Zookeeper服务器集群的搭建与操作
ZooKeeper
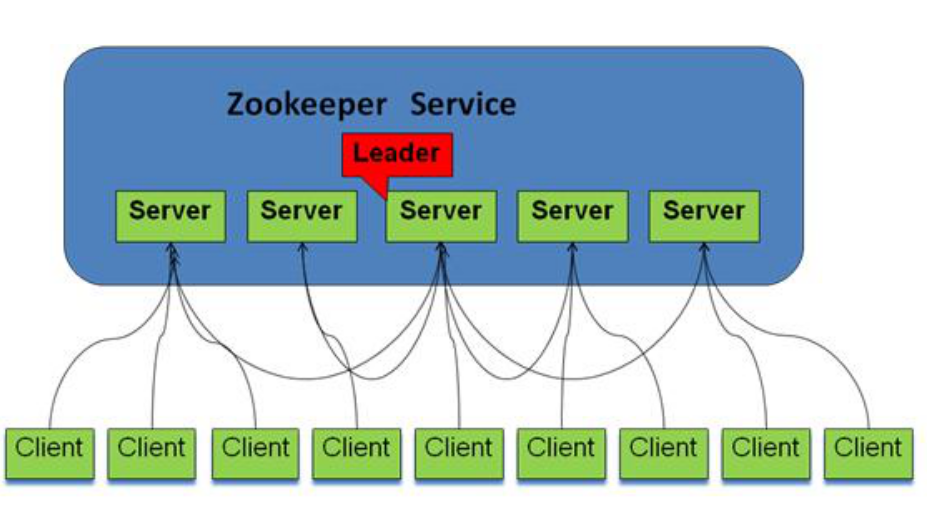
作用:Zookeeper 可以用来保证数据在zk集群之间的数据的事务性一致(原子操作)。
介绍:Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务。
它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
特性:简单的、富有表现力的、具有高可用性、采用松耦合交互方式、是一个资源库。
如何搭建ZooKeeper服务器集群
2.1 ZooKeeper服务器集群规模不小于3个节点,要求各服务器之间系统时间要保持一致。
2.2 在hadoop0的/usr/local目录下,解压缩zookeeper-3.4.5.tar.gz(tar -zxvf zookeeper-3.4.5.tar.gz),
设置环境变量vi /etc/profile
export ZOOKEEPER_HOME=/usr/local/zk
export PATH=.:$....:$ZOOKEEPER_HOME/bin:$.....
环境变量设置好了,执行source /etc/profile
2.3 在conf目录下
重命名: mv zoo_sample.cfg zoo.cfg
2.4 编辑该文件,执行vi zoo.cfg
修改dataDir=/usr/local/zk/data
新增server.0=hadoop0:2888:3888
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
2.5 创建文件夹mkdir /usr/local/zk/data
2.6 在data目录下,创建文件myid(vi myid),值为0
2.7 把zk目录复制到hadoop1和hadoop2中
scp -r /usr/local/zk/ hadoop1:/usr/local/
scp -r /usr/local/zk/ hadoop2:/usr/local/
将hadoop0中的环境变量复制到hadoop1和hadoop2中
scp /etc/profile hadoop1:/etc/
scp /etc/profile hadoop2:/etc/
环境变量复制好了以后,在hadoop1和hadoop2上都要执行source /etc/profile
2.8 把hadoop1中相应的myid的值改为1
vi /usr/local/zk/data/myid 将里面的值改为1
把hadoop2中相应的myid的值改为2
vi /usr/local/zk/data/myid 将里面的值改为2
2.9 启动,在三个节点上分别执行命令zkServer.sh start
cd /usr/local/zk/bin
ls
zkServer.sh start
启动完了之后,在bin目录下多了一个zookeeper.out
2.10 检验,在三个节点上分别执行命令zkServer.sh status(可以看到MODE,谁是leader,谁是follower)
ZooKeeper的操作(只有shell操作,也可以用java操作)
在hadoop0下,执行zkCli.sh ,就进入到了ZooKeeper,可以在里面使用命令进行相关操作:
ls /
create /chaoren hadoop (/chaoren是path,hadoop是里面的data)
get /chaoren (可以查看到里面的data)
也可以在hadoop1或hadoop2里面:
zkCli.sh
get /chaoren
也可以修改里面的data:
set /chaoren change_data (将chaoren里面的data修改为change_data)
get /chaoren
ZooKeeper的数据模型
层次化的目录结构,命名符合常规文件系统规范
每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
客户端应用可以在节点上设置监视器
节点不支持部分读写,而是一次性完整读写
Zookeeper的节点
Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
Znode的类型在创建时确定并且之后不能再修改
短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL
Zookeeper的角色
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方
Zookeeper服务器集群的搭建与操作的更多相关文章
- 虚拟机搭建Zookeeper服务器集群完整笔记
虚拟机搭建Zookeeper服务器集群完整笔记 本笔记主要记录自己搭建Zookeeper服务器的全过程,默认已经安装部署好Centos7. 一.虚拟机下Centos无法联网解决方案 1.首先调整虚拟机 ...
