机器学习实战-ch3-决策树
决策树是一种新算法:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。决策树算法可用于数据类型:数值型和标称型。

决策树的核心在于选择正确的属性对数据进行划分。选择的标准是数据增益。信息增益:讲无序的数据变得更加有序。
信息增益熵:如果把X分成n个类,每个类的概率为p(i),那么-log(p(i))的期望就是熵。
如果分成1类,则熵为0,表示没有增益。
如果分成两类,各占1半,熵为1;
如果分成4类,各占1/4,则熵为2;
可以直观的感觉分成类越多,熵就越大。
---
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
按照最后一个属性划分,熵为0.97
加上一个元素[1,1,’maybe’],熵就变成1.47
-----
为了计算数据增益,需要定义一个子函数。按照特定的维度,以及维度上的值,划分dataSet。
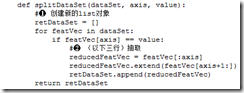
-----
利用上面的子函数可以选择增益最大的维度。
对每个维度di进行遍历
对di上的value进行切分,得到k个集合
计算一个熵si
选择最大的si,对应的维度就是用来做决策的维度。
-----
每次选择一个维度后,对应的维度就会从数据集消失。然后dataSet分成若干个小集合。如果某个dataSet子集中所有元素label一致,则不需要再次划分。否则继续选择增益最大的属性继续划分。直到构成完整的决策树。
机器学习实战-ch3-决策树的更多相关文章
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
- 【Python机器学习实战】决策树和集成学习(二)——决策树的实现
摘要:上一节对决策树的基本原理进行了梳理,本节主要根据其原理做一个逻辑的实现,然后调用sklearn的包实现决策树分类. 这里主要是对分类树的决策进行实现,算法采用ID3,即以信息增益作为划分标准进行 ...
- 【Python机器学习实战】决策树与集成学习(四)——集成学习(2)GBDT
本打算将GBDT和XGBoost放在一起,但由于涉及内容较多,且两个都是比较重要的算法,这里主要先看GBDT算法,XGBoost是GBDT算法的优化和变种,等熟悉GBDT后再去理解XGBoost就会容 ...
- 【Python机器学习实战】决策树与集成学习(六)——集成学习(4)XGBoost原理篇
XGBoost是陈天奇等人开发的一个开源项目,前文提到XGBoost是GBDT的一种提升和变异形式,其本质上还是一个GBDT,但力争将GBDT的性能发挥到极致,因此这里的X指代的"Extre ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- 机器学习实战python3 决策树ID3
代码及数据:https://github.com/zle1992/MachineLearningInAction 决策树 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特 ...
- 机器学习实战:决策树的存储读写文件报错(Python3)
错误原因:pickle模块存储的是二进制字节码,需要以二进制的方式进行读写 1. 报错一:TypeError: write() argument must be str, not bytes 将决策树 ...
- 03机器学习实战之决策树scikit-learn实现
sklearn.tree.DecisionTreeClassifier 基于 scikit-learn 的决策树分类模型 DecisionTreeClassifier 进行的分类运算 http://s ...
- 【Python机器学习实战】决策树与集成学习(三)——集成学习(1)
前面介绍了决策树的相关原理和实现,其实集成学习并非是由决策树演变而来,之所以从决策树引申至集成学习是因为常见的一些集成学习算法与决策树有关比如随机森林.GBDT以及GBDT的升华版Xgboost都是以 ...
随机推荐
- How to Set Ckeditor ReadOnly Mode
CKEditor API makes it possible to render the editor content read-only (and thus impossible for the u ...
- Python之paramiko模块
今天我们来了解一下python的paramiko模块 paramiko是python基于SSH用于远程服务器并执行相应的操作. 我们先在windows下安装paramiko 1.cmd下用pip安装p ...
- 【附源文件】软件工具类Web原型制作分享 - Sketch
Sketch是一款轻量,易用的矢量设计工具.专门为UI设计师开发,让UI设计更简单.更高效. 本原型由国产原型工具-Mockplus制作完成. 非常适合工具类产品官网使用,本模板的交互有通过使用面板组 ...
- https的名词解释
原文 http://www.cnblogs.com/guogangj/p/4118605.html 那些证书相关的玩意儿(SSL,X.509,PEM,DER,CRT,CER,KEY,CSR,P12等) ...
- 2018.11.17 bzoj4259: 残缺的字符串(fft)
传送门 fftfftfft套路题. 我们把aaa ~ zzz映射成111 ~ 262626,然后把∗*∗映射成000. 考虑对于两个长度都为nnn的字符串A,BA,BA,B. 我们定义一个差异函数di ...
- 2018.11.06 bzoj1093: [ZJOI2007]最大半连通子图(缩点+拓扑排序)
传送门 先将原图缩点,缩掉之后的点权就是连通块大小. 然后用拓扑排序统计最长链数就行了. 自己yyyyyy了一下一个好一点的统计方法. 把所有缩了之后的点都连向一个虚点. 然后再跑拓扑,这样最后虚点的 ...
- C++之输出100-200内的素数
素数(质数) 除了1和它本身以外不再被其他的除数整除. // 输出100--200内的素数 #include<iostream> using namespace std; int m ...
- mysql学习之路_乱码问题
中文数据问题: 中文数据问题本质就说字符集问题, 计算机只识别二进制,人类识别符号:需要友谊个二进制与字符对应关系(字符集). 报错:服务器没有识别对应的四个字节. 服务器认为的数据是utf—8,一个 ...
- 第08章:MongoDB-CRUD操作--文档--删除
①语法 remove() [2.6以后方法过时] deleteOne() [2.6以后官方推荐] deleteMany() [2.6以后官方推荐] db.collection.remove( < ...
- 链家web前端面试
共有三轮面试,每个面试官的第一个问题都是:介绍一个你觉着比较出彩的项目 第一轮面试: 因为公司项目没什么亮点,很传统的pc端,美女面试官就说让讲一下我用react的私人项目; 问了很多都是关于reac ...