🏆【Java技术专区】「编译器专题」重塑认识Java编译器的执行过程(消除数组边界检查+公共子表达式)!
前提概要
Java的class字节码并不是机器语言,要想让机器能够执行,还需要把字节码翻译成机器指令。这个过程是Java虚拟机做的,这个过程也叫编译。是更深层次的编译。
在编译原理中,把源代码翻译成机器指令,一般要经过以下几个重要步骤:
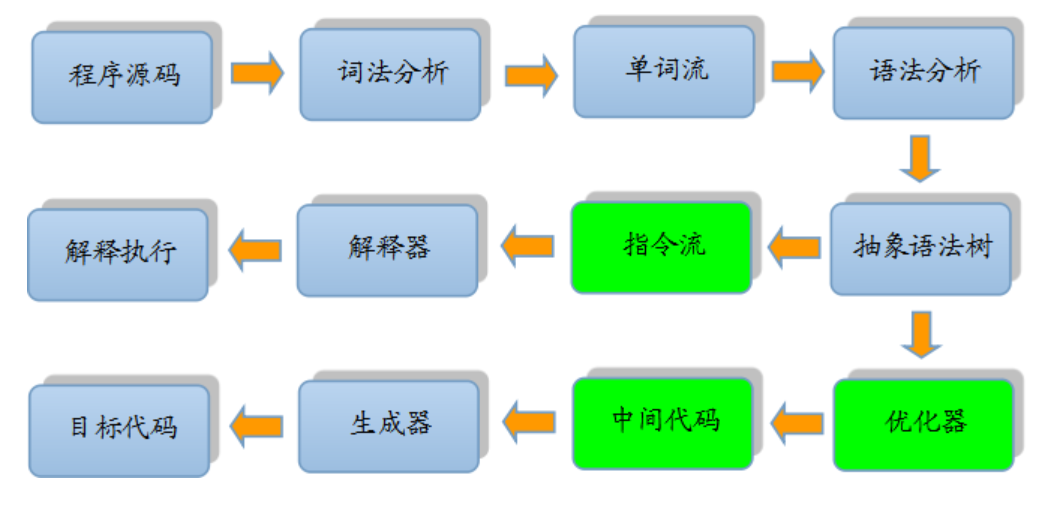
根据完成任务不同,可以将编译器的组成部分划分为前端(Front End)与后端(Back End)。
前端编译主要指与源语言有关但与目标机无关的部分,包括词法分析、语法分析、语义分析与中间代码生成。
后端编译主要指与目标机有关的部分,包括代码优化和目标代码生成等。
我们可以把将.java文件编译成.class的编译过程称之为前端编译。把将.class文件翻译成机器指令的编译过程称之为后端编译。

Java中的前端编译
前端编译主要指与源语言有关但与目标机无关的部分,包括词法分析、语法分析、语义分析与中间代码生成。
我们所熟知的
javac的编译就是前端编译。除了这种以外,我们使用的很多IDE,如eclipse,idea等,都内置了前端编译器。主要功能就是把.java代码转换成.class代码。
词法分析
词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,将字符序列转换为标记(token)序列流的过程。这里的标记是一个字符串,是构成源代码的最小单位。在这个过程中,词法分析器还会对标记进行分类。
词法分析器通常不会关心标记之间的关系(属于语法分析的范畴),举例来说:词法分析器能够将括号识别为标记,但并不保证括号是否匹配。
语法分析
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等,语法分析程序判断源程序在结构上是否正确。源程序的结构由上下文无关文法描述。
语义分析
语义分析是编译过程的一个逻辑阶段, 语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查,进行类型审查。语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。
语义分析的一个重要部分就是类型检查。比如很多语言要求数组下标必须为整数,如果使用浮点数作为下标,编译器就必须报错。再比如,很多语言允许某些类型转换,称为自动类型转换。
中间代码生成
在源程序的语法分析和语义分析完成之后,很多编译器生成一个明确的低级的或类机器语言的中间表示。该中间表示有两个重要的性质: 1.易于生成; 2.能够轻松地翻译为目标机器上的语言。
在Java中,javac执行的结果就是得到一个字节码,而这个字节码其实就是一种中间代码。
著名的解语法糖操作,也是在javac中完成的。
Java中的后端编译
首先,我们大家都知道,通常通过 javac 将程序源代码编译,转换成 java 字节码,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。这就是传统的JVM的解释器(Interpreter)的功能。为了解决这种效率问题,引入了 JIT 技术。
JAVA程序还是通过解释器进行解释执行,当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
HotSpot虚拟机中内置了两个JIT编译器:Client Complier和Server Complier,分别用在客户端和服务端,目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
当 JVM 执行代码时,它并不立即开始编译代码。首先,如果这段代码本身在将来只会被执行一次,那么从本质上看,编译就是在浪费精力。因为将代码翻译成 java 字节码相对于编译这段代码并执行代码来说,要快很多。第二个原因是最优化,当 JVM 执行某一方法或遍历循环的次数越多,就会更加了解代码结构,那么 JVM 在编译代码的时候就做出相应的优化。
热点检测
上面我们说过,要想触发JIT,首先需要识别出热点代码。目前主要的热点代码识别方式是热点探测(Hot Spot Detection),有以下两种:
