Spark 实践——音乐推荐和 Audioscrobbler 数据集
本文基于《Spark 高级数据分析》第3章 用音乐推荐和Audioscrobbler数据
完整代码见 https://github.com/libaoquan95/aasPractice/tree/master/c3/recommend
1.获取数据集
本 章 示 例 使 用 Audioscrobbler 公 开 发 布 的 一 个 数 据 集。 Audioscrobbler 是 last.fm 的 第一个音乐推荐系统。 last.fm 创建于 2002 年,是最早的互联网流媒体广播站点之一。
Audioscrobbler 数据集有些特别, 因为它只记录了播放数据,主要的数据集在文件 user_artist_data.txt 中,它包含 141 000 个用户和 160 万个艺术家,记录了约 2420 万条用户播放艺术家歌曲的信息,其中包括播放次
数信息。数据集在 artist_data.txt 文件中给出了每个艺术家的 ID 和对应的名字。请注意,记录播放信息时,客户端应用提交的是艺术家的名字。名字如果有拼写错误,或使用了非标准的名称, 事后才能被发现。 比如,“The Smiths”“Smiths, The”和“the smiths”看似代表不同艺术家的 ID,但它们其实明显是指同一个艺术家。因此,为了将拼写错误的艺术家 ID 或ID 变体对应到该艺术家的规范 ID,数据集提供了 artist_alias.txt 文件。
下载地址:
- http://www-etud.iro.umontreal.ca/~bergstrj/audioscrobbler_data.html (原书地址,已失效)
- https://github.com/libaoquan95/aasPractice/tree/master/c3/profiledata_06-May-2005(数据集大于git上传限制,分卷压缩)
2.数据处理
加载数据集
val dataDirBase = "profiledata_06-May-2005/"
val rawUserArtistData = sc.read.textFile(dataDirBase + "user_artist_data.txt")
val rawArtistData = sc.read.textFile(dataDirBase + "artist_data.txt")
val rawArtistAlias = sc.read.textFile(dataDirBase + "artist_alias.txt")
