Andrew Ng机器学习课程笔记(四)之神经网络
Andrew Ng机器学习课程笔记(四)之神经网络
版权声明:本文为博主原创文章,转载请指明转载地址
http://www.cnblogs.com/fydeblog/p/7365730.html
前言
学习了Andrew Ng课程,开始写了一些笔记,现在写完第5章了,先把这5章的内容放在博客中,后面的内容会陆续更新!
这篇博客主要记录Andrew Ng课程第四章和第五章的神经网络,主要介绍前向传播算法,反向传播算法,神经网络的多类分类,梯度校验,参数随机初始化,参数的更新等等
1.神经网络概述
之前说的线性回归还是逻辑回归都有这样一个缺点:当特征太多时,计算的负荷会非常大。
举个例子说,通过图片来识别图片上描述的是不是汽车,假设图片像素是50X50,并且我们将所有的像素视为特征,则会有2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约25002/2 个(接近3百万个)特征。普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
神经网络是根据人的神经元设计而成的,它的效果图如下:
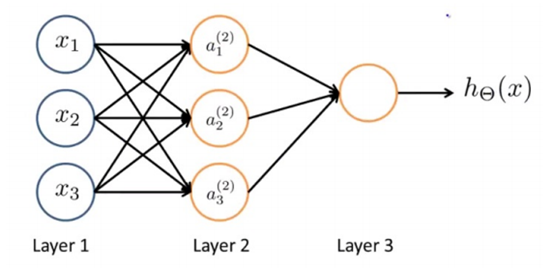
第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)
通常我们为每一层都增加一个偏差单位(bias unit):
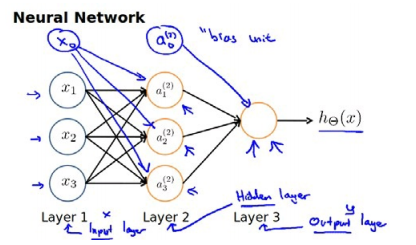
2. 前向传播算法
前向传播算法是指从原始特征从左往右一层层映射到最终的输出层,拿上面已经增加偏差单位的神经网络为例;
它的激活单元和输出分别表达为:
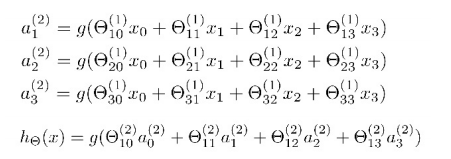
特征前的系数为特征的权重,括号内的数代表权重所在的层数,下标第一个数代表特征的所连接的神经元,第二个数代表特征的序号。
看看hθ(x)的表达式,其实就是以a0,a1,a2,a3按照Logistic Regression的方式输出hθ(x),神经网络就像是Logistic Regression,只不过我们把Logistic Regression中的输入向量[x1~x3]变成了中间层的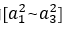 , 可以看做更为高级的特征值, 也就是x0,x1,x2,x3的进化体, 并且它们是由x与决定的,因为是梯度下降的,所以a是变化的,并且变得越来越厉害, 所以这些更高级的特征值远比仅仅将x次方厉害,也能更好的预测新数据。
, 可以看做更为高级的特征值, 也就是x0,x1,x2,x3的进化体, 并且它们是由x与决定的,因为是梯度下降的,所以a是变化的,并且变得越来越厉害, 所以这些更高级的特征值远比仅仅将x次方厉害,也能更好的预测新数据。
3. 神经网络直观解释--AND 函数
我们可以用这样的一个神经网络表示AND 函数:
X1 , X2 属于 {0,1}
Y= X1 AND X2

其中θ0 =-30, θ1 =20, θ2 =20
我们的输出函数h(x)即为:hθ(x) = g(-30+20*X1+20*X2)
我们知道g(x)的图像是:
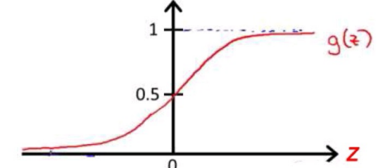

这就是我们的AND函数。这可以说是一个简单的感知机模型。
4.多类分类
如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有4个值。例如,第一个值为1或0用于预测是否是行人,第二个值用于判断是否为汽车。
输入向量x有三个维度,两个中间层,输出层4个神经元分别用来表示4类,也就是每一个数据在输出层都会出现[a b c d]T,且a,b,c,d中仅有一个为1,表示当前类。下面是该神经网
络的可能结构示例:
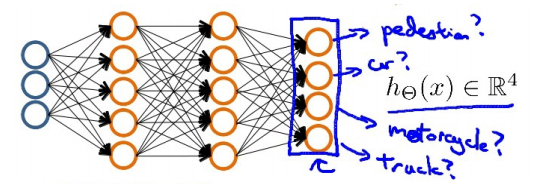
分类结果
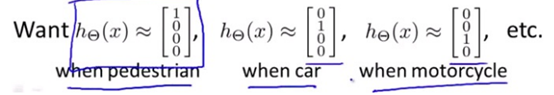
神经网络算法的输出结果为四种可能情形之一:

