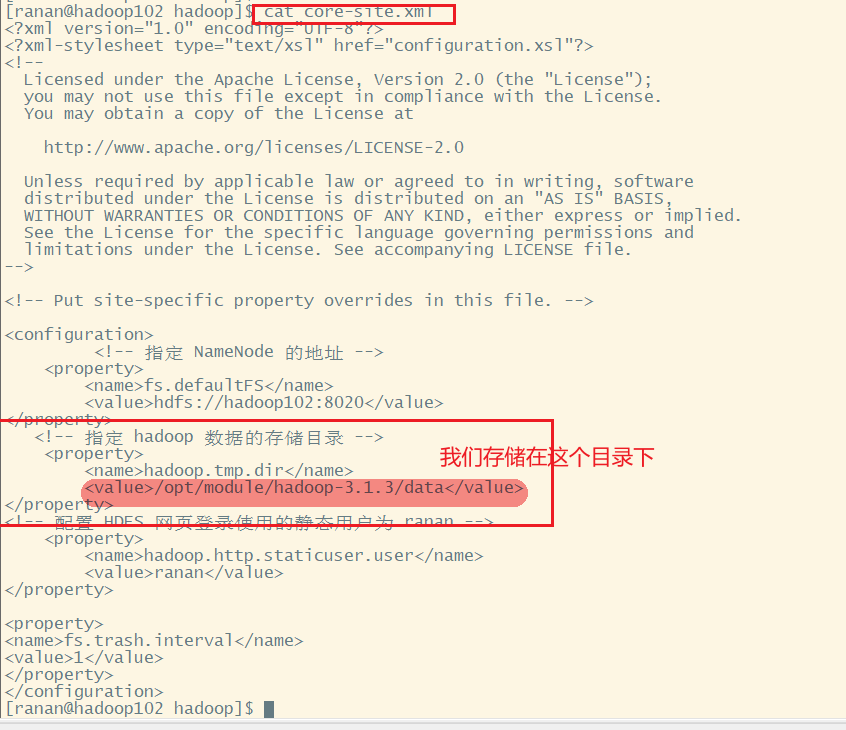
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
2.格式化NameNode
格式化NameNode步骤
1.停止集群
2.删除data和logs中的所有数据
3.格式化集群并启动
停止集群,删除三台节点的data和logs中所有数据
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
格式化集群步并启动,这里只启动HDFS
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
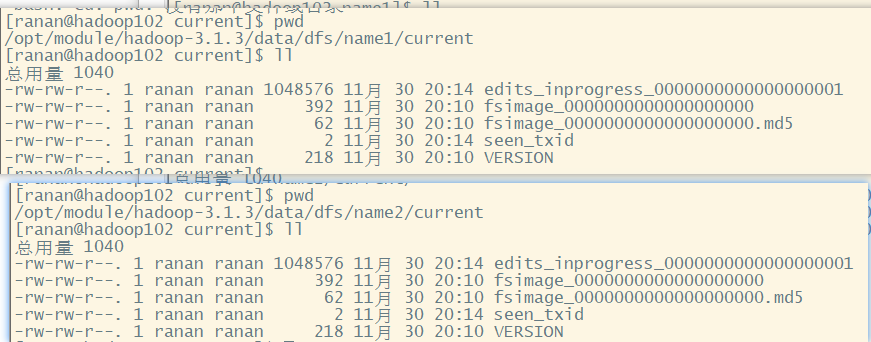
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改后的目录结构

两个NameNode目录存放内容相同,只是提高了可靠性,并没有真正提高高可用性,了解即可
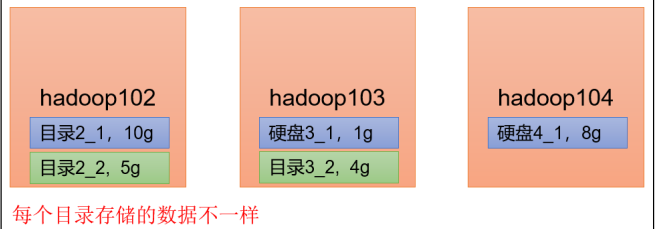
DataNode多目录配置(重要)
DataNode可以配置多个目录,每个目录存储的数据不一样(不是副本)
随着Data越来越多,可以增加硬盘空间来存储更多的数据
1.修改hdfs-site.xml
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构

修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
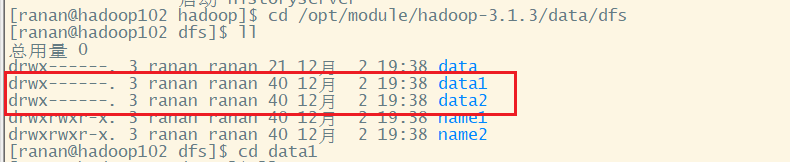
重启集群,去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
[ranan@hadoop102 hadoop]$ myhadoop.sh stop
[ranan@hadoop102 hadoop]$ myhadoop.sh start
[ranan@hadoop102 hadoop]$ cd /opt/module/hadoop-3.1.3/data/dfs
2.测试两个DataNode数据不一致
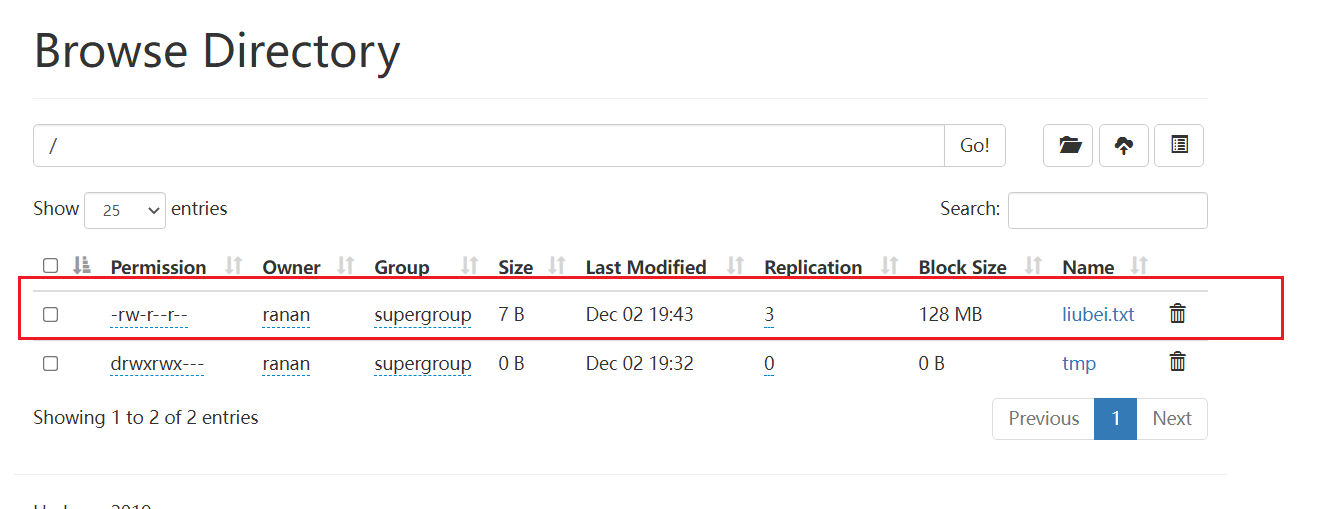
向集群上传一个文件,再次观察两个文件夹里面的内容一个有一个没有
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put liubei.txt /
