Hadoop生态圈-HBase的HFile创建方式
Hadoop生态圈-HBase的HFile创建方式
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
废话不多说,直接上代码,想说的话都在代码的注释里面。
一.环境准备
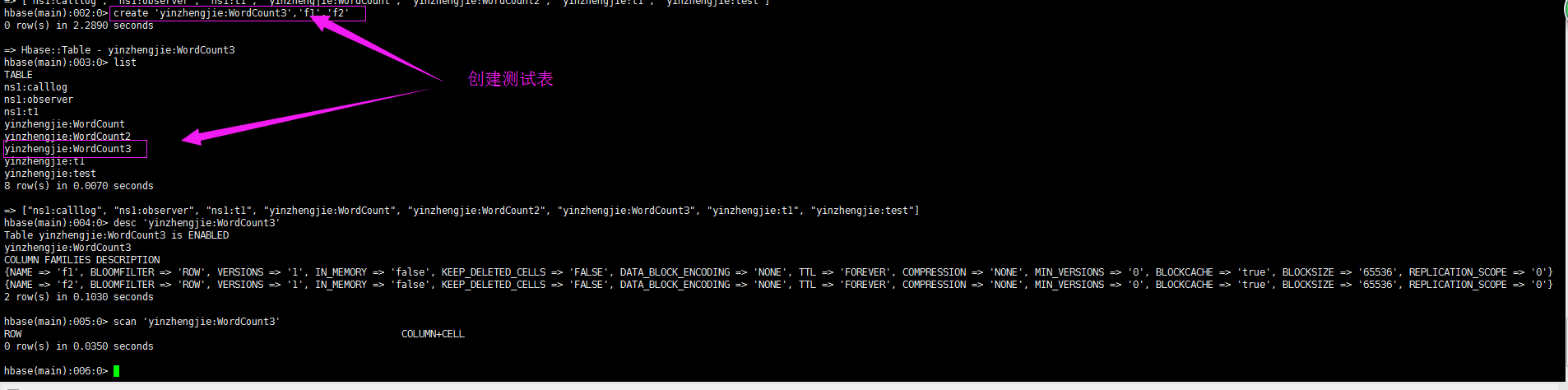
list
create 'yinzhengjie:WordCount3','f1','f2'
list
desc 'yinzhengjie:WordCount3'
scan 'yinzhengjie:WordCount3'
二.编写HFile创建方式的代码
1>.编写Map端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.hfile; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class HFileOutputMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到一行数据
String line = value.toString();
String[] arr = line.split(" ");
//
for (String word : arr){
context.write(new Text(word),new IntWritable(1));
}
}
}
2>.编写Reducer端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.hfile; import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class HFileOutputReducer extends Reducer<Text,IntWritable,ImmutableBytesWritable,Cell> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
if(key.toString().length() > 0){
ImmutableBytesWritable outKey = new ImmutableBytesWritable(Bytes.toBytes(key.toString()));
//创建cell
Cell cell = CellUtil.createCell(Bytes.toBytes(key.toString()),
Bytes.toBytes("f1"), Bytes.toBytes("count"),System.currentTimeMillis(),
KeyValue.Type.Minimum,Bytes.toBytes(sum+""),null);
context.write(outKey,cell);
}
}
}
3>.编写主程序代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.hfile; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class App { public static void main(String[] args) throws Exception { System.setProperty("HADOOP_USER_NAME", "yinzhengjie");
Configuration conf = HBaseConfiguration.create();
conf.set("fs.defaultFS","file:///");
Connection conn = ConnectionFactory.createConnection(conf);
Job job = Job.getInstance(conf);
job.setJobName("HFile WordCount");
job.setJarByClass(App.class);
job.setMapperClass(HFileOutputMapper.class);
job.setReducerClass(HFileOutputReducer.class);
//设置输出格式
job.setOutputFormatClass(HFileOutputFormat2.class);
//设置路径
FileInputFormat.addInputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\word.txt"));
FileOutputFormat.setOutputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\hfile"));
//设置输出k-v
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Cell.class);
//设置map端输出k-v
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
/**
* 配置和"yinzhengjie:WordCount3"进行关联,也就是说"yinzhengjie:WordCount3"这个表必须在HBase数据库中存在,
* 实际操作是以"yinzhengjie:WordCount3"为模板,便于生成HFile文件!
