PolarDB PostgreSQL Buffer Management 原理
背景介绍
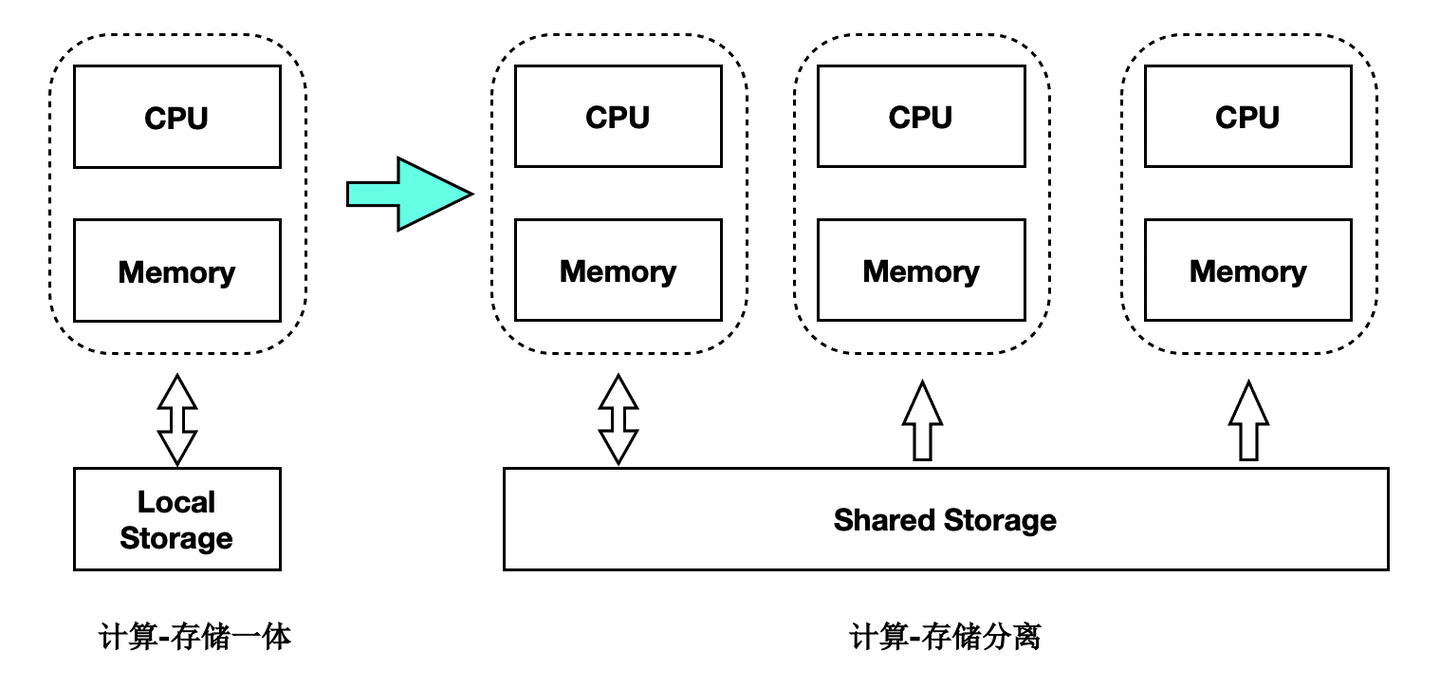
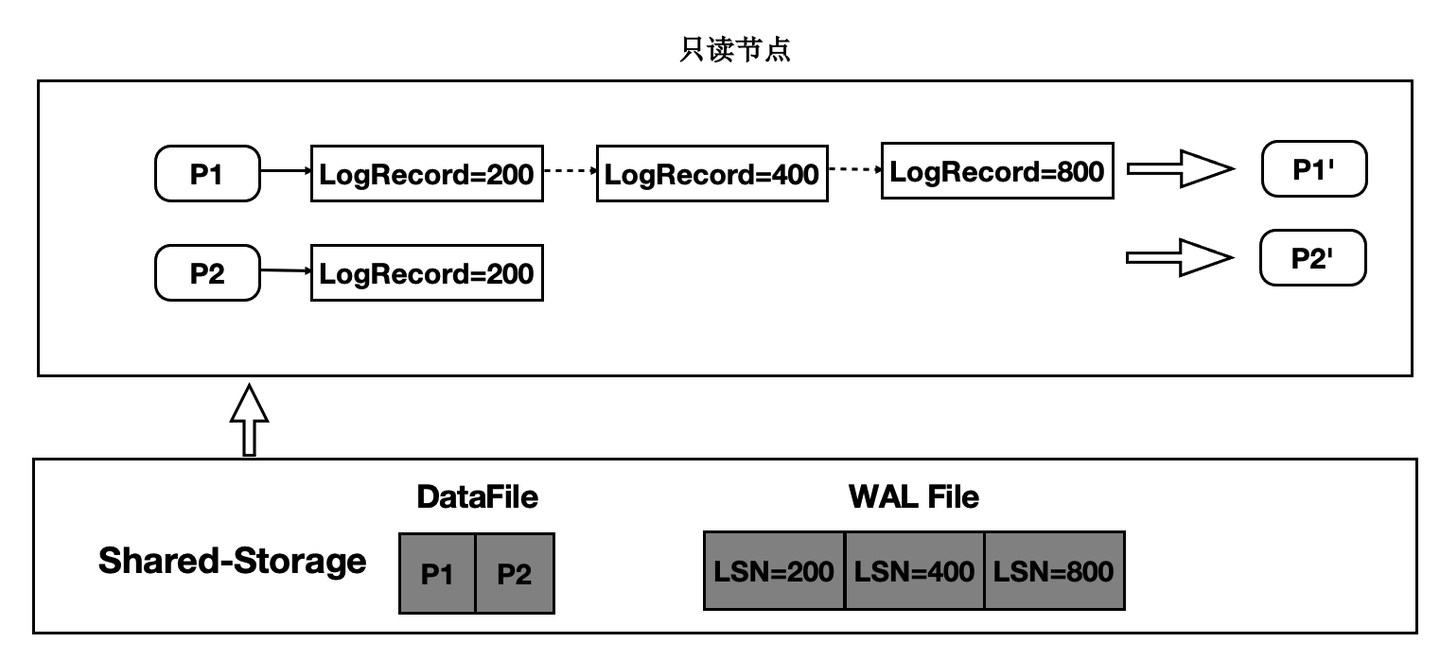
传统数据库的主备架构,主备有各自的存储,备节点回放WAL日志并读写自己的存储,主备节点在存储层没有耦合。