开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启。通过封神了解到,在上午的专场中,阿里云高级技术专家无谓、阿里云技术专家封神、阿里巴巴中间件技术部高级技术专家天梧、阿里巴巴中间件技术部资深技术专家纪君祥将给大家带来Hadoop、Spark、HBase、JStorm Turbo等内容。

无谓:Hadoop过去现在未来,从阿里云梯到E-MapReduce

阿里云高级技术专家 无谓
从开辟大数据先河至现在,风雨十年,Hadoop已成为企业的通用大数据框架。而作为上午的第一个演讲,无谓首先给我们总结了Hadoop这十年,也是从离线到在线的十年,其中意义重大的事情有:YARN成为大数据操作系统;Hadoop成为企业级解决方案,涵盖数据可视化工具、存储、计算、数据管理等;机器学习和人工智能的支持; Mahout->oryx,批处理到实时处理的学习工具。

而在这段时间,阿里从2008年就已经参与到Hadoop中,其主要阶段可概括为: 2008-2009期间,建立了多部门独立的Hadoop集群;2009-2015,主要做云梯集群和服务,包括:集群统一运维,专业的开发团队;数据统一管理,集团层面的全局视图;资源错峰分配,整体成本最优;2015-至今,阿里云E-MapReduce,阿里云对外的Hadoop基础服务。

随后,无谓还重点分享了阿里内部的Hadoop服务云梯:全局资源调度:支持业务优先级(基于Fair Scheduler);安全性,HDFS上的扩展ACL,Hive安全认证和授权;稳定性,消除异常作业对全局的影响Master HA;扩展性:Master节点的单点性能压力,跨机房 的部署架构;云梯医生:集群诊断系统,最后,通过无谓,我们还体会了阿里云分享的技术红利E-MapReduce。
封神: Spark实践与探索

阿里云技术专家 封神
封神专注于大数据领域,拥有7年的分布式引擎开发经验,先后参与了上万台Hadoop、ODPS集群的开发。在本次演讲中,他主要介绍了数据处理技术、About Spark、阿里的Spark历程、Spark与云,及Spark未来多个方面。

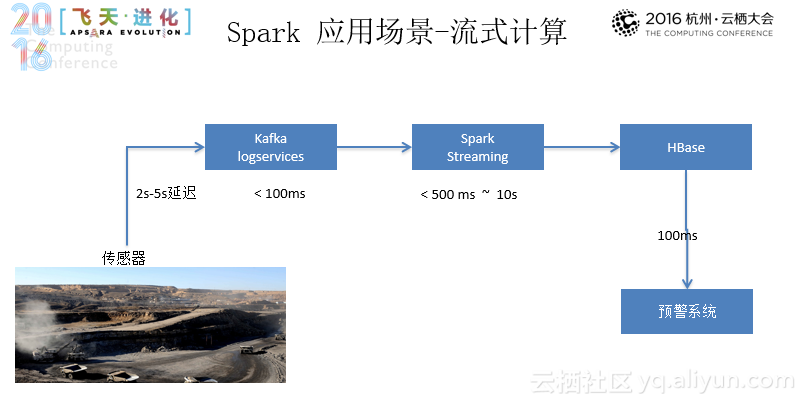
在时下流行大数据技术对比中,封神首先从数据处理时间与数据量两个方面维度进行了切入,在这个过程中,我们会发现,没有哪个软件能解决所有的问题,能解决问题也是在一个范围内,即使是Spark、Flink等。目前存在有意思的事情是:Greenplum类似的MPP引擎想处理大数据的需求,Hadoop等被定位为大数据的引擎也想解决小数据的问题(列式存储、或者也加入一些索引)。图中右上角的想往左边靠,减少延迟,图中左下角的想往上面靠,增大能处理的数据量。此外在DB/MPP与Hadoop的对比上,Hadoop生态圈为何如何火爆也能有所体现:首先,在硬件需求上,DB/MPP可能需要小型机和高端存储,同时也需要RAID,而Hadoop只需要普通的PC机;容错性上,DB/MPP重跑即可,而Hadoop则需要容错;在调度模型上,DB/MPP使用了基于线程的调度,而Hadoop则需要做CPU/Memory的调度;最后,在衡量指标上DB/MPP一般以QPS为标准,而Hadoop相关系统一般更看重吞吐。