rawUserArtistData.show()
rawArtistData.show()
rawArtistAlias.show()
格式化数据集,转换成 DataFrame
val artistByID = rawArtistData.flatMap { line =>
val (id, name) = line.span(_ != '\t')
if (name.isEmpty()){
None
} else {
try {
Some((id.toInt, name.trim))
} catch{
case _: NumberFormatException => None
}
}
}.toDF("id", "name").cache()
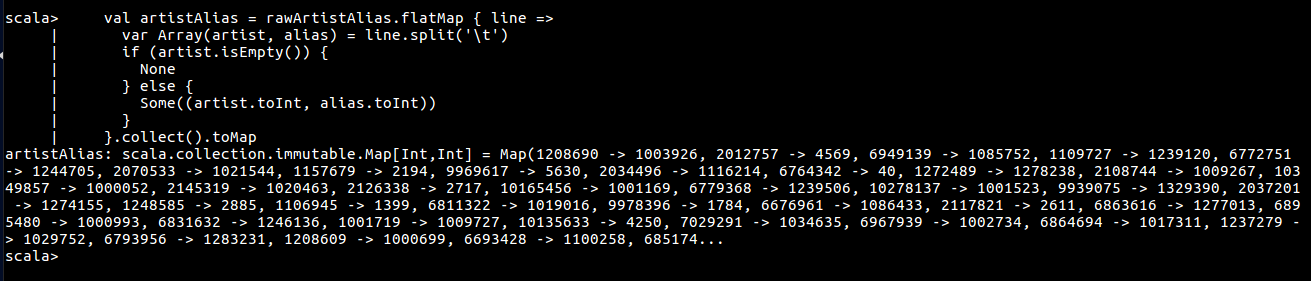
val artistAlias = rawArtistAlias.flatMap { line =>
var Array(artist, alias) = line.split('\t')
if (artist.isEmpty()) {
None
} else {
Some((artist.toInt, alias.toInt))
}
}.collect().toMap
val bArtistAlias = sc.sparkContext.broadcast(artistAlias)
val userArtistDF = rawUserArtistData.map { line =>
val Array(userId, artistID, count) = line.split(' ').map(_.toInt)
val finalArtistID = bArtistAlias.value.getOrElse(artistID, artistID)
(userId, artistID, count)
}.toDF("user", "artist", "count").cache()

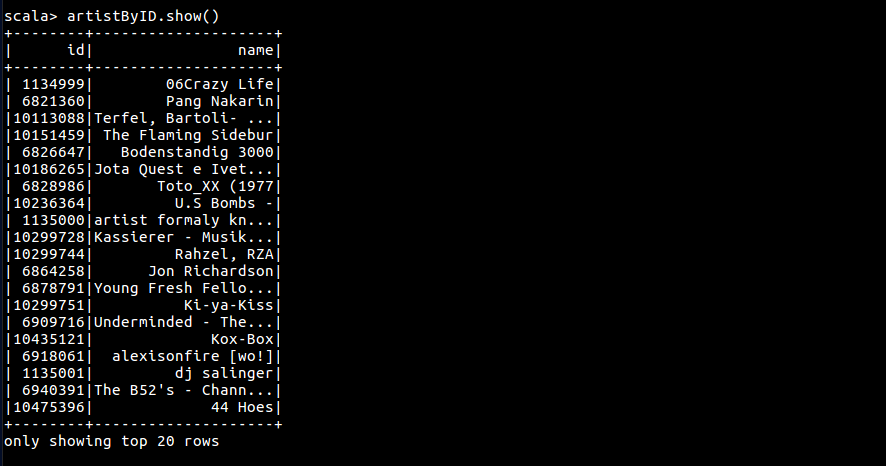
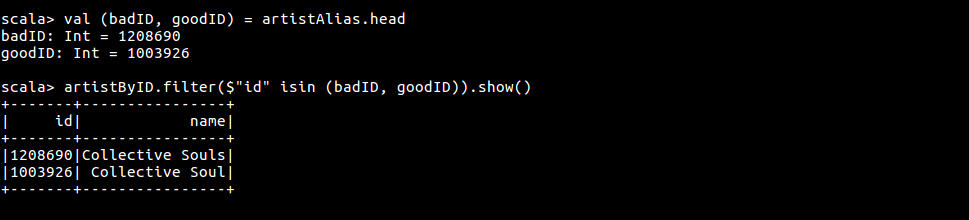
查看 artist 别名与实名
val (badID, goodID) = artistAlias.head
artistByID.filter($"id" isin (badID, goodID)).show()
3.利用 Spark MLlib 进行推荐
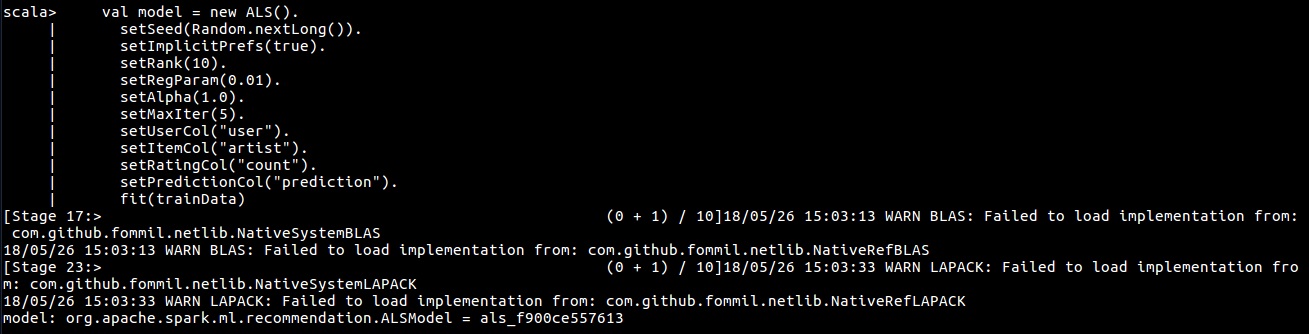