PolarDB的实现是基于共享存储的一写多读架构,主备使用共享存储中的一份数据。读写节点,也称为主节点或Primary节点,可以读写共享存储中的数据;只读节点,也称为备节点或Replica节点,仅能各自通过回放日志,从共享存储中读取数据,而不能写入。基本架构图如下所示:
一写多读架构下,只读节点可能从共享存储中读到两类数据页:
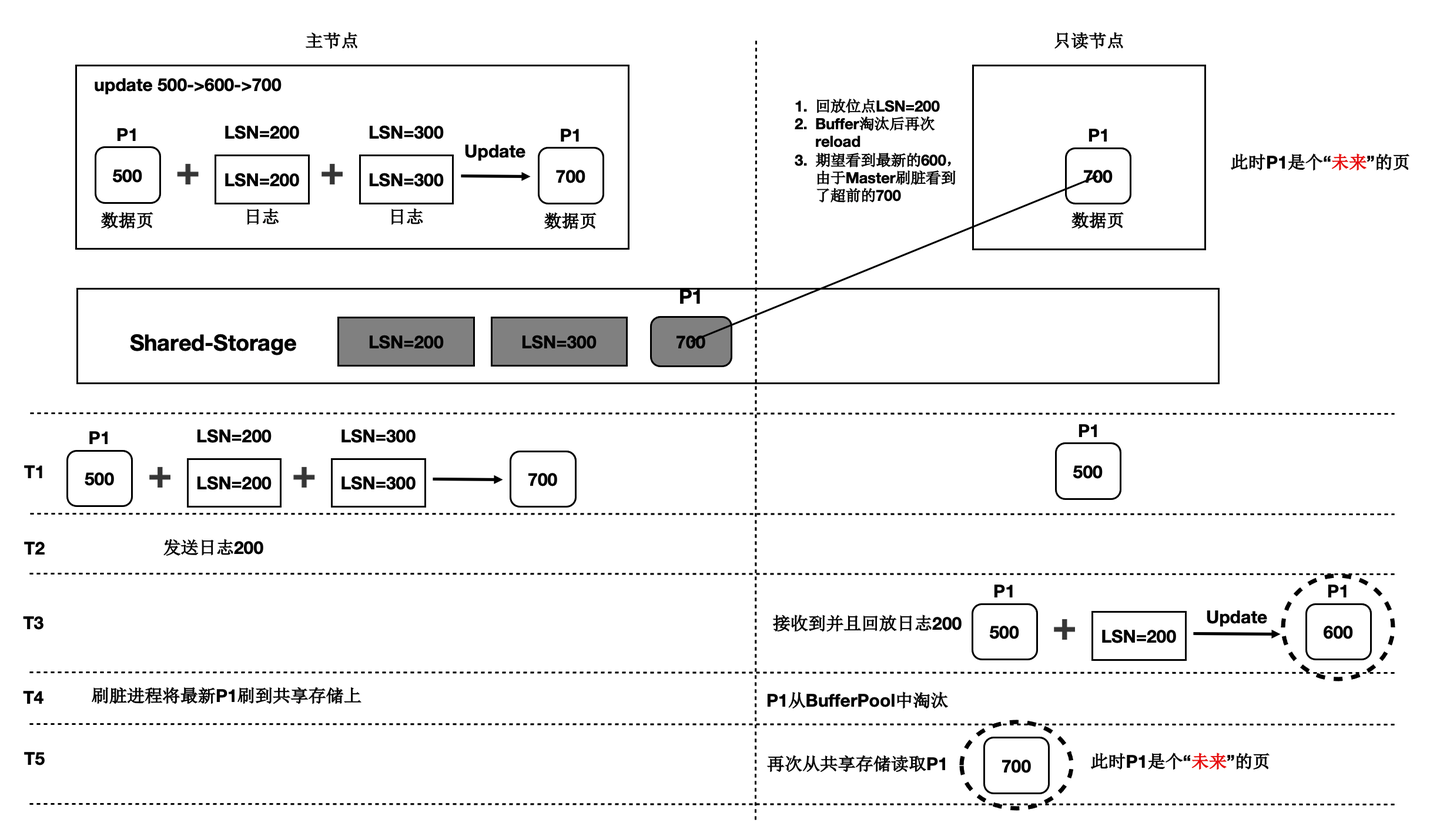
- 未来页:数据页中包含只读节点尚未回放到的数据,比如只读节点回放到LSN为200的WAL日志,但数据页中已经包含LSN为300的WAL日志对应的改动。此类数据页被称为“未来页”。
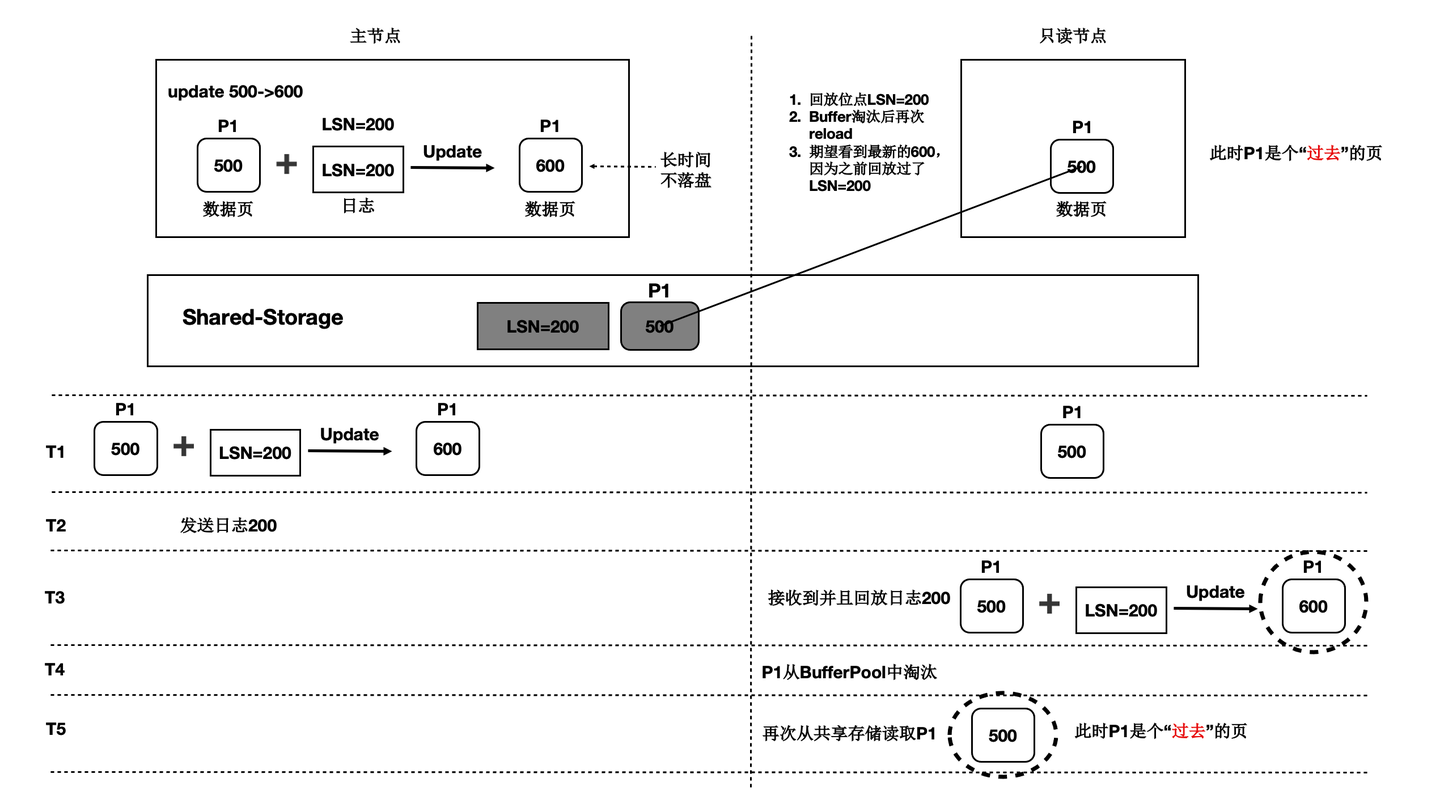
- 过去页:数据页中未包含所有回放位点之前的改动,比如只读节点将数据页回放到LSN为200的WAL日志,但该数据页在从Buffer Pool淘汰之后,再次从共享存储中读取的数据页中没有包含LSN为200的WAL日志的改动,此类数据页被称为“过去页”。
对于只读节点而言,只需要访问与其回放位点相对应的数据页。如果读取到如上所述的“未来页”和“过去页”应该如何处理呢?