基于采样的方式探测(Sample Based Hot Spot Detection) :周期性检测各个线程的栈顶,发现某个方法经常出险在栈顶,就认为是热点方法。好处就是简单,缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测。
基于计数器的热点探测(Counter Based Hot Spot Detection)。采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译。
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
方法计数器:顾名思义,就是记录一个方法被调用次数的计数器。
回边计数器:是记录方法中的for或者while的运行次数的计数器。
编译优化
前面提到过,JIT除了具有缓存的功能外,还会对代码做各种优化。说到这里,不得不佩服HotSpot的开发者,他们在JIT中对于代码优化真的算是面面俱到了。
这里简答提及几个我觉得比较重要的优化技术,并不准备直接展开,读者感兴趣的话,我后面再写文章单独介绍。
逃逸分析、 锁消除、 锁膨胀、 方法内联、 空值检查消除、 类型检测消除、 公共子表达式消除
公共子表达式消除
公共子表达式消除是一项非常经典的、普遍应用于各种编译器的优化技术,它的含义是: 如果一个表达式E之前已经被计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就称为公共子表达式。
对于这种表达式,没有必要花时间再对它重新进行计算,只需要直接用前面计算过的表达式结果代替E。如果这种优化仅限于程序基本块内,便可称为局部公共子表达式消除( Local Common SubexpressionElimination )
如果这种优化的范围涵盖了多个基本块,那就称为全局公共子表达式消除 ( Global Common Subexpression Elimination )。
如下代码:
int d = ( c * b ) * 12 + a + ( a + b * c )
如果这段代码交给 Javac 编译器则不会进行优化,那么生成的代码将如下所示:
iload_2 // b
imul // 计算 b * c
bipush 12 // 推入 12
imul // 计算 ( c * b ) * 12
iload_1 // a
iadd // 计算 ( c * b ) * 12 + a
iload_1 // a
iload_2 // b
iload_3 // c
imul // 计算 b * c
iadd // 计算 a + b * c
iadd // 计算 ( c * b ) * 12 + a + a + b * c
istore 4
是完全按照遵照 Java 源码的写法直译而成的。
当这段代码进人虚拟机即时编译器后,它将进行如下优化:编译器检测到 c * b 与 b * c 是一样的表达式, 而且在计算期间 b 与 c 的值是不变的。
因此这条表达式就可能被视为:
int d = E * 12 + a + ( a + E );
这时候、编译器还可能(取决于哪种虚拟机的编译器以及具体的上下文而定)进行另外一种优化——代数化简 (Algebraic Simplification) , 在E本来就有乘法运算的前提下, 把表达式变为:
int d = E * 13 + a + a;
表达式进行变换之后,再计算起来就可以节省一些时间了。
数组边界检查消除
数组边界检查消除 ( Array Bounds Checking Elimination) 是即时编译器中的一项语言相关的经典优化技术。我们知道Java语言是一门动态安全的语言,对数组的读写访问也不像 C、C++ 那样实质上就是裸指针操作。
如果有一个数组 a[],在Java语言中访问数组元素 foo[i] 的时候系统将会自动进行上下界的范围检查,即 i 必须满足 " i >= 0 && i < a.length " 的访问条件,否则将抛出一个运行时异常: java.lang.ArrayIndexOutOfBondsException。
这对软件开发者来说是一件很友好的事情,即使程序员没有专门编写防御代码,也能够避免大多数的溢出攻击。但是对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判定操作,对于拥有大量数组访问的程序代码,这必定是一种性能负担。