data2数据为空
[ranan@hadoop102 finalized]$ ll
总用量 0
[ranan@hadoop102 finalized]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data2/current/BP-233650876-192.168.10.102-1638274259376/current/finalized
data1有数据
[ranan@hadoop102 finalized]$ cd /opt/module/hadoop-3.1.3/data/dfs/data1/current/BP-233650876-192.168.10.102-1638274259376/current/finalized/subdir0/subdir0/
[ranan@hadoop102 subdir0]$ ll
总用量 8
-rw-rw-r--. 1 ranan ranan 7 12月 2 19:43 blk_1073741825
-rw-rw-r--. 1 ranan ranan 11 12月 2 19:43 blk_1073741825_1001.meta
单节点内磁盘间数据均衡(Hadoop3.x 新特性)
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可
以执行磁盘数据均衡命令,让磁盘数据均匀。
针对单节点内部磁盘之间的均衡

1 生成均衡计划
如果只有一块磁盘,不会生成计划
注意:这里使用虚拟机模拟的,虚拟机装在了D盘只有一个磁盘,虽然之前给了两个路径但实际还是一块,这里没办法演示
不同的两块硬盘,有独立地址
hdfs diskbalancer -plan hadoop102
2 执行均衡计划
hadoop103.plan.json 是上一步生成的文件
hdfs diskbalancer -execute hadoop102.plan.json
3 查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
4 取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json生产调优3 HDFS-多目录配置的更多相关文章
- JVM调优之Tomcat启动参数配置及详解
开发项目中会遇到Tomcat内存溢出(java.lang.OutOfMemoryError: PermGen space)的问题,通过查找资料找到是通过设置Tomcat 启动堆空间大小.年轻代大小.每 ...