- 对于“过去页”,只读节点需要回放数据页上截止回放位点之前缺失的WAL日志,对“过去页”的回放由每个只读节点根据自己的回放位点完成,属于只读节点回放功能,本文暂不讨论。
- 对于“未来页”,只读节点无法将“未来”的数据页转换为所需的数据页,因此需要在主节点将数据写入共享存储时考虑所有只读节点的回放情况,从而避免只读节点读取到“未来页”,这也是Buffer管理要解决的主要问题。
除此之外,Buffer管理还需要维护一致性位点,对于某个数据页,只读节点仅需回放一致性位点和当前回放位点之间的WAL日志即可,从而加速回放效率。
术语解释
- Buffer Pool:缓冲池,是一种内存结构用来存储最常访问的数据,通常以页为单位来缓存数据。PolarDB中每个节点都有自己的Buffer Pool。
- LSN:Log Sequence Number,日志序列号,是WAL日志的唯一标识。LSN在全局是递增的。
- 回放位点:Apply LSN,表示只读节点回放日志的位置,一般用LSN来标记。
- 最老回放位点:Oldest Apply LSN,表示所有只读节点中LSN最小的回放位点。
刷脏控制
为避免只读节点读取到“未来页”,PolarDB引入刷脏控制功能,即在主节点要将数据页写入共享存储时,判断所有只读节点是否均已回放到该数据页最近一次修改对应的WAL日志。
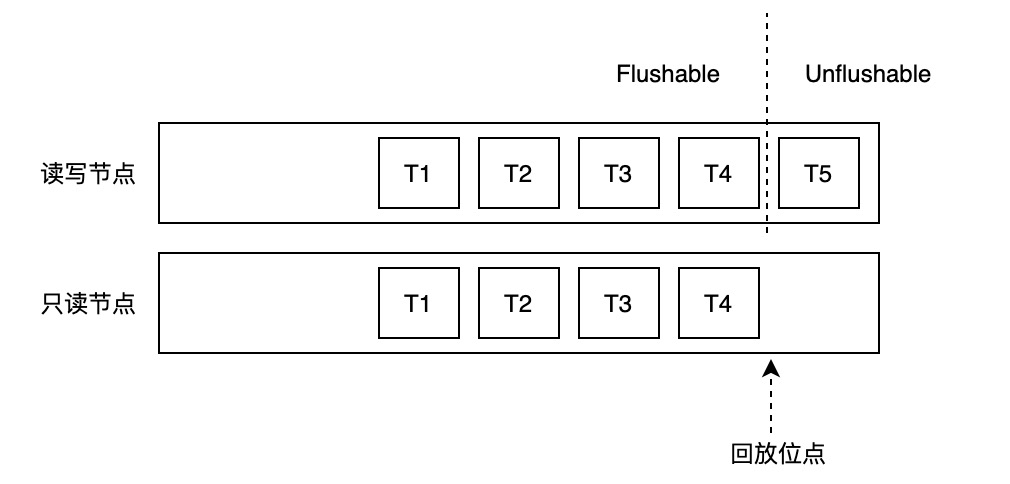
主节点Buffer Pool中的数据页,根据是否包含“未来数据”(即只读节点的回放位点之后新产生的数据),可以分为两类:可以写入存储的和不能写入存储的。该判断依赖两个位点:
- Buffer最近一次修改对应的LSN,我们称之为Buffer Latest LSN。
- 最老回放位点,即所有只读节点中最小的回放位点,我们称之为Oldest Apply LSN。
刷脏控制判断规则如下:
if buffer latest lsn <= oldest apply lsn
flush buffer
else
do not flush buffer一致性位点
为将数据页回放到指定的LSN位点,只读节点会维护数据页与该页上的LSN的映射关系,这种映射关系保存在LogIndex中。LogIndex可以理解为是一种可以持久化存储的HashTable。访问数据页时,会从该映射关系中获取数据页需要回放的所有LSN,依次回放对应的WAL日志,最终生成需要使用的数据页。
可见,数据页上的修改越多,其对应的LSN也越多,回放所需耗时也越长。为了尽量减少数据页需要回放的LSN数量,PolarDB中引入了一致性位点的概念。
一致性位点表示该位点之前的所有WAL日志修改的数据页均已经持久化到存储。主备之间,主节点向备节点发送当前WAL日志的写入位点和一致性位点,备节点向主节点发送当前回放的位点。由于一致性位点之前的WAL修改都已经写入共享存储,备节点无需再回放该位点之前的WAL日志。因此,可以将LogIndex中所有小于一致性位点的LSN清理掉,既加速回放效率,同时还能减少LogIndex占用的空间。
FlushList