*/
HFileOutputFormat2.configureIncrementalLoad(job, new HTableDescriptor(TableName.valueOf("yinzhengjie:WordCount3")),
conn.getRegionLocator(TableName.valueOf("yinzhengjie:WordCount3")) );
job.waitForCompletion(true);
}
}
4>.查看测试结果
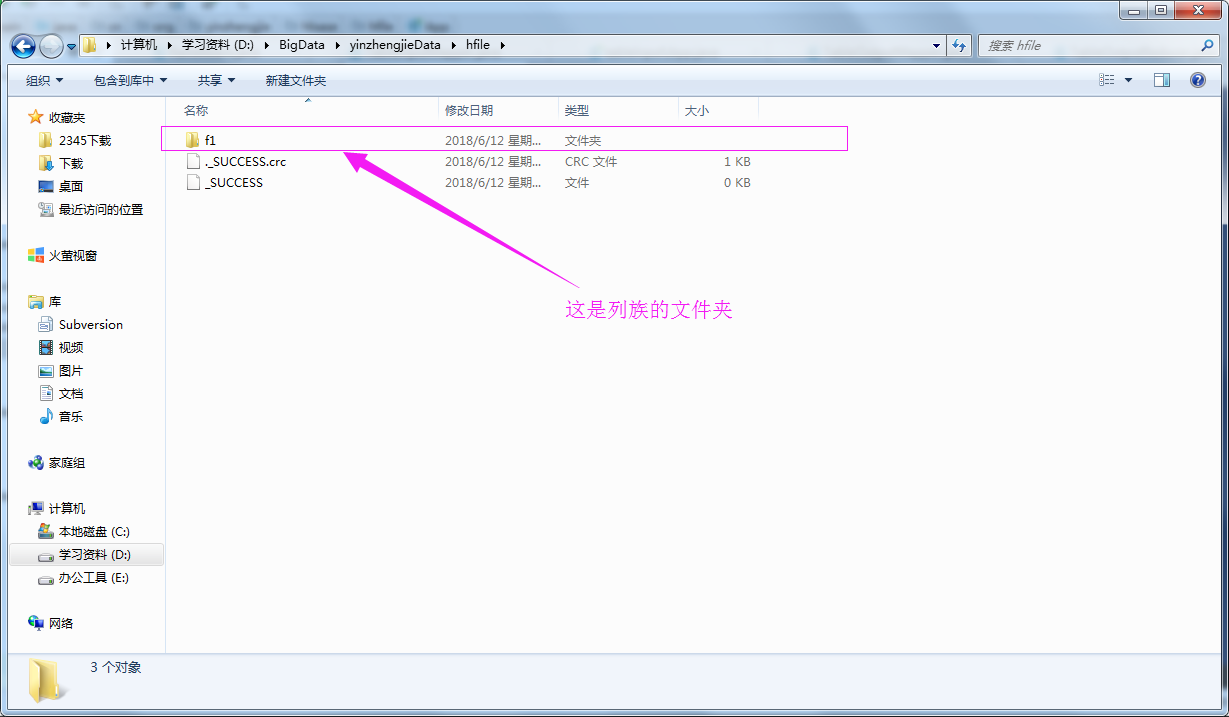
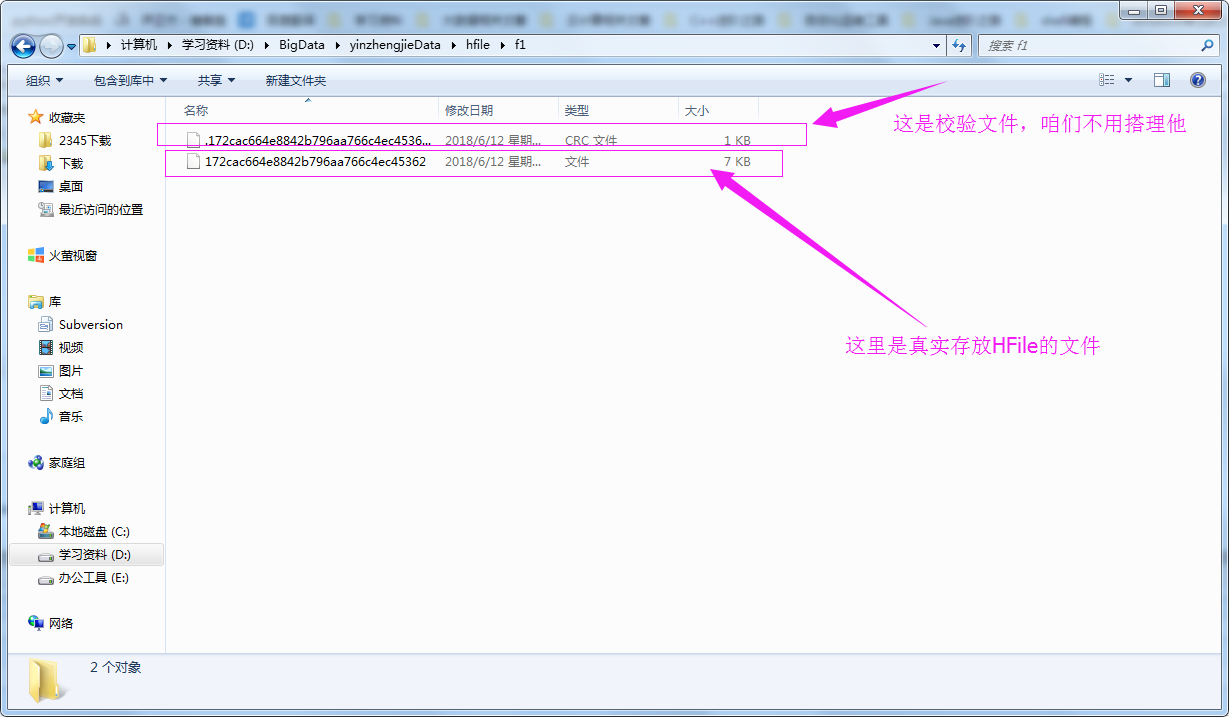
Hadoop生态圈-HBase的HFile创建方式的更多相关文章
- Hadoop生态圈-基于yum源的方式部署Cloudera Manager5.15.1
Hadoop生态圈-基于yum源的方式部署Cloudera Manager5.15.1 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我之前分享过关于离线方式部署Cloudera ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- Hadoop生态圈-HBase性能优化
Hadoop生态圈-HBase性能优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hbase的协处理器(coprocessor)应用
Hadoop生态圈-Hbase的协处理器(coprocessor)应用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hbase的rowKey设计原则
Hadoop生态圈-Hbase的rowKey设计原则 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hbase的Region详解
Hadoop生态圈-Hbase的Region详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hbase过滤器(Filter)
Hadoop生态圈-Hbase过滤器(Filter) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hbase的API常见操作
Hadoop生态圈-Hbase的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-hbase常用命令
Hadoop生态圈-hbase常用命令 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- H-ui框架制作选项卡