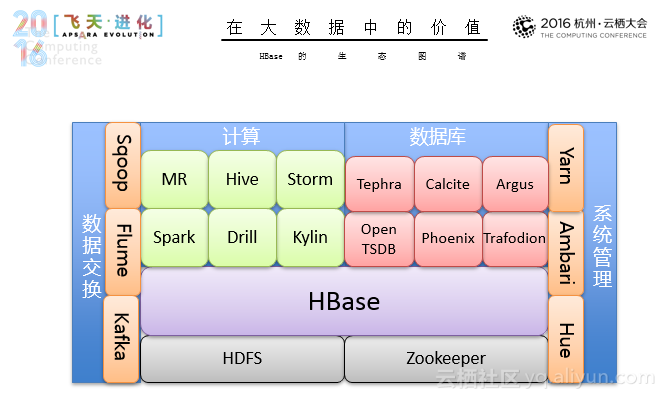
Hadoop Database,是一个基于Google BigTable论文设计的高可靠性、高性能、可伸缩的分布式存储系统,它的具体特性有:松散表,实时更新、增量导入、多维删除,随机查询、范围查询,高伸缩、高可用、高可靠、高性能、高适应,在线分布式NOSQL数据库。
与Hadoop的天然集成让HBase天生具备了很多优势,在阿里之外,同样得到了 Intel、Facebook、Cloudera、Hortonworks、小米等公司的支持。而在此之外,HBase的其他基因同样深受大数据玩家的喜爱,包括:自动分区,分区自动分裂,分区在线Merge,可应对数据爆发式增长和访问爆发式增长;LSM,写吞吐高,不受SSD随机写入放大干扰,不受空间放大干扰;存储计算分离,负载均衡更高效,资源扩容更节省,存储优化更便捷(非对称副本冗余:异构介质、Erasure Code等)。
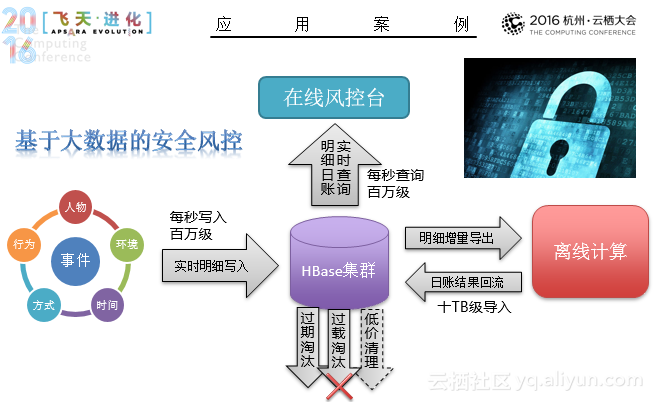
可以说,HBase为大数据而生。然而就如任何开源软件,HBase的使用同样需要大量的研发投入。在这里,阿里也基于阿里巴巴/蚂蚁的环境和业务需求,对社区HBase进行深度定制与改进,从内核引擎、解决方案、稳定护航、发展支撑等全方位提供一站式大数据基础存储服务,就拿灾备体系来说,包括集群数据复制的诉求、多集群数据复制、流量切换、跨集群一致性保证、深度优化的宕机恢复能力等方面。集群数据复制的诉求,数据一致,延迟低,吞吐大,多源多目标,链路粒度细,异构系统,可视可追踪等;多集群数据复制,异步模式,同步模式,支持多地多单元、表级复制、循环流动,支持延迟/拓扑/复制详情可视,支持数据的链路追踪,支持实时复制到异构系统,并发、吞吐、实时的有效权衡异步模式;流量切换,虚拟地址映射,支持一键切换、自动切换;跨集群一致性保证,基于读写保护的强一致;深度优化的宕机恢复能力。
天梧表示,在此之外,在HBase上阿里还做了调整、报警、健康等各个方面的工作。而在未来,更大硬件支持、容器化部署也将是一大研究的方向。
纪君祥:阿里巴巴实时计算平台 JStorm Turbo