为维护一致性位点,PolarDB为每个Buffer引入了一个内存状态,即第一次修改该Buffer对应的LSN,称之为oldest LSN,所有Buffer中最小的oldest LSN即为一致性位点。
一种获取一致性位点的方法是遍历Buffer Pool中所有Buffer,找到最小值,但遍历代价较大,CPU开销和耗时都不能接受。为高效获取一致性位点,PolarDB引入FlushList机制,将Buffer Pool中所有脏页按照oldest LSN从小到大排序。借助FlushList,获取一致性位点的时间复杂度可以达到 O(1)。
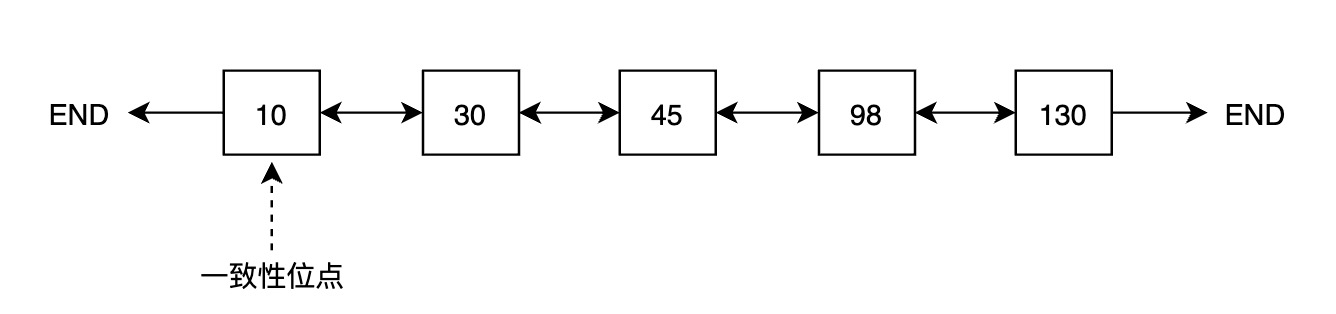
第一次修改Buffer并将其标记为脏时,将该Buffer插入到FlushList中,并设置其oldest LSN。Buffer被写入存储时,将该内存中的标记清除。
为高效推进一致性位点,PolarDB的后台刷脏进程(bgwriter)采用“先被修改的Buffer先落盘”的刷脏策略,即bgwriter会从前往后遍历FlushList,逐个刷脏,一旦有脏页写入存储,一致性位点就可以向前推进。以上图为例,如果oldest LSN为10的Buffer落盘,一致性位点就可以推进到30。
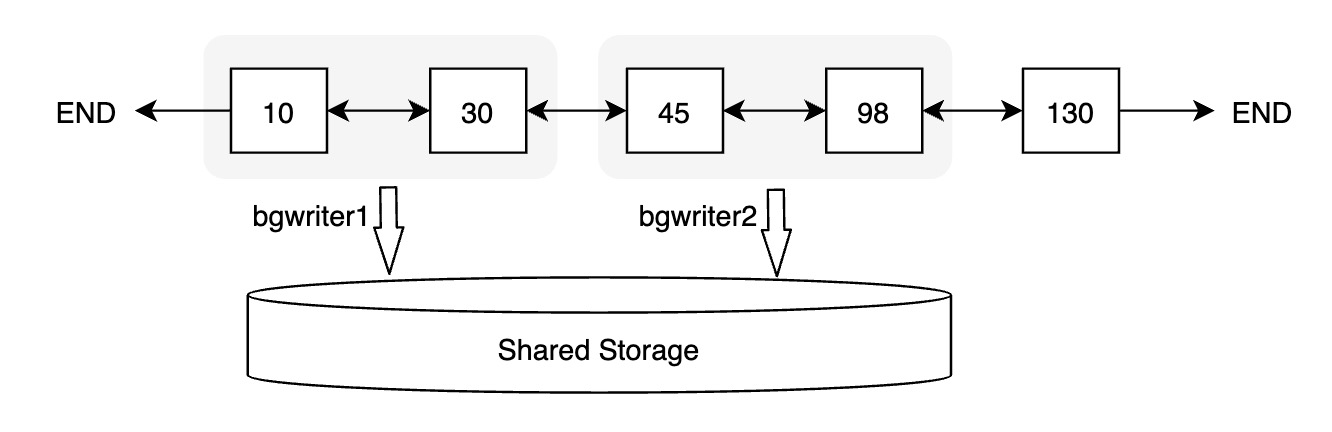
并行刷脏
为进一步提升一致性位点的推进效率,PolarDB实现了并行刷脏。每个后台刷脏进程会从FlushList中获取一批数据页进行刷脏。
热点页
引入刷脏控制之后,仅满足刷脏条件的Buffer才能写入存储,假如某个Buffer修改非常频繁,可能导致Buffer Latest LSN总是大于Oldest Apply LSN,该Buffer始终无法满足刷脏条件,此类Buffer我们称之为热点页。热点页会导致一致性位点无法推进,为解决热点页的刷脏问题,PolarDB引入了Copy Buffer机制。
Copy Buffer机制会将特定的、不满足刷脏条件的Buffer从Buffer Pool中拷贝至新增的Copy Buffer Pool中,Copy Buffer Pool中的Buffer不会再被修改,其对应的Latest LSN也不会更新,随着Oldest Apply LSN的推进,Copy Buffer会逐步满足刷脏条件,从而可以将Copy Buffer落盘。
引入Copy Buffer机制后,刷脏的流程如下:
- 如果Buffer不满足刷脏条件,判断其最近修改次数以及距离当前日志位点的距离,超过一定阈值,则将当前数据页拷贝一份至Copy Buffer Pool中。
- 下次再刷该Buffer时,判断其是否满足刷脏条件,如果满足,则将该Buffer写入存储并释放其对应的Copy Buffer。
- 如果Buffer不满足刷脏条件,则判断其是否存在Copy Buffer,若存在且Copy Buffer满足刷脏条件,则将Copy Buffer落盘。
- Buffer被拷贝到Copy Buffer Pool之后,如果有对该Buffer的修改,则会重新生成该Buffer的Oldest LSN,并将其追加到FlushList末尾。