5. 神经网络代价函数
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量y,但是在神经网络中,我们可以有很多输出变量,我们的hθ(x)是一个维度为K的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为:
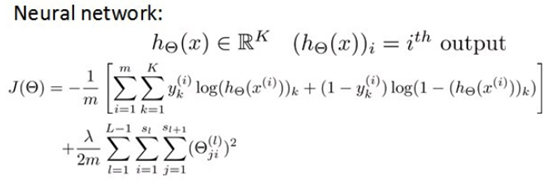
其实就是将维度为K的向量分次求代价函数并求和,正则化有一点不一样,最外层排除了每一层θ0后,每一层的θ矩阵的和,最里层的循环j循环所有的行( 由 sl +1 层的激活单元数决定),循环i则循环所有的列,由该层(sl 层)的激活单元数所决定。
即:hθ(x)与真实值之间的距离为每个样本-每个类输出的加和,对参数进行regularization的bias项处理所有参数的平方和
6. 反向传播算法
这里说一句,由于推导过程是有点复杂,吴恩达老师直接给出了相应的结论,要是有疑问,可以看清华大学深研院袁博老师的神经网络章中的层次分明,责任到人一节,这里附上链接http://www.xuetangx.com/courses/course-v1:TsinghuaX+80240372X+sp/about
当然,也可以看看相关的博客,这里推荐我朋友的一篇博客http://www.cnblogs.com/xuhongbin/p/6666826.html,也有推导过程,不过袁博老师还是讲得不错的,推荐看视频。
下面以下图为例,来说说这个反向传播算法

这个算法是由输出层的误差一层层反向传播到输入层的,由于输入层是特征实际值,所以不会算输入层的误差(即不存在误差),到第二层即可停止。反向传播算法是基于梯度下降的策略,通过算出每层的误差(除第一层),根据误差的情况,来迭代更新每层的权重。
一般分这几步
先算出输出层的误差
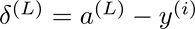 (这里的L等于4)
(这里的L等于4)
根据这个误差在计算L-1到2层的误差

计算公式如下:
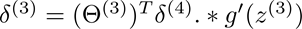
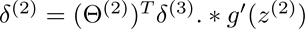
这里的g’(z(3))等于g(z(3))(1-g(z3)) ,因为g(x)=1/(1+exp(-x)),它的导数就是这样的性质。
算出每个层的误差后,然后进行权重的更新