Spark MLlib 使用 ALS (交替最小二乘) 来实现协同过滤算法,该模型只需传入三元组 (用户ID, 物品ID, 评分) 就可以进行计算,需要注意,用户ID 和 物品ID必须是整型数据。
val Array(trainData, cvData) = userArtistDF.randomSplit(Array(0.9, 0.1))
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("artist").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
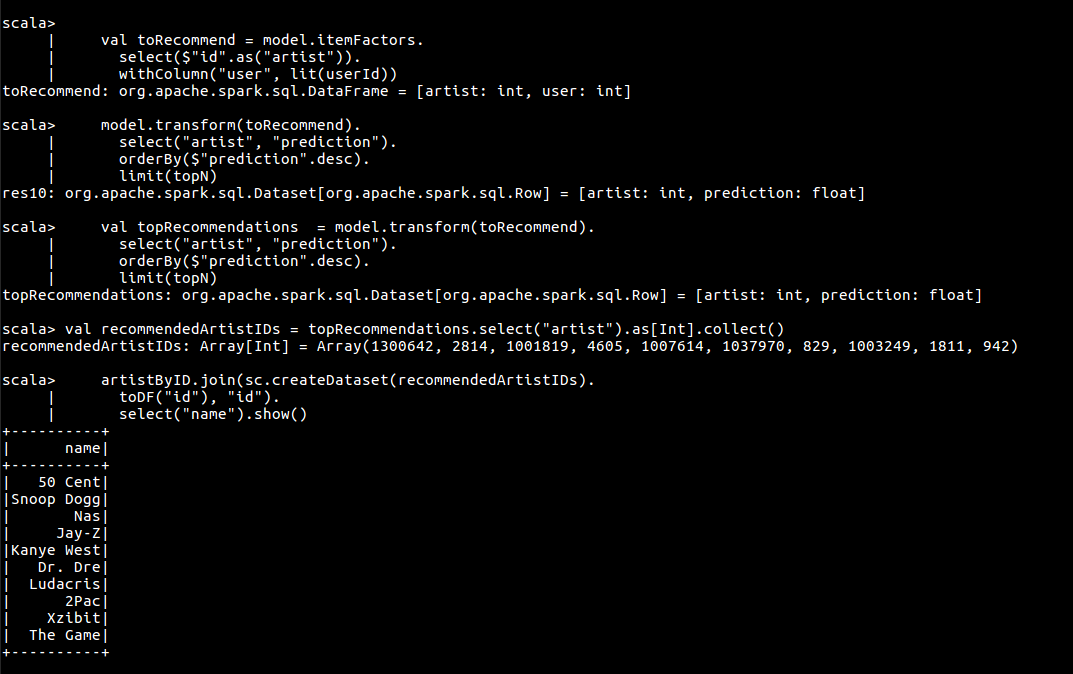
推荐模型已经搭建完成,不过 Spark MLlib 每次只能对单个用户进行推荐,无法进行单次的全局推荐。
val userId = 2093760
val topN = 10
val toRecommend = model.itemFactors.
select($"id".as("artist")).
withColumn("user", lit(userId))
val topRecommendations = model.transform(toRecommend).
select("artist", "prediction").
orderBy($"prediction".desc).
limit(topN)
// 查看推荐结果
val recommendedArtistIDs = topRecommendations.select("artist").as[Int].collect()
artistByID.join(sc.createDataset(recommendedArtistIDs).
toDF("id"), "id").
select("name").show()
Spark 实践——音乐推荐和 Audioscrobbler 数据集的更多相关文章
- 音乐推荐与Audioscrobbler数据集
1. Audioscrobbler数据集 数据下载地址: http://www.iro.umontreal.ca/~lisa/datasets/profiledata_06-May-2005.tar. ...
- 3-Spark高级数据分析-第三章 音乐推荐和Audioscrobbler数据集
偏好是无法度量的. 相比其他的机器学习算法,推荐引擎的输出更直观,更容易理解. 接下来三章主要讲述Spark中主要的机器学习算法.其中一章围绕推荐引擎展开,主要介绍音乐推荐.在随后的章节中我们先介绍S ...
