Confluence备份,数据迁移
一、Confluence的备份、恢复
1)Confluence的备份
管理员账号登录Confluence,点击右上角的"一般配置"-"每日备份管理",如下图(默认配置):

默认每天会自动备份一个zip打包的数据,存放在服务器的/var/atlassian/application-data/confluence/backups路径下。还可以点击"编辑"进行自定义。
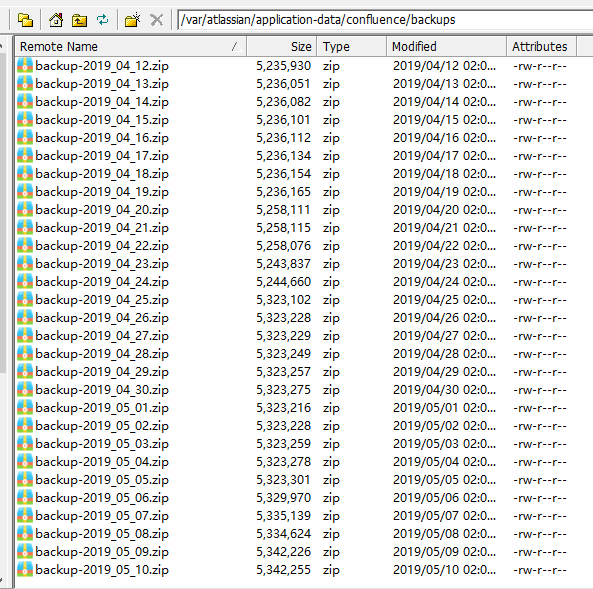
上面这是默认的整个Confluence的备份,默认每天2点左右都会整体备份一次!恢复或迁移的时候,可以直接用这里的zip打包数据进行恢复。除此之外,还可以点击"一般配置"-"备份与还原"里面的备份进行手动备份。
数据备份目录:/var/atlassian/application-data/confluence/backups ("站点管理"->"每日备份管理")
附件所在目录:/var/atlassian/application-data/confluence/attachments 注意附件数据要手动备份,可以写shell脚本定时备份。
除了上面的Confluence整体备份,还可以选择针对某个空间进行手动导出、导入的方式进行备份和恢复,这个一般是在迁移的时候用到。具体做法如下:
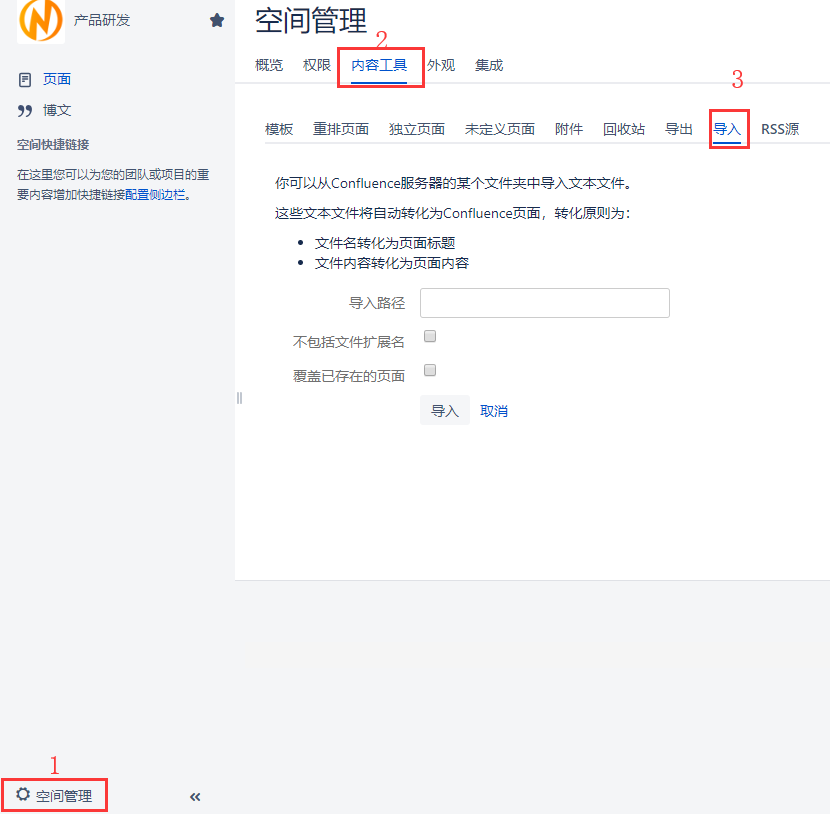
点开某个空间后,依次点击左下角的"空间管理"-"概览"-"内容工具"-"导出"(选择xml格式)