如下图中,[oldest LSN, latest LSN] 为 [30, 500] 的Buffer被认为是热点页,将当前Buffer拷贝至Copy Buffer Pool中,随后该数据页再次被修改,假设修改对应的LSN为600,则设置其Oldest LSN为600,并将其从FlushList中删除,然后追加至FlushList末尾。此时,Copy Buffer中数据页不会再修改,其Latest LSN始终为500,若满足刷脏条件,则可以将Copy Buffer写入存储。
 需要注意的是,引入Copy Buffer之后,一致性位点的计算方法有所改变。FlushList中的Oldest LSN不再是最小的Oldest LSN,Copy Buffer Pool中可能存在更小的oldest LSN,因此,除考虑FlushList中的Oldest LSN之外,还需要遍历Copy Buffer Pool,找到Copy Buffer Pool中最小的Oldest LSN,取两者的最小值即为一致性位点。
Lazy Checkpoint
PolarDB引入的一致性位点概念,与checkpoint的概念类似。PolarDB中checkpoint位点表示该位点之前的所有数据都已经落盘,数据库Crash Recovery时可以从checkpoint位点开始恢复,提升恢复效率。普通的checkpoint会将所有Buffer Pool中的脏页以及其他内存数据落盘,这个过程可能耗时较长且在此期间IO吞吐较大,可能会对正常的业务请求产生影响。
借助一致性位点,PolarDB中引入了一种特殊的checkpoint,Lazy Checkpoint。之所以称之为Lazy(懒惰的),是与普通的checkpoint相比,lazy checkpoint不会把Buffer Pool中所有的脏页落盘,而是直接使用当前的一致性位点作为checkpoint位点,极大地提升了checkpoint的执行效率。
Lazy Checkpoint的整体思路是将普通checkpoint一次性刷大量脏页落盘的逻辑转换为后台刷脏进程持续不断落盘并维护一致性位点的逻辑。需要注意的是,Lazy Checkpoint与PolarDB中Full Page Write的功能有冲突,开启Full Page Write之后会自动关闭该功能。
企业级分布式开源数据库 PolarDB for PostgreSQL-阿里云开发者社区
PolarDB PostgreSQL Buffer Management 原理的更多相关文章
- PolarDB PostgreSQL DDL同步原理
概述 在共享存储一写多读的架构下,数据文件实际上只有一份.得益于多版本机制,不同节点的读写实际上并不会冲突.但是有一些数据操作不具有多版本机制,其中比较有代表性的就是文件操作.多版本机制仅限于文件内的 ...
- PolarDB PostgreSQL 架构原理解读
背景 PolarDB PostgreSQL(以下简称PolarDB)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容PostgreSQL与Oracle.PolarDB 的存储与计算能 ...