阿里巴巴中间件技术部资深技术专家 纪君祥
通过纪君祥了解到,从2013年4月3日起,JStorm已经发布了25个版本,部署方式包括Standalone、JStorm-on-yarn、JStorm-on-docker等方式,部署超过4000台主机,支撑了1500以上的应用,拥有超过2000+的topologies。

在JStorm与Storm区别上,纪君祥提到JStorm更是一个流处理生态系统,而不是简单的一个流计算框架。同时,对于企业来说JStorm还是一个成熟的Java版Storm,它不仅运营更快、更稳定,也具备了更多的功能。
开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践的更多相关文章
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 【云+社区极客说】新一代大数据技术:构建PB级云端数仓实践
本文来自腾讯云技术沙龙,本次沙龙主题为构建PB级云端数仓实践 在现代社会中,随着4G和光纤网络的普及.智能终端更清晰的摄像头和更灵敏的传感器.物联网设备入网等等而产生的数据,导致了PB级储存的需求加大 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 大数据技术之HBase
第1章 HBase简介 1.1 什么是HBase HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储. 官方 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- 从大数据技术变迁猜一猜AI人工智能的发展
目前大数据已经成为了各家互联网公司的核心资产和竞争力了,其实不仅是互联网公司,包括传统企业也拥有大量的数据,也想把这些数据发挥出作用.在这种环境下,大数据技术的重要性和火爆程度相信没有人去怀疑. 而A ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
随机推荐
- arcgis andriod GeometryEngine使用
intersectionMenuItem.setChecked(true); showGeometry(GeometryEngine.intersection(inputPolygon1, input ...
- interlliJ idea 不识别文件类型的解决方式
idea 支持非常多种文件类型.然而总有想不到. 近期开发jenkins 插件,jenkins 插件的页面开发大多用jelly 如何让idea识别jelly呢? ctrl+alt+s 快捷键打开配置页 ...
- linux内核编译指定工具连
make modules CROSS_COMPILE=arm-linux-
- SpiderMonkey的使用
基于 C 语言的 JavaScript 引擎探索 http://www.ibm.com/developerworks/cn/linux/l-cn-spidermonkey/ https://devel ...
- go语言基础之同级目录
1.同级目录 分文件编程(多个源文件),必须放在src目录 同一个目录,包名必须一样 设置GOPATH环境变量 go env 查看go相关环境路径 GO PATH: 在windows系统中,添加go环 ...
- 在C#中使用属性控制 XML 序列化来解析XML
今天需要解析一个XML,这个XML和一般情况用.NET的序列化出来的格式不太一样. 我就又补习了一下. 分享一下学习成果吧. 示例代码下载: http://download.csdn.net/deta ...
- SQL基础(一):SQL语法和命令
一.语法: 1.SQL 对大小写不敏感:SELECT 与 select 是相同的. 2.某些数据库系统要求在每条 SQL 语句的末端使用分号.分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样 ...
- OpenNMS编译,打包并在Windows下启动
1.Download Opennms latest source code 2.Download latest Java JDK and install it. Set JAVA_HOME path ...
- mybatis的statement的解析与加载(springboot)
问题 mybatis的xml中的sql语句是启动时生成JDK代理类的时候就生成一次么 调用顺序链 解析xml配置 Reader reader = Resources.getResourceAsRead ...
- linux下如何查看所有的用户和组信息?
/etc/group 文件是用户组的配置文件. /etc/passwd 文件是用户的配置文件. 使用cat.more.less.head.tail以及vim等命令都可以查看.修改这两个配置文件. 说 ...