java 序列化 serialVersionUID 的作用 和 两种添加方式
serialVersionUID适用于Java的序列化机制。简单来说,Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
private static final long serialVersionUID = xxxxL;
当一个类实现了Serializable接口,如果没有显示的定义serialVersionUID,Eclipse会提供相应的提醒。面对这种情况,我们只需要在Eclipse中点击类中warning图标一下,Eclipse就会 自动给定两种生成的方式。如果不想定义,在Eclipse的设置中也可以把它关掉的,设置如下:
Window ==> Preferences ==> Java ==> Compiler ==> Error/Warnings ==> Potential programming problems
将Serializable class without serialVersionUID的warning改成ignore即可。
当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
下面用代码说明一下serialVersionUID在应用中常见的几种情况。
(1)序列化实体类
import java.io.Serializable;
public class Person implements Serializable
{
private static final long serialVersionUID = 1234567890L;
public int id;
public String name; public Person(int id, String name)
{
this.id = id;
this.name = name;
} public String toString()
{
return "Person: " + id + " " + name;
}
}
(2)序列化功能:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream; public class SerialTest
{ public static void main(String[] args) throws IOException
{
Person person = new Person(1234, "wang");
System.out.println("Person Serial" + person);
FileOutputStream fos = new FileOutputStream("Person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.flush();
oos.close();
}
}
(3)反序列化功能:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeserialTest
{
public static void main(String[] args) throws IOException, ClassNotFoundException
{
Person person; FileInputStream fis = new FileInputStream("Person.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
person = (Person) ois.readObject();
ois.close();
System.out.println("Person Deserial" + person);
} }
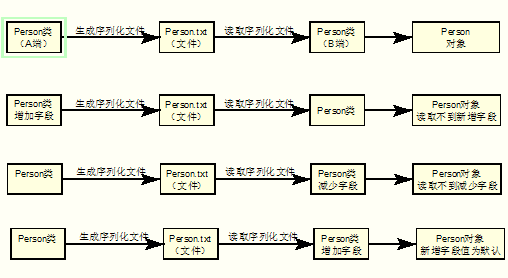
情况一:假设Person类序列化之后,从A端传输到B端,然后在B端进行反序列化。在序列化Person和反序列化Person的时候,A端和B端都需要存在一个相同的类。如果两处的serialVersionUID不一致,会产生什么错误呢?
【答案】可以利用上面的代码做个试验来验证:
先执行测试类SerialTest,生成序列化文件,代表A端序列化后的文件,然后修改serialVersion值,再执行测试类DeserialTest,代表B端使用不同serialVersion的类去反序列化,结果报错:
Exception in thread "main" java.io.InvalidClassException: test.Person; local class incompatible: stream classdesc serialVersionUID = 1234567890, local class serialVersionUID = 123456789
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:560)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1580)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1493)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1729)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1326)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:348)
at test.DeserialTest.main(DeserialTest.java:15)
情况二:假设两处serialVersionUID一致,如果A端增加一个字段,然后序列化,而B端不变,然后反序列化,会是什么情况呢?
【答案】新增 public int age; 执行SerialTest,生成序列化文件,代表A端。删除 public int age,反序列化,代表B端,最后的结果为:执行序列化,反序列化正常,但是A端增加的字段丢失(被B端忽略)。
情况三:假设两处serialVersionUID一致,如果B端减少一个字段,A端不变,会是什么情况呢?
【答案】序列化,反序列化正常,B端字段少于A端,A端多的字段值丢失(被B端忽略)。
情况四:假设两处serialVersionUID一致,如果B端增加一个字段,A端不变,会是什么情况呢?
验证过程如下:
先执行SerialTest,然后在实体类Person增加一个字段age,如下所示,再执行测试类DeserialTest.
import java.io.Serializable;
public class Person implements Serializable
{
private static final long serialVersionUID = 123456789L;
public int id;
public String name;
public int age; public Person(int id, String name)
{
this.id = id;
this.name = name;
} public String toString()
{
return "Person: " + id + " " + name;
}
}
相应的修改测试类DeserialTest,打印出age的值。
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream; public class SerialTest
{ public static void main(String[] args) throws IOException
{
Person person = new Person(1234, "wang");
System.out.println("Person Serial" + person + " age:" + person.age);
FileOutputStream fos = new FileOutputStream("Person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.flush();
oos.close();
}
}
结果为:
Person Deserial Person: 1234 wang age: 0
说明序列化,反序列化正常,B端新增加的int字段被赋予了默认值0。
最后通过下面的图片,总结一下上面的几种情况。
原文:http://swiftlet.net/archives/1268
java 序列化 serialVersionUID 的作用 和 两种添加方式的更多相关文章
- Java中serialVersionUID的解释及两种生成方式的区别(转载)
转载自:http://blog.csdn.net/xuanxiaochuan/article/details/25052057 serialVersionUID作用: 序列化时为了保持版 ...
