python与中文的那点事
python与中文的那点事
在学习python的过程中,发现在python2与python3中对中文的处理有所不同,所以这篇文章就来探讨一下这些不同
1. utf-8/gbk/unicode/ASCII
我们都知道,在计算机内部所有的信息都可以被表示成二进制的字符串,每一个二进制位有1和0两种状态,因此8位的二进制数可以表示256种状态,这也被称为字节(byte),也就是一个字节可以表示可以用来表示256种不同的状态,每一个状态都对应一个符号;上个年代美国制定了一套字符编码,对应英文字母与二进制之间的关系,做了统一的规定。这被称为ASCII,一直沿用至今。
当然设计上存在很多的编码方式,同一个二进制也可以被解释成不同的符号,因此想要打开一个文件就必须要知道它的编码方式,否则用错误的编码方式进行读取,就会产生乱码。所以说如果有一种编码,能适应世界上所有的编码规则,那么就可以解决掉所有的乱码问题。所以Unicode这套编码规则就被设计出来了,Unicode当然是一个很大的合集,可以容纳100多万个符号,每个符号的编码都不一样,但是要注意到的是,Unicode只是一个符号集,他并没有规定这个二进制如何去存储,所以有些字符是用2个字节存储,有的是三个或者四个字节进行存储,甚至更多。那么这样的话就会有一个问题,就是计算机应该如何确定到底是三位字节决定一个符号,还是两字节决定一个符号。这样造成的结果就是会产生多种的Unicode编码方式,也就是说有不同的二进制格式,所以不能进行有效的推广。
随着互联网的普及,需要一种能够统一的编码方式,utf-8就是在互联网上是用最广的一种Unicode实现的方法,其他方法还有UFT-18和UTF-32,不过现在在互联网上基本不是很通用,所以要强调的是UTF-8是Unicode的一种实现方式。UTF-8最大的一个特点就是它是一种变长的编码模式;它可以用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
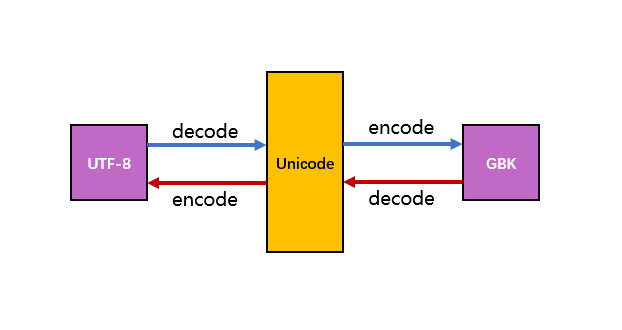
另外,UTF-8是Unix下的通用编码,可以对汉字进行编码;gbk是win环境下的一种汉字编码格式。所有的UTF-8和gbk编码都得通过Unicode编码进行转换,而UTF-8和gbk之间不能相互转换,要在Unicode过个场。
在下面代码中:
# -*- coding:utf-8 -*-
s='汉字'
print(s)
s是一串utf-8编码的汉字,在print的时候,先把utf-8转化成unicode再输出成正产显示的汉字。
2.各种编码之间的转换
python中有两个很好用的函数decode()和encode()。
decode('utf-8') 是从utf-8编码转换成unicode编码,当然括号里也可以写'gbk'。
encode('gbk') 是将unicode编码编译成gbk编码,当然括号里也可以写'utf-8'。
假如我知道一串编码是用gbk编写的,怎么转成utf-8呢?
s.decode('utf-8').encode('gbk')
那么这样就有一个有意思的小问题,如何看一个汉字分别用utf-8和gbk编码所用的位数,我们用代码演示一下:
#python3 中可以直接进行编码
>>> len("测试代码".encode("utf-8"))
12
>>> len("测试代码".encode("gbk"))
8
#因为在Python3中默认就是unicode编码
#python2中需要先decode 一次
>>> len("测试代码".decode("utf-8").encode("utf-8"))
12
>>> len("测试代码".decode("utf-8").encode("gbk"))
8
Python3.0中默认的编码类型就是Unicode了,在python2.x中默认编码是ascill。
3. 统计字符串中数字,字母,汉字的个数
#re模块,实现正则匹配
import re
str_test = 'asdfghjkl123456测试代码'
num_regex = re.compile(r'[0-9]')
alphabet_regex = re.compile(r'[a-zA-z]')
chzn_regex = re.compile(r'[\u4E00-\u9FA5]')
print('输入字符串:',str_test)
#findall获取字符串中所有匹配的字符
num_list = num_regex.findall(str_test)
print('包含的数字:',num_list)
alphabet_list = alphabet_regex.findall(str_test)
print('包含的字母:',alphabet_list)
chzn_list = chzn_regex.findall(str_test)
print('包含的汉字:',chzn_list)
print('数字个数:',len(num_list))
print('字母个数:',len(alphabet_list))
print('汉字个数:',len(chzn_list))
输出结果:
输入字符串: asdfghjkl123456测试代码
包含的数字: ['1', '2', '3', '4', '5', '6']
包含的字母: ['a', 's', 'd', 'f', 'g', 'h', 'j', 'k', 'l']
包含的汉字: ['测', '试', '代', '码']
数字个数: 6
字母个数: 9
汉字个数: 4
python与中文的那点事的更多相关文章
- python处理中文
python 清洗中文文件 需要用到的两个链接: 1,unicode编码转换器 http://www.bangnishouji.com/tools/chtounicode.html 2,Python匹 ...