导出的文件一般会放在服务器的/var/atlassian/application-data/confluence/temp/路径下。

2)Confluence的恢复
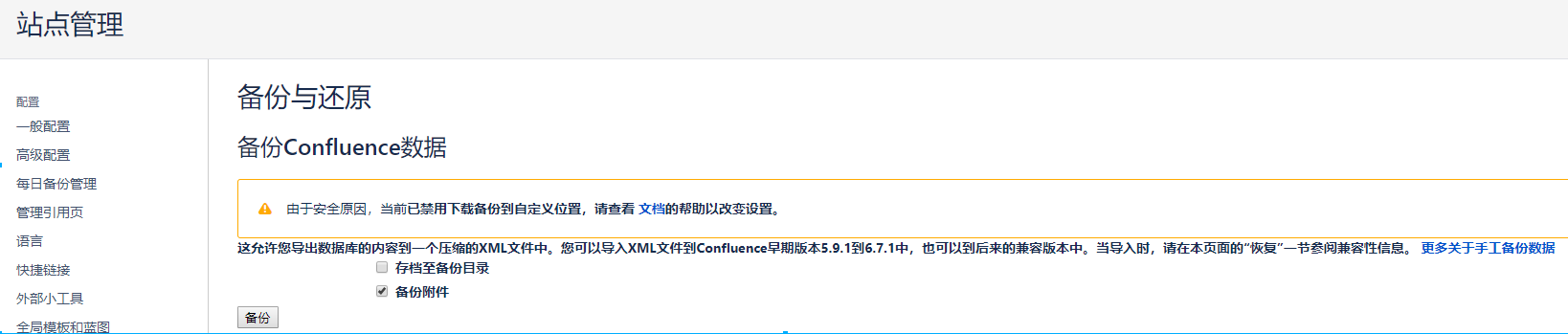
可以点击"一般配置"-"备份与还原"里面的恢复进行数据恢复。可以将上面整体备份在/var/atlassian/application-data/confluence/backups里面的数据然后点击"上传和恢复"即可进行数据恢复。

当备份数据比较大时,可以将备份数据拷贝到/var/atlassian/application-data/confluence/restore路径下,从Confluence主目录中进行恢复。如下:

注意:针对某个空间的备份:
- 如果此空间不存在,则可以如同上面方法恢复数据:即将备份在/var/atlassian/application-data/confluence/temp/里面的数据拿到本地,然后点击"上传和恢复"即可进行数据恢复。
- 如果此空间已存在,则就不能使用上面方法,否则会报错"空间标识DATA已存在,请首先删除该空间,然后继续完成还原"。此种情况下,如果不删除该空间,则正确的数据恢复的方法是:点开该空间,分别点击左下角的"空间管理"-"概览"-"内容工具"-"导入",然后将服务器上备份数据的路径/var/atlassian/application-data/confluence/temp/ 填写到"导入路径",进行导入操作即可。
二、Jira、Confluence迁移/备份
先安装Jira, 后安装Confluence, 用Confluence去主动对接Jira.
首次迁移的时候, 需要注意下面几点:
第一步:
在新服务器上安装Jira环境。
第二步:
将老机器的jira库恢复到新机器的jira库中(新机器的jira库不要删除,在此jira库基础上进行导入)。
在导入老的jira库前, 一定要提前备份新服务器的jira库!
数据导入后,一定要重启Jira服务!然后尝试用老环境的jira用户登录新环境的jira,确保原用户能成功登录新的Jira环境(说明用户导入成功)。
第三步:
将老机器jira的备份数据(包括附件数据)逐个恢复到新机器的Jira环境里。
第四步:
在新服务器上安装Confluence环境,安装过程中,一定要记得对接新的Jira环境!对接后,使用原来的confluence账号应该是能成功登录新的Confluence。因为老账号已经通过jira导入到新环境中.
第五步:
将老机器的Confluence库恢复到新机器的Confluence库里(新机器的Confluence库不要删除,在此Confluence库基础上进行导入即可)。
导入前一定要备份新机器的Confluence库! 导入成功后, 要记得重启Confluence服务。
第六步:
将老Confluence的备份数据(包括附件数据)逐个恢复到新的Confluence环境里(如果整体恢复有错误,可以按照空间的备份数据一个个进行恢复)
需要注意:
如果是备机器, 备机器在第一次安装环境时, 备机器的jira/confluence需要按照上面的步骤跟主机器进行第一次数据同步;
后续过段时间,主机器的jira/confluence陆续又有新账号和新数据产生, 需要再次进行数据同步, 切记:
1) 备份备机器的jira库;
2) 将主机器的jira数据库导出来,并导入到备机器的jira库里(新机器的jira库不要删除,在此jira库基础上进行导入);
3) 数据导入后, 重启备机器的jira服务, 确保使用主机器新增的账号能成功登录备机器的jira环境, 说明用户导入成功;
4) 接着在备机器的confluence环境里, 主动进行跟jira的账号同步! 确保备机器的jira/confluence的账号先成功同步过来!
5) 最后再依次进行主机器jira/confluence应用数据到备机器的同步操作!
账号同步的坑很多, 稍不注意, 就会导致confluence账号登录不上的情况. 所以,后续同步时, 最好只是同步jira/confluence的备份数据;
每次在主机器新建账号的时候, 最好也在备机器创建一次,这样先确保主备环境的账号同步!
原文链接:https://www.cnblogs.com/kevingrace/p/8862531.html
Confluence备份,数据迁移的更多相关文章
- Linux文件系统应用---系统数据备份和迁移(用户角度)
1 前言 首先承诺:对于从Windows系统迁移过来的用户,困扰大家的 “Linux系统下是否可以把系统文件和用户文件分开到C盘和D盘中” 的问题也可以得到完满解决. 之前的文章对Linux的文 ...
- Docker数据卷Volume实现文件共享、数据迁移备份(三)--技术流ken
前言 前面已经写了两篇关于docker的博文了,在工作中有关docker的基本操作已经基本讲解完了.相信现在大家已经能够熟练配置docker以及使用docker来创建镜像以及容器了.本篇博客将会讲解如 ...
- rsync用于数据迁移/备份的几个细节
上周我们的一个GitLab服务频繁出现web页面卡死问题,得重启虚拟机才可恢复,但重启之后没多久又会卡死.后来发现是虚拟机的磁盘大小超过了2T,而虚拟机管理那层的文件系统是ext3,最大单文件只能支持 ...
- 数据迁移_把RAC环境备份的数据,恢复到另一台单机Oracle本地文件系统下
数据迁移_把RAC环境备份的数据,恢复到另一台单机Oracle本地文件系统下 作者:Eric 微信:loveoracle11g 1.创建pfile文件 # su - ora11g # cd $ORAC ...
- mysql 数据备份及数据迁移
一.使用mysql数据导出进行备份时,会备份整个表的数据,有时候只想备份一部分数据,这个时候可以使用如下方法: 1. 使用insert into 和 select结合: insert into tal ...
- LVM+NBD实现VM数据备份和迁移
在云系统的高可用性中,VM层的高可用性尤为关键,其中又涉及到了VM本身数据的备份和迁移的问题.在现有的平台上,每一个VM的数据放在一个单独的LV(逻辑卷)上,VM数据的备份可通过备份其所在的LV来完成 ...
- [Sqlite]-->数据迁移备份--从低版本号3.6.2到高版本号3.8.6
引子: 1. Sqlite在Windows.Linux 和 Mac OS X 上的安装过程 2.嵌入式数据库的安装.建库.建表.更新表结构以及数据导入导出等等具体过程记录 个字段IPHONE和LOGI ...
- velero 备份、迁移 kubernetes 应用以及持久化数据卷
velero 是heptio 团队开源的kubernetes 应用以及持久化数据卷备份以及迁移的解决方案,以前的名字为ark 包含以下特性: 备份集群以及恢复 copy 当前集群的资源到其他集群 复制 ...
- Docker数据卷Volume实现文件共享、数据迁移备份(三)
数据卷volume功能特性 数据卷 是一个可供一个或多个容器使用的特殊目录,实现让容器中的一个目录和宿主机中的一个文件或者目录进行绑定.数据卷 是被设计用来持久化数据的对于数据卷你可以理解为NFS中的 ...
随机推荐
- vs2019编译opencv
序 微软家的宇宙第一ide:visual studio已经更新到了2019版,芒果也更新尝鲜了一遍,体验还不错,建议更新尝尝鲜.芒果顺便使用vs2019编译了一遍opencv,编译过程也非常顺利,以下 ...
- HTTPS原理(三次握手)
第一步: 客户端向服务器发送HTTPS请求,服务器将公钥以证书的形式发送到客户端(服务器端存放私钥和公钥). 第二步: 浏览器生成一串随机数,然后用公钥对随机数和hash签名进行加密,加密后发送给服务 ...
- 用python操作mysql数据库
数据库的安装和连接 PyMySQL的安装 pip install PyMySQL python连接数据库 import pymysql db = pymysql.connect("数据库ip ...
- 如何用纯 CSS 创作一个慧星拖尾效果的 loader 动画
效果预览 在线演示 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/YLRLaM 可交互视频教 ...
- java实现spark常用算子之distinct
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.a ...
- ArcGis之popup列表字段自定义
ArcGis之popup列表字段自定义 featureLayer图层中可以使用popupTemplate属性添加弹窗. API:https://developers.arcgis.com/javasc ...
- Storm项目开发纪要
1.POM引用storm-core和javax.servlet-api这两个组件,如果本地模式跑拓扑,要把<scope>provided</scope>去掉:如果远程发布运行, ...
- Ubuntu中用sudo apt-get install makeinfo时,出错:Unable to locate package
背景: 在准备ARM交叉编译环境时,执行命令: DISTRO=fsl-imx-x11 MACHINE=imx6qsabresd source fsl-setup-release.sh -b build ...
- 00常见的Linux系统版本
linux系统内核与linux发行套件系统并不相同: linux系统内核指的是一个由Linus Torvalds负责维护,提供硬件抽象层.硬盘及文件系统控制及多任务功能的系统核心程序. linux发行 ...
- C++的一些黑暗料理
本文中的“黑暗料理”仅限本人在学习C++的过程中感觉易忘.有趣.不为大多数人所知的一些特性. 1. C++中int型数据在VC++环境下最小值为什么是 -32678,而不是-32677,其中涉及到原码 ...