- java多线程总结:线程的两种创建方式及优劣比较
1.通过实现Runnable接口线程创建 (1).定义一个类实现Runnable接口,重写接口中的run()方法.在run()方法中加入具体的任务代码或处理逻辑. (2).创建Runnable接口实现 ...
- Java设计模式之工厂模式的两种实现方式
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 1. 为什么要有工厂模式? "Talk i ...
- java 调用wsdl的webservice接口 两种调用方式
关于wsdl接口对于我来说是比较头疼的 基本没搞过.一脸懵 就在网上搜 看着写的都很好到我这就不好使了,非常蓝瘦.谨以此随笔纪念我这半个月踩过的坑... 背景:短短两周除了普通开发外我就接到了两个we ...
- (转)java 序列化ID的作用
序列化ID的作用: 其实,这个序列化ID起着关键的作用,它决定着是否能够成功反序列化!简单来说,java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的.在进行反序 ...
- 细说java中Map的两种迭代方式
曾经对java中迭代方式总是迷迷糊糊的,今天总算弄懂了.特意的总结了一下.基本是算是理解透彻了. 1.再说Map之前先说下Iterator: Iterator主要用于遍历(即迭代訪问)Collecti ...
- Java多线程13:读写锁和两种同步方式的对比
读写锁ReentrantReadWriteLock概述 大型网站中很重要的一块内容就是数据的读写,ReentrantLock虽然具有完全互斥排他的效果(即同一时间只有一个线程正在执行lock后面的任务 ...
- Java中的ReentrantLock和synchronized两种锁定机制的对比
问题:多个访问线程将需要写入到文件中的数据先保存到一个队列里面,然后由专门的 写出线程负责从队列中取出数据并写入到文件中. http://blog.csdn.net/top_code/article/ ...
- Java学习-014-文本文件写入实例源代码(两种写入方式)
此文源码主要为应用 Java 读取文本文件内容实例的源代码.若有不足之处,敬请大神指正,不胜感激! 第一种:文本文件写入,若文件存在则删除原文件,并重新创建文件.源代码如下所示: /** * @fun ...
随机推荐
- English Learning - Vampire bats
" Vampire bats are very adaptable." Bambi said. And when their roosts are disrupted or the ...
- 关于js中的表单事件
表单结构如下所示: <form > <input type="text" name="txt" id="txt" valu ...
- FineReport填报分页设置
1. 问题描述 进行FineReport数据填报时,如果数据量过大,由于前端浏览器的性能限制,如果将数据全部展现出来,速度会非常的慢,影响用户体验,这时候大家就会想,填报是否能像分页预览一样进行分页呢 ...
- PHP实现跨域解决方法
如果要实现跨域通过设置Access-Control-Allow-Origin来实现跨域. 例如:客户端的域名是client.runoob.com,而请求的域名是server.runoob.com. 如 ...
- XRouter-像Retrofit一样使用阿里开源路由中间件
XRouter 一种基于Arouter的使用封装方案,实现对ARouter的Retrofit式使用. ARouter是阿里巴巴开源的Android平台中对页面.服务提供路由功能的中间件,没用过的务必点 ...
- 发票OCR识别/票据OCR自动识别
对于一些大的集团公司来说,分散式财务管理模式管理效率不高,管理成本相对较高,同时也制约了集团企业发展战略的实施,因而需要建设财务共享中心.一个企业想建造财务共享中心,面临的难题是大量的数据采集和信息处 ...
- Linux项目自动部署
场景:linux中自动部署项目在工作中经常遇到,快速高效的部署项目能够大幅提高工作效率.现在将项目部署的过程记录下来,以供参考,其中用到的知识点现在还有很多不很清楚,后面要好好琢磨琢磨! 1 项目部署 ...
- (转) Spring Boot JDBC 连接数据库
文本将对在Spring Boot构建的Web应用中,基于MYSQL数据库的几种数据库连接方式进行介绍. 包括JDBC.JPA.MyBatis.多数据源和事务. 1 JDBC 连接数据库 1.1 属性配 ...
- POI读取excel工具类 返回实体bean集合(xls,xlsx通用)
本文举个简单的实例 读取上图的 excel文件到 List<User>集合 首先 导入POi 相关 jar包 在pom.xml 加入 <!-- poi --> <depe ...
- 初学Python(四)——set
初学Python(四)——set 初学Python,主要整理一些学习到的知识点,这次是set. # -*- coding:utf-8 -*- #先来看数组和set的差别 d=[1,1,2,3,4,5] ...