- PolarDB PostgreSQL 快速入门
什么是PolarDB PostgreSQL PolarDB PostgreSQL(下文简称为PolarDB)是一款阿里云自主研发的云原生数据库产品,100%兼容PostgreSQL,采用基于Share ...
- Lock-less buffer management scheme for telecommunication network applications
A buffer management mechanism in a multi-core processor for use on a modem in a telecommunications n ...
- Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
前言 习惯用 Json.XML 数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer 其实 是 Google出品的一种轻量 & 高效的结构化数据存 ...
- PolarDB PostgreSQL logindex 设计
背景介绍 PolarDB采用了共享存储一写多读架构,读写节点RW和多个只读节点RO共享同一份存储,读写节点可以读写共享存储中的数据:只读节点仅能各自通过回放日志,从共享存储中读取数据,而不能写入,只读 ...
- Shp数据批量导入Postgresql工具的原理和设计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.背景 在制作整体的开源工具箱产品中,数据入库是一个重要的环节.虽然 ...
- Buffer Cache 原理
在将数据块读入到SGA中,他们的缓冲区被放置在悬挂散列存储桶的链表中(散列链),这种内存结构由大量 子cache buffers chains锁存器(也称为散列锁存器或CBC锁存器)保护. Buffe ...
- google protocol buffer的原理和使用(二)
本文主要会介绍怎么使用Google Protocol的Lib来序列化我们的数据,方法非常多种,本文仅仅介绍当中的三种.其它的方法读者能够通过自行研究摸索.但总的来说,序列化数据总的来说分为下面俩步: ...
随机推荐
- 单链表(Java--尚硅谷)
基础知识 大体结构和C++的链表差不多 补充之前不知道的:链表分两类,带和不带头结点的链表 现在才知道,Java没有像C/C++那样的指针 首先创建一个LinkList类,然后把链表的各个功能添加进去 ...
- Qt 中事件与处理
一.事件与处理程序在运算过程中发生的一些事情:鼠标单击.键盘的按下...这些的事件的监控与处理在Qt中不是以信号的方式处理的.当这些事件发生时会调用QObject类中的功能函数(虚函数),所有的控件类 ...
- hdfs中数据迁移
1.hdfs集群间数据迁移 hadoop distcp hdfs://192.128.112.66:8020/user/hive/warehouse/data.db/dwi_xxxx_d /user ...
- MAC下Jetbrains编译器无法打开问题解决
这段时间不知道怎么回事,每次打开Rider必定闪退,毫无头绪,只好暂时放弃使用Rider,试用了一段时间Visual Studio. 可惜...虽然大学时候觉得VS天下第一,但是用惯了JB的编译器,再 ...
- java深度复制
索要克隆的类必须实现:Serializable,Cloneable接口import java.io.ByteArrayInputStream; import java.io.ByteArrayOutp ...
- 新东方集团K12公益免费课战役记
作者:张建鑫, 曾任IBM高级软件架构师, 滴滴高级技术专家, 现任新东方集团高级技术总监 1月31日,集团领导决定由产品技术中心的新东方APP团队牵头做周一到周五的集团公益课, 提供给全国中小学生使 ...
- Kickstart部署之HTTP架构
原文转自:https://www.cnblogs.com/itzgr/p/10029527.html作者:木二 目录 一 准备 1.1 完整架构:Kickstart+DHCP+HTTP+TFTP+PX ...
- LVS实现(VS/DR)负载均衡和Keepalived高可用
LVS是Linux Virtual Server的简写即Linux虚拟服务器,是一个虚拟的服务器集群系统一组服务器通过高速的局域网或者地理分布的广域网相互连接,在它们的前端有一个负载调度器(Load ...
- Python - 面向对象编程 - 小实战(3)
需求 房子(House)有户型.总面积.家具名称列表:新房子没有任何的家具 家具(HouseItem)有名字.占地面积 席梦思(bed) 占地 4 平米 衣柜(bed) 占地 2 平米 餐桌(bed) ...
- awk工作流程
awk 工作过程:先执行BEGIN模块,再跟文本交互,最后执行END模块.也就是说BEGIN/END模块,这俩是单独操作跟文本是同一级,但执行有优先级,BEGIN模块>文本>END模块 行 ...