- [转]oracle性能调优之--Oracle 10g AWR 配置
一.ASH和AWR的故事 1.1 关于ASH 我们都知道,用户在ORACLE数据库中执行操作时,必然要创建相应的连接和会话,其中,所有当前的会话信息都保存在动态性能视图V$SESSION中,通过该视图 ...
- 生产调优2 HDFS-集群压测
目录 2 HDFS-集群压测 2.1 测试HDFS写性能 测试1 限制网络 1 向HDFS集群写10个128M的文件 测试结果分析 测试2 不限制网络 1 向HDFS集群写10个128M的文件 2 测 ...
- 生产调优1 HDFS-核心参数
目录 1 HFDS核心参数 1.1 NameNode 内存生产配置 问题描述 hadoop-env.sh中配置 1.2 NameNode 心跳并发配置 修改hdfs-site.xml配置 1.3 开启 ...
- 生产调优4 HDFS-集群扩容及缩容(含服务器间数据均衡)
目录 HDFS-集群扩容及缩容 添加白名单 配置白名单的步骤 二次配置白名单 增加新服务器 需求 环境准备 服役新节点具体步骤 问题1 服务器间数据均衡 问题2 105是怎么关联到集群的 服务器间数据 ...
- PHP性能调优---PHP调试工具Xdebug安装配置教程
说到PHP代码调试,对于有经验的PHPer,通过echo.print_r.var_dump函数,或PHP开发工具zend studio.editplus可解决大部分问题,但是对于PHP入门学习的童鞋来 ...
- 部署和调优 3.1 dns安装配置-1
安装配置DNS服务器 装一个bind,首先搜一下. yum list |grep bind bind.x86_64 我们安装这个 安装 yum install bind.x86_64 -y 看一下 ...
- 部署和调优 2.7 mysql主从配置-1
MySQL 主从(MySQL Replication),主要用于 MySQL 的时时备份或者读写分离.在配置之前先做一下准备工作,配置两台 mysql 服务器,如果你的机器不能同时跑两台 Linux虚 ...
- 部署和调优 3.3 dns安装配置-3
只有一台DNS服务器是不保险的,现在给他配置个从服务器. 在另外一台虚拟机上安装配置DNS服务器.先查看虚拟机ip为:192.168.1.111 ifconfig 给从安装bind和dig命令 yum ...
随机推荐
- 我的一些JAVA基础见解
这个学期学习JAVA基础课,虽说之前都自学过,但在学习时仍可以思考一些模糊不清的问题,可以更深一步的思考.在这里写下一些需要深入的知识点,对小白们也很友好~ 一.Java数据类型 1.基本数据类型 这 ...
- Python ValueError: Attempted relative import in non-package Relative import相对引用 错误
包含相对路径import的python脚本不能直接运行,只能作为module被引用. 例如 from . import mod1 有这样代码的文件只能最为moulule为不能直接运行.相对路径就是相对 ...
- Nessus home版插件更新
1,进入服务器停止服务 service nessusd stop 2,进入目录执行命令获取Challenge code cd /opt/nessus/sbin/ ./nessuscli fetch - ...
- nohup java -jar xx.jar & ,关闭窗口后退出进程
nohup java -jar dw-report..jar > dw-report.log & 自动退出命令在后台运行 xx.jar程序 明明已经加了"&" ...
- Windows内核中的CPU架构-6-中断门(32-Bit Interrupt Gate)
Windows内核中的CPU架构-6-中断门(32-Bit Interrupt Gate) 中断门和调用门类似,也是一种系统段.同样的它也可以用来提权. 中断门: 虽然中断门的段描述符如下: 但是中断 ...
- Redis6.2发布 地理位置功能增强了什么?
原文地址:https://developer.aliyun.com/article/780257 Redis社区最近刚刚发布Redis6.2 RC1版本,在本次发布中,阿里云Tair团队(阿里云云内存 ...
- JMeter学习笔记--性能测试理论
一.性能测试技能树 二.性能测试流程 三.性能测试相关术语 性能测试指标就是: 多(并发量)快(响应时间)好(稳定性[长时间运行])省(资源使用率).思考时间 1.负载 模拟业务操作对服务器造成压力的 ...
- D3.js V5 教程
D3.js V5 教程 1.在项目中使用D3.js 2. 选择元素和设置(获取)属性 3. 绑定数据 4. 理解Update.Enter.Exit 与 添加.删除元素 未完待续..........
- Apache Shiro 反序列化漏洞分析
Shiro550 环境搭建 参考:https://www.cnblogs.com/twosmi1e/p/14279403.html 使用Docker vulhub中的环境 docker cp 将容器内 ...
- koa2使用ejs模板引擎
在koa中使用ejs并不需要像在node中一样安装了还要引用,只需要npm了就行,同时还需要安装koa-views模块.如: const views = require('koa-views'); 对 ...