7. 梯度校验
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能并不是最优解。
为了避免这样的问题,我们采取一种叫做梯度的数值检验方法。
这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的。
对梯度的估计采用的方法是在代价函数上沿着切线的方向选择离两个非常近的点然后计算两个点的平均值用以估计梯度。 即对于某个特定的θ,我们计算出在θ-ε处和θ+ε的代价值(ε是一个非常小的值, 通常选取 0.001),然后求两个代价的平均,用以估计在θ处的代价值,如图所示
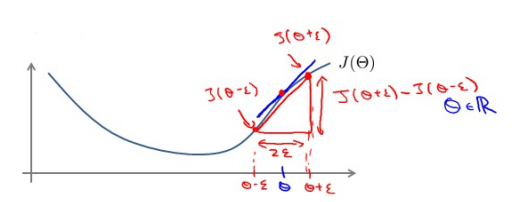
Octave(matlab也行) 中代码如下:
gradApprox = (J(theta + eps) – J(theta - eps)) / (2*eps)
当θ是一个向量时, 我们则需要对偏导数进行检验,如下
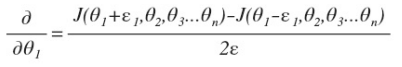
最后我们还需要对通过反向传播方法计算出的偏导数进行检验,将估计的值与算出的值进行比较即可。
8. 随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
我们通常初始参数为正负ε之间的随机值,假设我们要随机初始一个尺寸为10×11 的参
数矩阵,代码如下:
Theta1 = rand(10, 11) * (2*eps) – eps
9. 参数更新——动量(Momentum)
这一点吴恩达老师没说,我是看袁博老师介绍的,试想一下,如果代价函数中间有一小段水平的空间,这时候偏导等于0的,参数立即停止更新,就无法更新到我们想要的参数(即一小段水平面还有更低数值的代价函数),这时候在参数更新表达式上加一个动量就能解决这个问题,表达式如下:
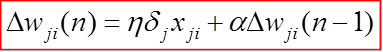
将前一回的参数更新迭代到当前时刻,这样在导数为0(即 ),参数更新还是有动力的,还能前进一小段,可以通过水平区域,达到更低数值的代价函数。
10. 综合
使用神经网络的步骤分两步:确定网络结构和训练神经网络
(1) 确定网络结构
①第一层的单元数即我们训练集的特征数量。
②最后一层的单元数是我们训练集的结果的类的数量。
③确定隐藏层的层数和每个中间层的单元数。
(2)
训练神经网络
①参数的随机初始化
②利用正向传播方法计算所有的hθ(x)
③编写计算代价函数J的代码
④利用反向传播方法计算所有偏导数
⑤利用数值检验方法检验这些偏导数
⑥使用优化算法来最小化代价函数
Andrew Ng机器学习课程笔记(四)之神经网络的更多相关文章
- Andrew Ng机器学习课程笔记--汇总
笔记总结,各章节主要内容已总结在标题之中 Andrew Ng机器学习课程笔记–week1(机器学习简介&线性回归模型) Andrew Ng机器学习课程笔记--week2(多元线性回归& ...
- Andrew Ng机器学习课程笔记(六)之 机器学习系统的设计
Andrew Ng机器学习课程笔记(六)之 机器学习系统的设计 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7392408.h ...
- Andrew Ng机器学习课程笔记(五)之应用机器学习的建议
Andrew Ng机器学习课程笔记(五)之 应用机器学习的建议 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7368472.h ...
- Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归)
title: Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归) tags: 机器学习, 学习笔记 grammar_cjkRuby: true --- 之前看过一遍,但是总是模 ...
- Andrew Ng机器学习课程笔记(三)之正则化
Andrew Ng机器学习课程笔记(三)之正则化 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7365475.html 前言 ...
- Andrew Ng机器学习课程笔记(二)之逻辑回归
Andrew Ng机器学习课程笔记(二)之逻辑回归 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7364636.html 前言 ...
- Andrew Ng机器学习课程笔记(一)之线性回归
Andrew Ng机器学习课程笔记(一)之线性回归 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7364598.html 前言 ...
- Andrew Ng机器学习课程笔记--week4(神经网络)
Neural Networks: Representation 一. 内容概要 Neural Network Model Representation 1 Model Representation 2 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 8_Neural Networks Representation 神经网络的表述
神经网络是一种受大脑工作原理启发的模式. 它在许多应用中广泛使用:当您的手机解释并理解您的语音命令时,很可能是神经网络正在帮助理解您的语音; 当您兑现支票时,自动读取数字的机器也使用神经网络. 8.1 ...
随机推荐
- (简单匹配)Card Game Cheater -- hdu --1528
http://acm.hdu.edu.cn/showproblem.php?pid=1528 Card Game Cheater Time Limit: 2000/1000 MS (Java/Othe ...
- USTC《现代软件工程》春季学期——第一次个人作业:词频统计
截止日期 2018年3月29日23:59 要求 1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数. ...
- Hadoop-1.2.1伪分布下 hive-0.10.0内嵌模式安装
Hadoop-1.2.1伪分布下 hive-0.10.0内嵌模式安装 1.下载hive-0.10.0 网址是:http://archive.apache.org/dist/hive/hive-0.10 ...
- int LL数据范围
unsigned int 0-4294967295 0~4e9 int -2147483648-2147483647 -2e9~2e9 unsigned long 0-4294967295 long ...
- MEAN 26
MEAN 纸质书,第26章内容,使用社交媒体账户作为身份验证来源 先不看. 功能:登录,注册 或者 用户,身份认证和会话管理 功能描述:用户注册,登录,查看,编辑信息,logout. 1.expres ...
- 第三天:JavaScript的DOM对象和DOM操作HTML
1. DOM操作HTML 1)注意:绝对不要在文档加载完成之后使用docment.write().这样会覆盖原来的文档 <body> <p>hello</p> &l ...
- Oracle PLSQL读取(解析)Excel文档
http://www.itpub.net/thread-1921612-1-1.html !!!https://code.google.com/p/plsql-utils/ Introduction介 ...
- cxGrid 的 Sorting和Filtering的总开关
- .Net Core Web应用发布至IIS后报“An error occurred while starting the application”错误
An error occurred while starting the application. .NET Core X64 v4.1.1.0 | Microsoft.AspNetCore ...
- 一、winForm-DataGridView操作——控件绑定事件的两种方法
在winForm窗体中绑定(注册)事件的方法有两种: 一.绑定事件 双击控件,即进入.cs的代码编辑页面,会出现 类似于“ private void 控件名称_Click(object sender, ...