大数据学习(14)—— HBase进阶
HBase读写流程
在网上找了一张图,这个画的比较简单,就拿这个图来说吧。
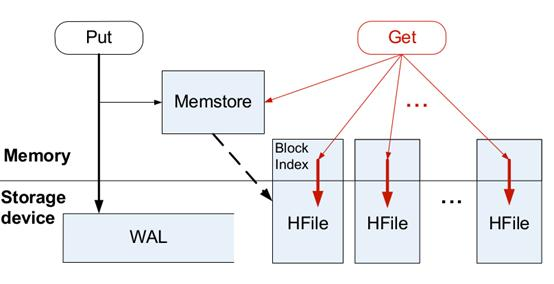
写流程
1.当Client发起一个Put请求时,首先访问Zookeeper获取hbase:meta表。
2.从hbase:meta表查询即将写入数据的Region位置。
3.Client向目标RegionServer发出写命令,同时写WAL(WAL叫预写日志,类似binlog,先写入内存,HLog每秒一次刷入磁盘)和MemStore。
4.MemStore默认满128M时,溢写入HDFS,生成StoreFile文件。
5.写数据可能会引发文件合并或者Region拆分。
读流程
1.当Client发起一个Get请求时,首先访问Zookeeper获取hbase:meta表。
2.从hbase:meta表查询即将读取数据的Region位置。
3.Client向目标RegionServer发出读命令,先从 MemStore 查找数据,如果没有再根据数据索引去StoreFile和BlockCache中查找,并把读取的最新版本数据更新到BlockCache中。
读流程其实比写流程更麻烦,当使用scan批量查找时,数据很可能分散在不同的Region和Store中,需要层层调用查询方法,并把结果汇总。
Protocol Buffer
HBase使用protobufs来保存元数据或者是给远程调用传输对象。这一小节我们来聊聊Protocol Buffer。
这是一种数据序列化技术。XML、JSON这些技术我们都很熟悉了,Protocol Buffer是google内部使用的一种序列化技术,慢慢也开始流行。那么它比其他序列化技术有啥优势呢?一是体积更小,二是能够支持更复杂的结构。
我对这个技术的了解也不是很深入,尝试用大白话来解释一下。
场景:我爸是中医科医生,他们医院看病是不需要挂号的,有很多病人开了处方就去药店抓药,医院没有收入,医生的价值无法体现。中医科就编制了一张中药表,长得像下面这样,医生和药房各一份。
1.景天 2.徐长卿 3.雪见 4.紫萱 5.重楼 6.花楹 7.龙葵 8.飞蓬
不要纠结为啥都是仙剑人名,因为大学时期仙剑玩的太多了,其实这些全部是中草药。
假如有个药方,我瞎掰的:景天10g,雪见6g,重楼20g,龙葵8g
用XML表示是这样的
<药方>
<景天>10g</景天>
<雪见>6g</雪见>
<重楼>20g</重楼>
<龙葵>8g</龙葵>
</药方>
用JSON表示是这样的
{景天:10g,雪见:6g,重楼:20g,龙葵:8g}
用protobuf表示大概是这样的
1:10g,3:6g,5:20g,7:8g
上面这个例子并不准确,但医生们就是这么干的,只写编号和对应的克数,病人拿这个处方去药店是抓不到药的,必须在医院药房才知道是啥。
从这个例子里可以看出,protobuf的优点是数据量很小,缺点也是显而易见的,就是可读性差,没有.proto文件根本不知道传输的是啥。
.proto文件长得是下面这样,就跟医生们的办法一样。
package hospital;
message traditionalMedicine
{
optional int32 景天 = 1;
optional int32 徐长卿 = 2;
optional int32 雪见 = 3;
optional int32 紫萱 = 4;
optional int32 重楼 = 5;
optional int32 花楹 = 6;
optional int32 龙葵 = 7;
optional int32 飞蓬 = 8;
}
protocol buffer不是HBase重点要关注的内容,如果感兴趣,可以自行学习。
性能调优
大家都是写代码,为啥他拿3万月薪,我只能拿1万?代码的性能和质量体现了这种差异。
HBase性能调优分几个方面来说。
操作系统
- 内存要大。HBase为啥这么快?因为很多操作是先写内存,然后再落盘的,没内存玩不转。官网这么写的“RAM, RAM, RAM. Don’t starve HBase.”,这技术人员很可爱了。
- 使用64位的平台(比如JVM)。原因很明显了,32位只能管理4G内存,没法玩。
- 虚拟内存设置为0。说白了就是不想发生磁盘I/O。
网络
影响Hadoop和HBase性能的关键因素可能是正在使用的交换设备。项目初期过早地做出(设备选型的)决定,可能会在后续集群规模翻倍的时候埋下隐患。
充分考虑这几点:
- 设备交换能力
- 系统连接数
- 数据上行速率
在CAP里,HBase默认是CP模型,即支持强一致性和分区容错性,不保证可用性。当开启多region的时候,它是AP模型,支持可用性和分区容错性,不支持强一致性。
JAVA