本案例运用H-ui框架,写了一个选项卡案例 1. html代码(固定这样写,用一个div包裹控制条tabBar和内容条tabCon) <div id="tab-index-carteg ...
- 文件上传到tomcat服务器 commons-fileupload的详细介绍与使用
三个类:DiskFileUpload.FileItem和FileUploadException.这三个类全部位于org.apache.commons.fileupload包中. 首先需要说明一下for ...
- 【Coursera】应用机器学习的建议
偏差方差权衡 使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过归一化手 ...
- SM2
一.介绍 #百度 二.生成密钥对及证书 1.使用gmssl工具 详见gmssl 2.go 版本 详见https://github.com/tjfoc/gmsm 3.java版本 #尚未实现 1.初步使 ...
- Windows服务器安全配置指南
1).系统安全基本设置 2).关闭不需要的服务 Computer Browser:维护网络计算机更新,禁用 Distributed File System: 局域网管理共享文件,不需要禁用 Distr ...
- 记:ASP.NET Core开发时部署到IIS上出现HTTP Error 502.5 - Process Failure的解决方案
HTTP Error 502.5 - Process Failure Common causes of this issue: The application process failed to st ...
- MongoDB中的数据导出为excel CSV 文件
1.打开命令行,进入我们所安装的mongodb路径下的bin文件夹 2.我们采用bin文件夹下的mongoexport方法进行导出, mongoexport -d myDB -c user -f _i ...
- sprint1
6.0----------------------------------------------------- sprint演示 1.坚持所有的sprint都结束于演示. 团队的成果得到认可,会感觉 ...
- Java中的多线程科普
如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个话其 ...
- ecplise maven springmvc工程搭建
转载自:https://www.cnblogs.com/crazybirds/p/4643497.html 内网上网代理配置: 第一步:新建maven项目,选择Maven Project,如图1. ...