无论如何,为了安全,数组边界检查肯定是要做的,但数组边界检查是不是必须在运行期间一次不漏地进行则是可以 “商量” 的事情。例如下面这个简单的情况: 数组下标是一个常量,如 a[3],只要在编译期根据数据流分析来确定 foo.length 的值,并判断下标 “3” 没有越界,执行的时候就无须判断了。更加常见的情况是,数组访问发生在循环之中,并且使用循环变量来进行数组的访问。
如果编译器只要通过数据流分析就可以判定循环变量的取值范围永远在区间 [ 0,a.length ) 之内,那么在循环中就可以把整个数组的上下界检查消除掉,这可以节省很多次的条件判断操作。
把这个数组边界检查的例子放在更高的视角来看,大量的安全检查使编写 Java 程序比编写 C 和 C++ 程序容易了很多,比如: 数组越界会得到ArrayIndexOutfBoundsExcepion 异常;空指针访问会得到 NullPointExceptioen 异常;除数为零会得到 ArithmeticExceptinon 异常…在和C++程序中出现类似的问题,一个不小心就会出现 Segment Fault 信号或者 Windows 编程中常见的 “XXX内存不能为 Read/Write” 之类的提示,处理不好程序就直接崩溃退出了。
但这些安全检查也导致出现相同的程序,从而使 Java 比 C 和 C++ 要做更多的事情(各种检查判断),这些事情就会导致一些隐式开销, 如果不处理好它们,就很可能成为一项 “ Java语言天生就比较慢” 的原罪。为了消除这些隐式开销,除了如数组边界检查优化这种尽可能把运行期检查提前到编译期完成的思路之外、还有一种避开的处理思路——隐式异常处理, Java中空指针检查和算术运算中除数为零的检查都采用了这种方案。
举个例子,程序中访问一个对象(假设对象叫 a )的某个属性(假设属性叫 value ),那以 Java 伪代码来表示虚拟机访问 a.value 的过程为:
if (foo != null) {
return foo.value;
}else{
throw new NullPointException();
}
在使用隐式异常优化之后,虚拟机会把上面的伪代码所表示的访问过程变为如下伪代码:
try{
return foo.value;
} catch (segment_fault) {
uncommon_ trap();
}
虚拟机会注册一个 Segment Fault 信号的异常处理器 ( 伪代码中的uncommon_trap(),务必注意这里是指进程层面的异常处理器,并非真的 Java 的 try-catch 语句的异常处理器),这样当 a 不为空的时候,对 value 的访问是不会有任何额外对 a 判空的开销的,而代价就是当 a 真的为空时,必须转到异常处理器中恢复中断并抛出 NullPointException 异常。
进人异常处理器的过程涉及进程从用户态转到内核态中处理的过程,结束后会再回到用户态,速度远比一次判空检查要慢得多。
当 foo 极少为空的时候,隐式异常优化是值得的,但假如 foo 经常为空,这样的优化反而会让程序更慢。幸好 HotSpot 虚拟机足够聪明,它会根据运行期收集到的性能监控信息自动选择最合适的方案。
🏆【Java技术专区】「编译器专题」重塑认识Java编译器的执行过程(消除数组边界检查+公共子表达式)!的更多相关文章
- ☕【Java技术指南】「编译器专题」重塑认识Java编译器的执行过程(常量优化机制)!
问题概括 静态常量可以再编译器确定字面量,但常量并不一定在编译期就确定了, 也可以在运行时确定,所以Java针对某些情况制定了常量优化机制. 常量优化机制 给一个变量赋值,如果等于号的右边是常量的表达 ...
- ☕【Java技术指南】「编译器专题」深入分析探究“静态编译器”(JAVA\IDEA\ECJ编译器)是否可以实现代码优化?
技术分析 大家都知道Eclipse已经实现了自己的编译器,命名为 Eclipse编译器for Java (ECJ). ECJ 是 Eclipse Compiler for Java 的缩写,是 Jav ...
- 🏆【Java技术专区】「探针Agent专题」Java Agent探针的技术介绍(1)
前提概要 Java调式.热部署.JVM背后的支持者Java Agent: 各个 Java IDE 的调试功能,例如 eclipse.IntelliJ : 热部署功能,例如 JRebel.XRebel. ...