- ZooKeeper伪集群环境搭建
1.从官网下载程序包. 2.解压. [dev@localhost software]$ tar xzvf zookeeper-3.4.6.tar.gz 3.进入zookeeper文件夹后创建data文 ...
- zookeeper伪集群的搭建
由于公司服务器数量的限制,我们往往没有那么多的服务器用来搭建zookeeper的集群,所以产生了伪集群的搭建,也就是将多个zookeeper搭建在同一台机器上. 准备工作: 1,一台服务器,我们这里用 ...
- 【Zookeeper】集群环境搭建
一.概述 1.1 Zookeeper的角色 1.2 Zookeeper的读写机制 1.3 Zookeeper的保证 1.4 Zookeeper节点数据操作流程 二.Zookeeper 集群环境搭建 2 ...
- zookeeper以及集群的搭建
今天我来写一写zookeeper集群的搭建流程 1.zookeeper的搭建不难,难的是对他的理解以及良好的使用.单机版的zookeeper只需要解压后直接命令 启动即可 解压zookeeper,ta ...
- zookeeper 单机. 集群环境搭建
zookeeper分布式系统中面临的很多问题, 如分布式锁,统一的命名服务,配置中心,集群的管理Leader的选举等 环境准备 分布式系统中各个节点之间通信,Zookeeper保证了这个过程中 数据的 ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- ZooKeeper伪集群的搭建(Windows)
首先下载 zookeeper 地址:https://www.apache.org/dyn/closer.cgi/zookeeper/ 1.下载完成解压后修改文件夹名字为zookeeper1,然后删除c ...
- 搭建hdfs服务器集群的搭建+trash
完全分布式搭建需要三台机器:node1.node2和node3 搭建时间之前首先要保持时间一致:date ntpdateyum install ntpdatentpdate -u ntp.sjtu.e ...
随机推荐
- UIApplication概述
1.通过类方法sharedApplication可以获得唯一实例 2.可以打开mail或者email,通过openUrl方法. 3.指定UIApplicationDelegate可以跟踪各种应用状态. ...
- Shell记录-Shell命令(磁盘)
inux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况.可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息. 1.命令格式 df [选项] [文件] Shell ...
- Shell记录-Shell脚本基础(一)
Shell 注释: 你可以把注释,在你的脚本如下: #!/bin/bash # Author : Zara Ali # Copyright (c) Tutorialsyiibai.com # Scri ...
- spring-data-redis,jedis和redis主从集成和遇到的问题
Redis主从加哨兵的部署详见http://www.cnblogs.com/dupang/p/6414365.html spring-data-redis和jedis集成代码总体结构 代码地址http ...
- [2009国家集训队]小Z的袜子(hose) 浅谈莫队
浅谈莫队 推荐学习博客 http://foreseeable97.logdown.com/posts/158522-233333 借用题目: bzoj 2038 2009 国家集训队 小Z的袜子htt ...
- 【转载】 深度学习与自然语言处理(1)_斯坦福cs224d Lecture 1
版权声明:本文为博主原创文章,未经博主允许不得转载. 原文地址http://blog.csdn.net/longxinchen_ml/article/details/51567960 目录(?)[- ...
- sublime text3 最常用的快捷键及插件
A:最常用的快捷键 Tab:自动补齐代码 <!--div+Tab 其它标签一样--><div></div> emmet常用的使用方法 <!--ul>li ...
- python scrapy 基本操作演示代码
# -*- coding: utf-8 -*- import scrapy # from quotetutorial.items import QuoteItem from quotetutorial ...
- 解决windows文件夹不能自动刷新的问题
我用的是win7系统,最近忽然发现我的文档文件夹里的文件不能自动刷新了,就是当剪切或删除某个文件后,文件夹里的文件没有变化,看起来文件还在原文件夹中,只有通过手动刷新后才能看到效果,该如何解决? 网上 ...
- weblogica 目录结构 简单介绍 创建domain domain所在目录
1. samples 创建过程略过 domain的目录 [weblogic@node2 base_domain]$ pwd /home/weblogic/Oracle/Middleware/Oracl ...