浅析线程池 ThreadPoolExecutor 源码
首先看下类的继承关系,不多介绍:
public interface Executor {void execute(Runnable);}
public interface ExecutorService extends Executor {...}
public abstract class AbstractExecutorService implements ExecutorService {...}
public class ThreadPoolExecutor extends AbstractExecutorService {...}
线程池构造器七大参数:
核心线程数,最大线程数,生存时间,时间单位,任务队列,线程工厂,拒绝策略
public ThreadPoolExecutor(int corePoolSize, //核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, //生存时间
TimeUnit unit, //时间单位
BlockingQueue<Runnable> workQueue, //任务队列
ThreadFactory threadFactory, //线程工厂
RejectedExecutionHandler handler) //拒绝策略
先对线程池有个大概的概念:线程池,有若干个运行中的线程(工作者,Worker),负责从任务队列(workQueue)中取任务(Task)出来,并执行它。
private final BlockingQueue<Runnable> workQueue;
private final HashSet<Worker> workers = new HashSet<Worker>();
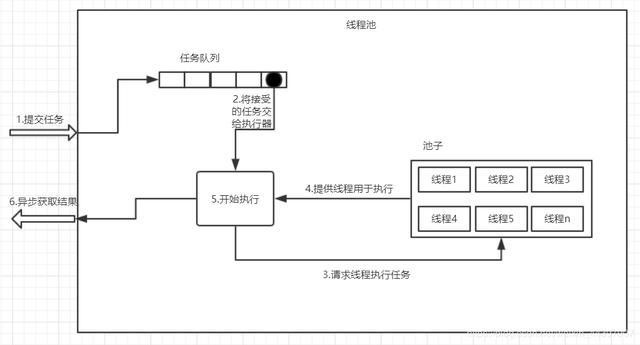
这里再大概介绍一下Worker类:
Worker类内部有两个关键引用:线程Thread t、待执行任务Runnable firstTask。
并且其自身就是Runnable,其run()方法调用自身的runWorker()方法,稍后再来介绍runWorker()干了啥。

回到线程池的使用:一般都是调用submit()或者execute()。submit()只是把传入的Runnable包装成FutureTask来保存执行结果,本质也是调用execute()方法。

因此我们主要分析execute()方法:
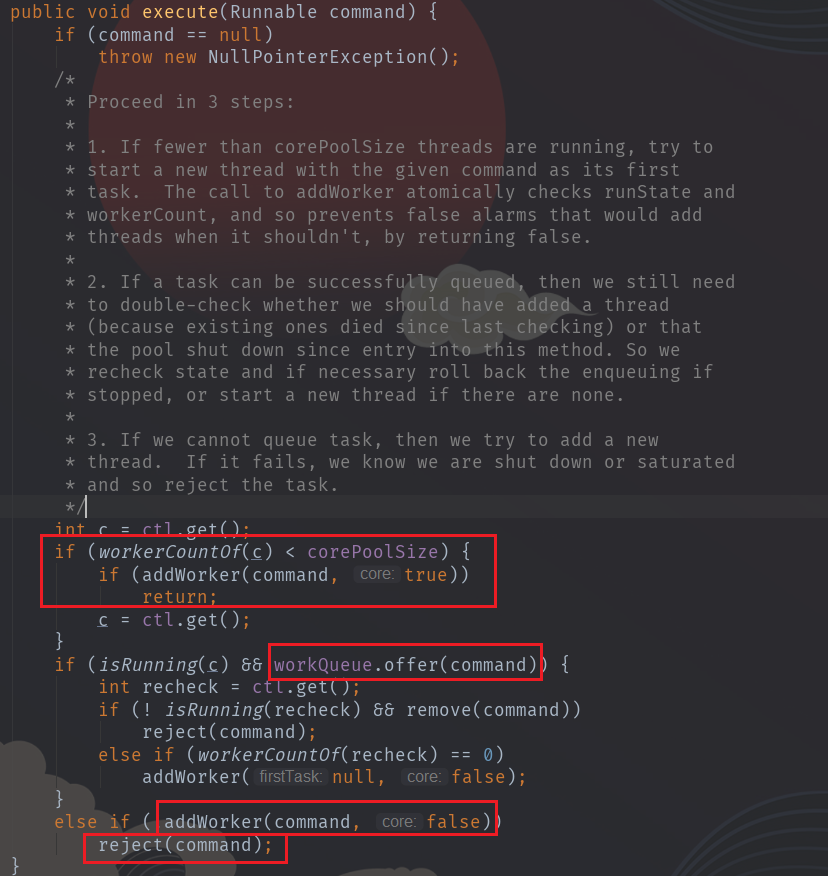
结合代码和注释,可以得出其执行流程:public void execute(Runnable command)
- 不够核心线程数的时候,起新线程(addWorker())
- 核心线程满的时候把command放进workQueue队列
- 核心线程和队列都满,不够最大线程数的时候,起新线程
- 否则执行拒绝策略

其中最关键的当然是创建新线程执行任务的过程,addWorker()方法:
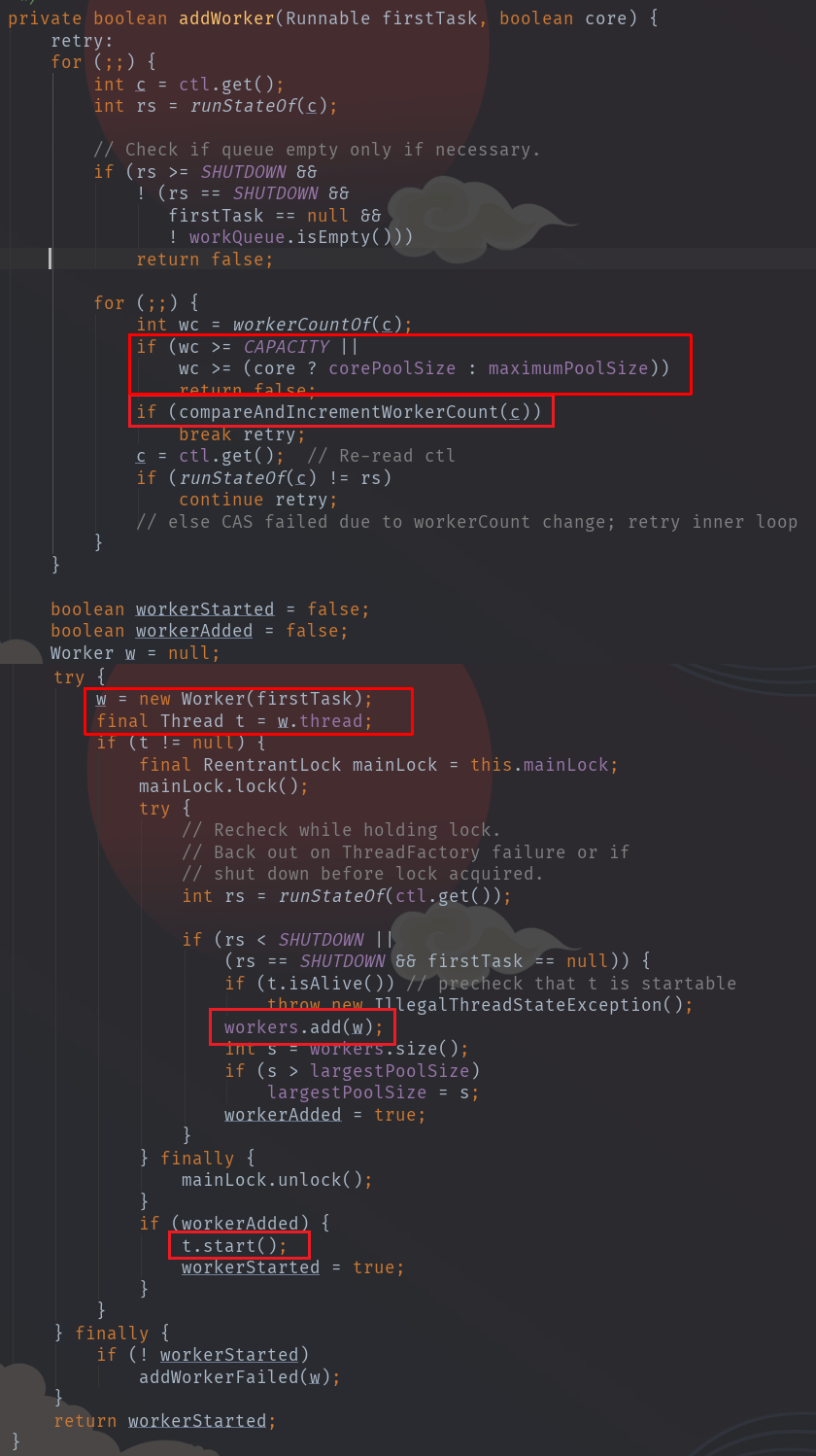
大概描述一下addWorker()的执行步骤:
- 双重CAS把工作线程数加一
new一个Worker w,并放入workers(HashSet)。- 放入成功则执行
w.t.start()(即会调用w.run())
其中,最初传入的command作为w的firstTask,w.t是用线程工厂创建一个新线程,把w自己作为Runnable传入。
而w.run()方法直接执行runWorker()方法:
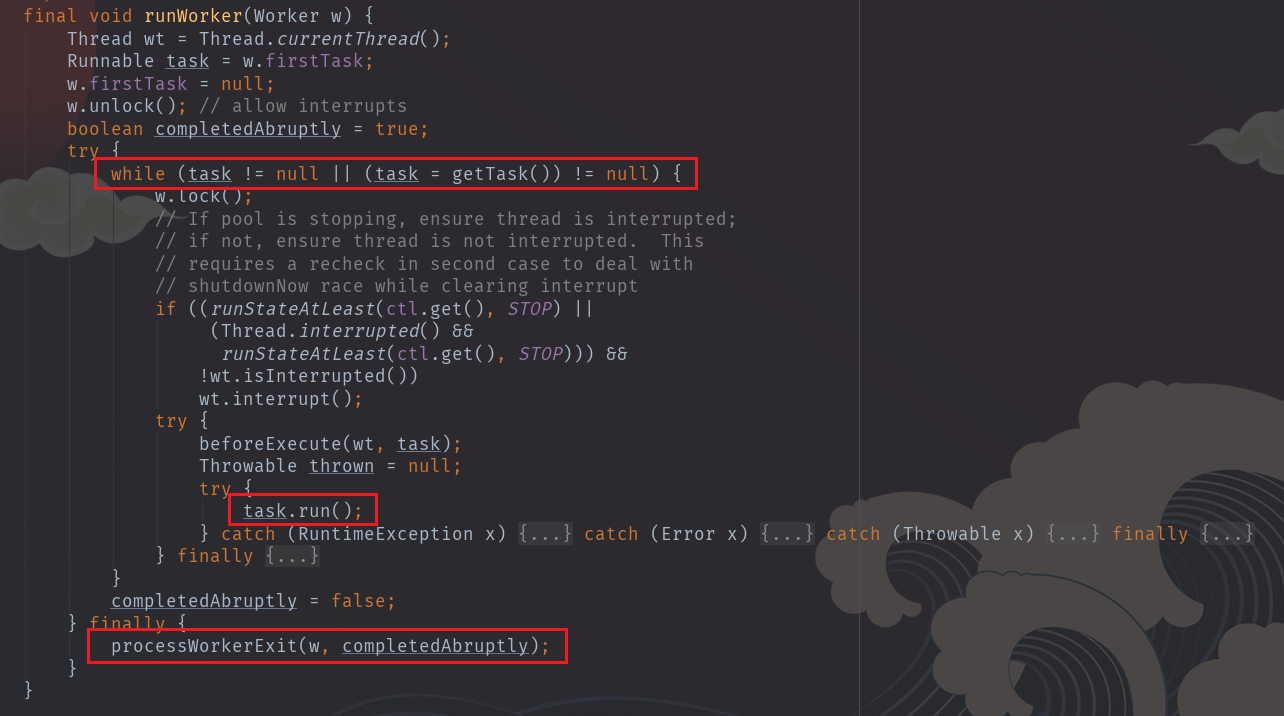
描述一下大概执行过程:
- 把 task 取出来:task = w.firstTask; w.firstTask = null;
- 首先执行 task ,然后循环从阻塞队列 workQueue 中获取一个 task 来执行
- 获取不到任务时,结束运行。结束之前执行一些后续处理。
此外,有几个小问题值得一提:
- 非核心线程与核心线程的区别:
并没有这种区别。从源码可以看到,addWorker()方法的参数boolean core并不会用于创建不同类型的Worker。只在新建Worker之前判断“核心线程是否已满”:core=true时,判断工作线程数是否大于corePoolSize,是则返回false而不新建Worker。core=false时,判断工作线程数是否大于maximumPoolSize,是则返回false而不新建Worker。
- 那怎么使得核心线程不被销毁而非核心线程被销毁呢?