- 🏆【Java技术专区】「开发实战专题」Lombok插件开发实践必知必会操作!
前言 在目前众多编程语言中,Java 语言的表现还是抢眼,不论是企业级服务端开发,还是 Andorid 客户端开发,都是作为开发语言的首选,甚至在大数据开发领域,Java 语言也能占有一席之地,如Ha ...
- 🏆【Java技术专区】「并发编程专题」教你如何使用异步神器CompletableFuture
前提概要 在java8以前,我们使用java的多线程编程,一般是通过Runnable中的run方法来完成,这种方式,有个很明显的缺点,就是,没有返回值.这时候,大家可能会去尝试使用Callable中的 ...
- ☕【Java技术指南】「TestNG专题」单元测试框架之TestNG使用教程指南(上)
TestNG介绍 TestNG是Java中的一个测试框架, 类似于JUnit 和NUnit, 功能都差不多, 只是功能更加强大,使用也更方便. 详细使用说明请参考官方链接:https://testng ...
- Java已五年1—二本物理到前端实习生到Java程序员「回忆贴」
关键词:郑州 二本 物理专业 先前端实习生 后Java程序员 更多文章收录在码云仓库:https://gitee.com/bingqilinpeishenme/Java-Tutorials 前言 没有 ...
- 🏆【Java技术专区】「延时队列专题」教你如何使用【精巧好用】的DelayQueue
延时队列前提 定时关闭空闲连接:服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之. 定时清除额外缓存:缓存中的对象,超过了空闲时间,需要从缓存中移出. 实现任务超时处理:在网络协议滑动窗口请求 ...
- ☕【Java技术指南】「OpenJDK专题」想不想编译属于你自己的JDK呢?(Windows10环境)
Win10下编译OpenJDK8 编译环境 Windows10专业版64位: 编译前准备 Tip: 以下软件的安装和解压目录尽量不要包含中文或空格,不然可能会出现问题 安装 Visual Studio ...
随机推荐
- 每日三道面试题,通往自由的道路4——JVM篇
茫茫人海千千万万,感谢这一秒你看到这里.希望我的面试题系列能对你的有所帮助!共勉! 愿你在未来的日子,保持热爱,奔赴山海! 每日三道面试题,成就更好自我 昨天既然你有讲到字符串常量池是吧,那这样吧 1 ...
- 渗透测试工具Burpsuite操作教程
Burpsuite简介 Burp Suite 是一款专业的Web和移动应用程序渗透测试工具,是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻 ...
- 20204107 孙嘉临《Python程序设计》实验一报告
课程:<python程序设计> 班级:2041 姓名:孙嘉临 学号:20204107 实验教师:王志强 实验日期:2021年4月12日 必修/选修:公选课 ##一.实验内容 1.熟悉Pyt ...
- Git上传代码遇到的报错
Git上传代码遇到的报错 1.git上传代码卡住(Total 7072 (delta 2508), reused 6844 (delta 2376), pack-reused 0) git confi ...
- JDK1.8 ArrayList 源码解析
源码的解读逻辑按照程序运行的轨迹展开 Arraylist的继承&实现关系 打开ArrayList源码,会看到有如下的属性定义, ArrayList中定义的属性 /** * Default in ...
- 资源:Intellij IDEA 最新旗舰版注册激活破解*附注册码(2020年亲测)
永久激活 1. 下载jetbrains-agent.jar包(2020.03.22亲测) 链接: https://pan.baidu.com/s/1BFXPwlROEF03BkhGzGIgEA 提取码 ...
- python之struct详解
python之struct详解 2018-05-23 18:20:29 醉小义 阅读数 20115更多 分类专栏: python 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议 ...
- 1.3.1、datetime时间-Before、After、Between
server: port: 8080 spring: application: name: gateway cloud: gateway: routes: - id: guo-system1 uri: ...
- 续PA协商过程
续PA协商过程 当sw3的接口恢复之后会发生2中情况. ①sw3的G0/0/2口先发BPDU ②sw3的G0/0/3口先发BPDU sw3先发送BPDU sw3和sw1的交互过程: sw3的2口恢复后 ...
- homestead
前言 之前写过一篇文章(https://www.jianshu.com/p/5f30280a3c18),说不需要这玩意儿一样可以开发.是的,但是对于团队来说,使用统一的环境.开发工具.编码规范等,对于 ...