- ALS音乐推荐(上)
本篇文章的开头笔者提出一个疑问,何为数据科学,数据科学是做什么的?大家带着这个疑问去读接下来的这篇音乐推荐的公众号. 从经验上讲,推荐引擎属于大规模机器学习,在日常购物中大家或许深有体会,比如:你在淘 ...
- Recommending music on Spotify with deep learning 采用深度学习算法为Spotify做基于内容的音乐推荐
本文参考http://blog.csdn.net/zdy0_2004/article/details/43896015译文以及原文file:///F:/%E6%9C%BA%E5%99%A8%E5%AD ...
- 个推 Spark实践教你绕过开发那些“坑”
Spark作为一个开源数据处理框架,它在数据计算过程中把中间数据直接缓存到内存里,能大大提高处理速度,特别是复杂的迭代计算.Spark主要包括SparkSQL,SparkStreaming,Spark ...
- Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统
1.前言 上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐 ...
- 推荐系统实践 0x05 推荐数据集MovieLens及评测
推荐数据集MovieLens及评测 数据集简介 MoiveLens是GroupLens Research收集并发布的关于电影评分的数据集,规模也比较大,为了让我们的实验快速有效的进行,我们选取了发布于 ...
- MongoDB,HDFS, Spark to 电影推荐
http://www.infoq.com/cn/news/2014/12/mongdb-spark-movie-recommend MovieWeb是一个电影相关的网站,它提供的功能包括搜索电影信息. ...
- Spark实践 -- 性能优化基础
性能调优相关的原理讲解.经验总结: 掌握一整套Spark企业级性能调优解决方案:而不只是简单的一些性能调优技巧. 针对写好的spark作业,实施一整套数据倾斜解决方案:实际经验中积累的数据倾斜现象的表 ...
随机推荐
- 【转】Poco 1.4.2 HTTPClientSession/HTTPRequest 使用使用代理(proxy)需要注意的一点
Poco 1.4.2 HTTPClientSession/HTTPClientSession 在使用代理的时候,request的URI不能包含协议和主机.否则会出错. 不使用代理的时候,以下代码能正常 ...
- 密码破解技术——P201421410029
学 号 201421410029 中国人民公安大学 Chinese people’ public security university 网络对抗技术 实验报告 实验三 密码破解技术 ...
- svn 更新提交文件冲突
文件冲突定义:svn up更新服务器文档到本地的时候发现本地的文件有所改动,和svn服务器不同步 服务器会报冲突,让你觉得已谁的为准,根据实际情况我们需要选择是以服务器还是以本地代码为准 报错: Co ...
- 【转】SQL 常用关键字释义和用法
转自: http://blog.csdn.net/iamwangch/article/details/8093933 下面 是 从网络上整理 出来的 SQL 关键字和 常用函数的 释义和简单用 ...
- Python2.7-collections
collections 模块主要提供了五种特殊类型容器,此外还提供了许多抽象基类用于检查类的接口 1.Counter 对象,主要用于统计出现次数,是dict的一个子类,用法与形式和 dict 很类似 ...
- poj 3169 Layout(线性差分约束,spfa:跑最短路+判断负环)
Layout Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 15349 Accepted: 7379 Descripti ...
- php判断一个数组是否为另一个数组子集的方法
原文地址http://www.jbxue.com/article/14703.html // 快速的判断$a数组是否是$b数组的子集 $a = array(135,138); $b = array ...
- Linux SSH远程文件/文件夹传输命令scp
相信各位VPSer在使用VPS时会常常在不同VPS间互相备份数据或者转移数据,大部分情况下VPS上都已经安装了Nginx或者类似的web server,直接将要传输的文件放到web server的文件 ...
- 20155210 实验一 逆向与Bof基础
20155210 实验一 逆向与Bof基础 实验内容 1.直接修改程序机器指令,改变程序执行流程 下载目标文件pwn1,反汇编 利用objdump -d pwn1对pwn1进行反汇编 得到: 8048 ...
- vue build,本地正常访问,服务器上,网页一刷新是404,解决办法
服务器报错如下图: 此原因,是服务器配置的原因,跟build代码本身无关 以ftp为例,在/etc/nginx/conf.d文件夹下,找到xxx.conf,修改成自己需要的路径即可 位置如下两张图: