HashMap 在 Java1.7 与 1.8 中的区别
hashMap 数据结构
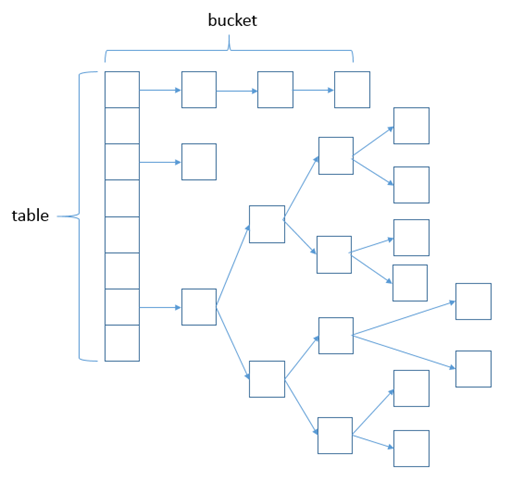
如上图所示,JDK7之前hashmap又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
JDK8中,当同一个hash值(Table上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。这就是JDK7与JDK8中HashMap实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同(hash collision),那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表。
在hashcode特别差的情况下,比方说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表
也就是说时间复杂度在最差情况下会退化到O(n)
JDK1.8中
使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构
如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。
如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。
那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销
也就是说put/get的操作的时间复杂度最差只有O(log n)
听起来挺不错,但是真正想要利用JDK1.8的好处,有一个限制:
key的对象,必须正确的实现了Compare接口
如果没有实现Compare接口,或者实现得不正确(比方说所有Compare方法都返回0)
那JDK1.8的HashMap其实还是慢于JDK1.7的
简单的测试数据如下:
向HashMap中put/get 1w条hashcode相同的对象
JDK1.7: put 0.26s,get 0.55s
JDK1.8(未实现Compare接口):put 0.92s,get 2.1s
但是如果正确的实现了Compare接口,那么JDK1.8中的HashMap的性能有巨大提升,这次put/get 100W条hashcode相同的对象
JDK1.8(正确实现Compare接口,):put/get大概开销都在320ms左右
为什么要这么操作呢?
我认为应该是为了避免Hash Collision DoS攻击
Java中String的hashcode函数的强度很弱,有心人可以很容易的构造出大量hashcode相同的String对象。
如果向服务器一次提交数万个hashcode相同的字符串参数,那么可以很容易的卡死JDK1.7版本的服务器。
但是String正确的实现了Compare接口,因此在JDK1.8版本的服务器上,Hash Collision DoS不会造成不可承受的开销。
参考资料:
jdk1.7.0_80的HashMap源码
jdk1.8.0_66的HashMap源码
部分转载自:http://www.cnblogs.com/stevenczp/p/7028071.html
HashMap 在 Java1.7 与 1.8 中的区别的更多相关文章
- HashMap在Java1.7与1.8中的区别
基于JDK1.7.0_80与JDK1.8.0_66做的分析 JDK1.7中 使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同, ...
- java中 HashMap和Hashtable,list、set和map 的区别
摘自: http://blog.chinaunix.net/uid-7374279-id-2057584.html HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Ma ...
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- 【转】HashMap、TreeMap、Hashtable、HashSet和ConcurrentHashMap区别
转自:http://blog.csdn.net/paincupid/article/details/47746341 一.HashMap和TreeMap区别 1.HashMap是基于散列表实现的,时间 ...
- 集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别
一.HashMap 的原理 1.HashMap简介 简单来讲,HashMap底层是由数组+链表的形式实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表 ...
- js中== 和===中的区别
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- continue语句在for语句和while语句中的区别
while语句的形式: while( expression ) statement for语句的形式: for( expression1; expression2;expression3 ) // ...
- Objective-C声明在头文件和实现文件中的区别
Objective-C声明在头文件和实现文件中的区别 转自codecloud(有整理) 调试程序的时候,突然想到这个问题,百度一下发现有不少这方面的问答,粗略总结一下: 属性写在.h文件中和在.m文件 ...
- 在oracle中where 子句和having子句中的区别
在oracle中where 子句和having子句中的区别 1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用 ...
随机推荐
- windows下使用tftp工具下载文件到开发板(linux)
1.下载tftp工具,也可以上CSDN找个免费0积分的 http://www.52z.com/soft/11886.html 2.确保开发板和windows在同一网段 比如192.168.101.*段 ...
- JavaScript中replace()方法的第二个参数解析
语法 string.replace(searchvalue,newvalue) 参数值 searchvalue 必须.规定子字符串或要替换的模式的 RegExp 对象.请注意,如果该值是一个字符串,则 ...
- Redis总体 概述,安装,方法调用
1 什么是redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset( ...
- 蓝桥杯 方格填数 DFS 全排列 next_permutation用法
如下的10个格子(参看[图1.jpg]) 填入0~9的数字.要求:连续的两个数字不能相邻.(左右.上下.对角都算相邻) 一共有多少种可能的填数方案? 请填写表示方案数目的整数.注意:你提交的应该是一个 ...
- 学号20155308 2016-2017-2 《Java程序设计》第6周学习总结
学号20155308 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 第十章 输入与输出 目的:文件的读写:网络上传数据的基础:同样要掌握父类中方法. 10. ...
- TensorFlow在windows10上的安装与使用(一)
随着近两年tensorflow越来越火,在一台新win10系统上装tensorflow并记录安装过程.华硕最近的 Geforce 940mx的机子. TensorFlow是一个采用数据流图(data ...
- c++刷题(27/100)反转单项链表,链表的倒数第k个
题目1:调整数组顺序使奇数位于偶数前面 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位 ...
- 82.Linux之VMware10.0.4_x64安装
一直想写linux前期软件的一些安装配置的博客,因为中途去弄CORDIC算法了,今天上午刚弄好,除法,乘累加,三角函数等都能达到要求,所以现在来写这块的博客,CORDIC博客就不写了,因为网上很多.V ...
- Oracle 11G R2 RAC中的scan ip 的用途和基本原理【转】
Oracle 11G R2 RAC增加了scan ip功能,在11.2之前,client链接数据库的时候要用vip,假如你的cluster有4个节点,那么客户端的tnsnames.ora中就对应有四个 ...
- Django中HttpRequest和HttpResponse
请求和响应对象 Django中通过使用请求和响应对象来传递系统的状态. 当请求一个页面的时候,Django就创建一个HttpRequest对象,它包含了关于请求的元数据对象,然后Django加载适当的 ...