可以看到,如果当前的工作线程数大于核心线程数,则从任务队列中取任务的方法则从阻塞的take()方法换为超时等待keepAliveTime时长的poll()。当非核心线程闲置(任务队列没有任务)的时候,等待一会从getTask()方法返回null,于是线程结束。
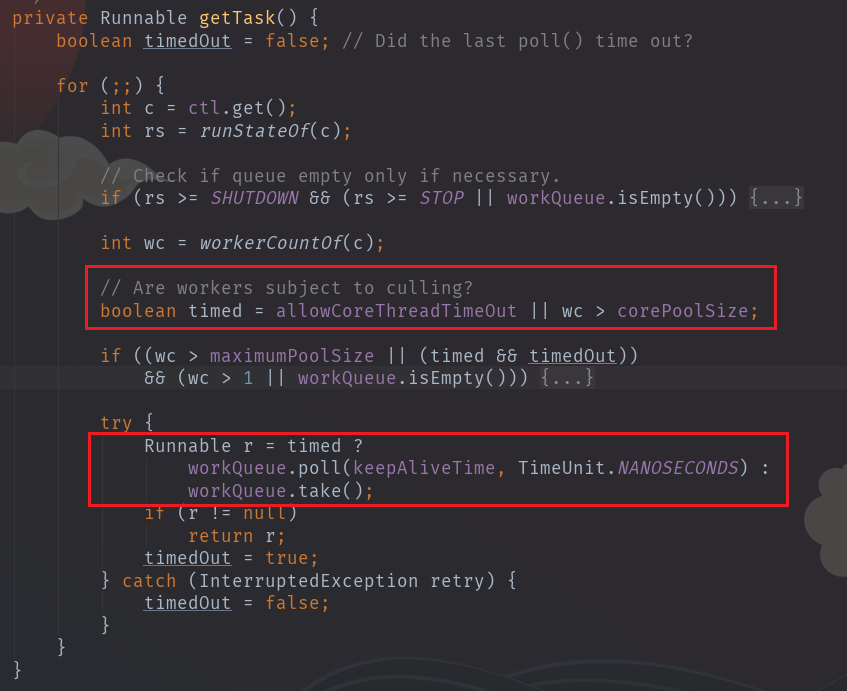
其中allowCoreThreadTimeOut属性指示keepAliveTime是否也会作用于核心线程。
并且,线程结束之前有“后续处理”:
可以看到,如果当前的工作线程数小于核心线程数,则新建一个没有task的线程(等待任务队列中的任务到来)。

最后提一下线程工厂和拒绝策略:
Executors提供的默认线程工厂DefaultThreadFactory其实内部也是new Thread的方式来新建线程,分配pool-i-thread-j这样的线程名称。当然最好自己实现线程工厂来分配有意义的线程名,方便查错。ThreadPoolExecutor提供四种拒绝策略。当然,最好是根据需求自己实现拒绝策略。AbortPolicy:抛出异常DiscardPolicy:扔掉任务,不抛异常DiscardOldestPolicy:扔掉排队时间最久的任务CallerRunsPolicy:调用者负责处理任务
浅析线程池 ThreadPoolExecutor 源码的更多相关文章
- 【Java并发编程】21、线程池ThreadPoolExecutor源码解析
一.前言 JUC这部分还有线程池这一块没有分析,需要抓紧时间分析,下面开始ThreadPoolExecutor,其是线程池的基础,分析完了这个类会简化之后的分析,线程池可以解决两个不同问题:由于减少了 ...
- Java并发之线程池ThreadPoolExecutor源码分析学习
线程池学习 以下所有内容以及源码分析都是基于JDK1.8的,请知悉. 我写博客就真的比较没有顺序了,这可能跟我的学习方式有关,我自己也觉得这样挺不好的,但是没办法说服自己去改变,所以也只能这样想到什么 ...
- Python线程池ThreadPoolExecutor源码分析
在学习concurrent库时遇到了一些问题,后来搞清楚了,这里记录一下 先看个例子: import time from concurrent.futures import ThreadPoolExe ...
- Java核心复习——线程池ThreadPoolExecutor源码分析
一.线程池的介绍 线程池一种性能优化的重要手段.优化点在于创建线程和销毁线程会带来资源和时间上的消耗,而且线程池可以对线程进行管理,则可以减少这种损耗. 使用线程池的好处如下: 降低资源的消耗 提高响 ...
- 线程池ThreadPoolExecutor源码解读研究(JDK1.8)
一.什么是线程池 为什么要使用线程池?在多线程并发开发中,线程的数量较多,且每个线程执行一定的时间后就结束了,下一个线程任务到来还需要重新创建线程,这样线程数量特别庞大的时候,频繁的创建线程和销毁线程 ...
- java内置线程池ThreadPoolExecutor源码学习记录
背景 公司业务性能优化,使用java自带的Executors.newFixedThreadPool()方法生成线程池.但是其内部定义的LinkedBlockingQueue容量是Integer.MAX ...
- 线程池ThreadPoolExecutor源码分析
在阿里编程规约中关于线程池强制了两点,如下: [强制]线程资源必须通过线程池提供,不允许在应用中自行显式创建线程.说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源 ...
- Java并发包源码学习系列:线程池ThreadPoolExecutor源码解析
目录 ThreadPoolExecutor概述 线程池解决的优点 线程池处理流程 创建线程池 重要常量及字段 线程池的五种状态及转换 ThreadPoolExecutor构造参数及参数意义 Work类 ...
- Java并发包源码学习系列:线程池ScheduledThreadPoolExecutor源码解析
目录 ScheduledThreadPoolExecutor概述 类图结构 ScheduledExecutorService ScheduledFutureTask FutureTask schedu ...
随机推荐
- Java-IO流的继承结构
一 IO流的继承结构如下 二 字节流 1.InputStream(字节流读取数据),为抽象类,不可创建对象:其具体实现需要通过子类FileInputStream(读取文件数据).BufferedI ...
- java入门了解、安装jdk及软件的选择
学习编程,一些必要的dos命令还是需要掌握的. 以下只是列出常用的: cd 目录路径: 进入一个目录 cd .. 进入父目录 dir 查看本目录下的文件和子目录列表 cls 清除屏幕命令 上下键 ...
- excel VBA根据一列的逗号隔开值分行
Sub test1() Dim h Dim j As Integer j = 0 Dim n1 As Integer '分行单元格在第几列 Dim m1 As Integ ...
- Unity3D 本地数据持久化几种方式
下面介绍几种 Unity本地记录存储的实现方式. 第一种 Unity自身提供的 PlayerPrefs //保存数据 PlayerPrefs.SetString("Name",mN ...
- 27、异常处理(except)
27.1.什么是异常: 1.异常介绍: 异常就是程序运行时发生错误的信号,在程序出错的时候,则会产生一个异常,若程序没有处理它,则会抛出该异常, 程序的运行也会随之终止,在python中,错误触发的异 ...
- js 获取系统当前时间,判断时间大小
1.获取系统当前时间 getNowTime(tempminit) { if (!tempminit) { tempminit = 0; } var date = new Date(); date.se ...
- AcWing 201. 可见的点
在一个平面直角坐标系的第一象限内,如果一个点(x,y)与原点(0,0)的连线中没有通过其他任何点,则称该点在原点处是可见的. 编写一个程序,计算给0<x,y<=n定整数N的情况下,满足的可 ...
- MIT6.828 Preemptive Multitasking(上)
Lab4 Preemptive Multitasking(上) PartA : 多处理器支持和协作多任务 在实验的这部分中,我们首先拓展jos使其运行在多处理器系统上,然后实现jos内核一些系统功能调 ...
- APDU:APDU常用指令
APDU= ApplicationProtocol data unit, 是智能卡与智能卡读卡器之间传送的信息单元, (给智能卡发送的命令)指令(ISO 7816-4规范有定义) CLA INS P1 ...
- bugku Crypto 下半部分wp
1. 百度托马斯这个人居然还发明了一种轮转的加密法,发现原理是,他将很多行乱序的26个字母,插到一根柱子上,参考糖葫芦的样子,可以旋转每一行,设置自己要发送的明文后,向对方发送乱码的一列,对方只要将这 ...