- python matplotlib 中文显示参数设置
python matplotlib 中文显示参数设置 方法一:每次编写代码时进行参数设置 #coding:utf-8import matplotlib.pyplot as pltplt.rcParam ...
- python截取中文字符串
python的中文处理还是比较麻烦的,utf-8的字符串的长度是1-6个字符,一不小心就会从中截断,出现所谓的乱码.下面这个函数提供了,从一段utf-8编码的字符串中,截取固定长度的字串.ord(ch ...
- python读取中文文件编码问题
python 读取中文文件后,作为参数使用,经常会遇到乱码或者报错asii错误等. 我们需要对中文进行decode('gbk') 如我有一个data.txt文件有如下内容: 百度 谷歌 现在想读取文件 ...
- 用python做中文自然语言预处理
这篇博客根据中文自然语言预处理的步骤分成几个板块.以做LDA实验为例,在处理数据之前,会写一个类似于实验报告的东西,用来指导做实验,OK,举例: 一,实验数据预处理(python,结巴分词)1.对于爬 ...
- 【转】Python BeautifulSoup 中文乱码解决方法
这篇文章主要介绍了Python BeautifulSoup中文乱码问题的2种解决方法,需要的朋友可以参考下 解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输 ...
- python matplotlib 中文显示乱码设置
python matplotlib 中文显示乱码设置 原因:是matplotlib库中没有中文字体.1 解决方案:1.进入C:\Anaconda64\Lib\site-packages\matplot ...
- python爬虫中文乱码解决方法
python爬虫中文乱码 前几天用python来爬取全国行政区划编码的时候,遇到了中文乱码的问题,折腾了一会儿,才解决.现特记录一下,方便以后查看. 我是用python的requests和bs4库来实 ...
- 【292】Python 关于中文字符串的操作
参考:什么是字符编码? 参考:Unicode 和 UTF-8 有何区别? 参考:python中文decode和encode转码 一.相关说明 Python 中关于字符串的操作只限于英文字母,当进行中文 ...
随机推荐
- .gitignore文件常用写法
一般的项目代码中会涉及到密码.key/secret等隐私内容,不适合上传github公开.这时可以使用.gitignore文件来屏蔽这些文件的提交. 你可能用到的写法如下 写法 含义 /build/ ...
- git 下载指定tag版本的源码
git clone --branch x.x.x https://xxx.xxx.com/xxx/xxx.git
- 防止活动上线时 微信openid 被伪造的解决办法
背景 前不久上线了一个 campaign 项目,一个 h5,后端为php,用户可以在微信中通过网页授权的方式登录,然后用微信 openid 作为唯一标识符进行签到和抽奖的操作. 结果后期出现了很多脏数 ...
- win10关机之后自动重启(系统更新之后出现这个问题)
最近更新了一把win10之后出现无法关机,关机之后直接又开机,无限循环状态.最近几天没空处理一直是强关笔记本下班的. 今天打了一把命令: shutdown /s /t 0 发现关机正常,本来打算整个脚 ...
- odoo开发笔记 -- context上下文
字段级别 视图级别 窗口动作级别
- jieba分词(2)
结巴分词系统中实现了两种关键词抽取法,一种是TF-IDF关键词抽取算法另一种是TextRank关键词抽取算法,它们都是无监督的算法. 以下是两种算法的使用: #-*- coding:utf-8 -*- ...
- 微信web开发者工具、破解文件、开发文档和开发Demo下载
关注,QQ群,微信应用号社区 511389428 下载: Win: https://pan.baidu.com/s/1bHJGEa Mac: https://pan.baidu.com/s/1slhD ...
- SSH框架整合详细分析【执行流程】
struts1和spring有两种整合的方法 一种是action和spring bean映射:一种是将action交给spring初始化 第一种方式:访问.do的URL->tomcat接收到r ...
- Chrome 的 Material Design Refresh UI初探
今天Chrome自动升级到69.0.3497.92, 发现UI已经变成了"Material Design Refresh". Chrome 浏览器的页面标签已经不再像以往那样倾斜和 ...
- 15 图-图的遍历-基于邻接矩阵实现的BFS与DFS算法
算法分析和具体步骤解说直接写在代码注释上了 TvT 没时间了等下还要去洗衣服 就先不赘述了 有不明白的欢迎留言交流!(估计是没人看的了) 直接上代码: #include<stdio.h> ...