Java方面的调优就一点:尽量避免full GC,用行话说,这种情况将stop the world,整个世界都安静了,等它垃圾回收。
- 增加-XX:CMSInitiatingOccupancyFraction参数,阈值设置为60%-70%以上。
- 使用最新的JVM来避免老生代碎片。
HBase参数配置
配置项很多,参考HBase参数配置
数据库设计
- 列族要少。尽量只定义1个列族,最多不要超过3个。列族的memStore满了就要溢写到磁盘,溢写是个表级操作,一个列族的溢写会引发其他列族一起溢写。当多个列族的数据倾斜时,其他列族会生成很多个小文件,影响性能。
- 行键、列族和列名要短。这些与具体数值无关的属性会被大量重复存储,不能太长。
- 设置合理的Region数量和大小。一个RegionServer上有20-200个Region是合理的范围,一个Region的大小在10-20GB之间。一个RegionServer上的数据总量保持在1TB以内。
- 使用布隆过滤器。布隆过滤器能够有效减少Get对磁盘的读操作,有行过滤器和行+列过滤器两种。
其他
HBase为什么这么快?因为它合理利用了内存,并且批量写入磁盘,用顺序写来代替随机写,这是它性能优异的原因。下一篇我们来介绍LSM树,这是它采用的存储形式。
大数据学习(14)—— HBase进阶的更多相关文章
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习(13)—— HBase入门
从这一篇起,开始介绍HBase相关知识.还是一样,大数据的学习,获取官网知识很重要.官网看这里Apache HBase HBase简介 Apache HBase is the Hadoop datab ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
随机推荐
- 【题解】斐波拉契 luogu3938
题目 题目描述 小 C 养了一些很可爱的兔子. 有一天,小 C 突然发现兔子们都是严格按照伟大的数学家斐波那契提出的模型来进行 繁衍:一对兔子从出生后第二个月起,每个月刚开始的时候都会产下一对小兔子. ...
- OO unit3 summary
Unit3 JML(Java Modeling Language) 是用于对 Java 程序进行规格化设计的一种表示语言,它对于方法内部具体是如何实现的并无要求,只是对方法的接口以及行为进行限制, ...
- sql循环说明
while循环:主要是判断,不能使用表中的ID,临时表是ID自增的,通过自增ID可以查出表ID(语法简单,需要配合其他代码操作表ID)游标循环:可以使用表中的ID ,进行修改等操作(语法难一点,核心代 ...
- C语言:C99 中的37个关键字
一.数据类型关键字(12个): 1.char [tʃɑ:]:声明字符型变量或函数 2.double [ˈdʌbəl] :声明双精度变量或函数 3.enum :声明枚举类型 4.float [fləut ...
- linux密码策略
1.密码过期策略 # vim /etc/login.defs PASS_MAX_DAYS 99999 # 一个密码最长可以使用的天数: PASS_MIN_DAYS 0 # 更换密码的最小天数: PAS ...
- 精尽Spring Boot源码分析 - Condition 接口的扩展
该系列文章是笔者在学习 Spring Boot 过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring Boot 源码分析 GitHub 地址 进行阅读 Sprin ...
- 面试题三:MySQL
MySQL有哪些存储引擎? MyISAM.InnoDB.CSV.Memory等 MyISAM和InnoDB比较: InnoDB MyISAM 事务 支持 不支持 存储限制 64TB 无 锁粒度 行锁 ...
- Redis:银河麒麟arm服务器安装redis5.0.3,配置开机自启
百度网盘下载地址 链接:https://pan.baidu.com/s/1f2ghL2-0brPt0IodjfqOqQ提取码:9al1 解压tar包 #解压tar包 tar -xvf arm-r ...
- mybatis中使用selectKey,返回结果一直是1
转:https://www.cnblogs.com/caizhen/p/9186608.html mybatis中使用selectKey,返回结果一直是1,结合这个问题,笔记一下selectKey标签 ...
- centos 安装es
第一步:必须要有jre支持 elasticsearch是用Java实现的,跑elasticsearch必须要有jre支持,所以必须先安装jre 第二步:下载elasticsearch 进入官方下载 h ...